
网络芯片这个概念,很多人看起来会觉得依稀平常,但其实都误解了,它其实是个大类,不同的领域,不同设备上,不同的应用场景,不同的通信方式,不同的互联协议,以及不同的下游客户,所谓的网络芯片概念都是不同的。但是由于这个概念非常常见且容易理解,以至于很多人甚至专业的投资机构都不觉得它很高精尖。
所以今天从服务器网卡开始,一边讲行业,一边讲技术,把网络芯片彻底聊透。
服务器端:从网卡到DPU的发展历程
一个大型计算机中心,有着各种各样的设备,比如服务器,网络交换机,路由器,它们在行业内统称ICT,即信息,通信和技术三个单词首字母。
它是一个涵盖性术语,覆盖所有通信设备,应用软件等。
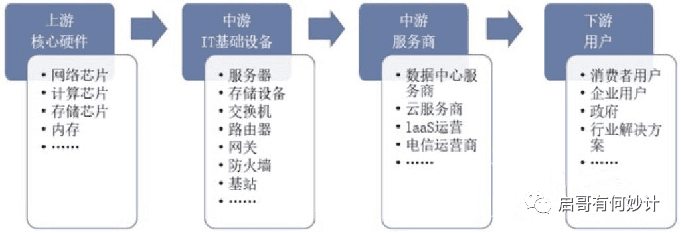
它的上游主要核心硬件就是集成电路行业的各种芯片,包括网络芯片,计算芯片,存储芯片,内存芯片,以及各种配套的电源管理IC,PCB板,电容电感等各种被动件在内的电子元器件。
中游就是IT基础设备,比如服务器,大型存储设备,交换机,路由器,网关,防火墙,基站等,以及围绕这些硬件的设备制造商,比如中科曙光,浪潮信息,还有菲菱科思这种做网络设备代工的公司。
然后下游就是运营管理这些设备的服务商,比如数据中心服务商,云计算服务商,IaaS运营商,电信运营商等。
终端客户都是to G,to B,to C的各类用户,比如电信业,政府,银行,金融业,各种互联网企业,以及消费者等等。
近年来随着我国经济的不断发展及各行业信息化建设推进,我国ICT技术行业市场规模不断扩大。根据数据显示,中国ICT技术市场规模从2017年的4.4万亿元上涨至2022年的5万亿元。同比2021年增长1.21%。
先聊服务器。
服务器上的基本结构其实和个人PC差不多,它由一堆CPU,GPU、GPGPU,推理运算单元,AI运算单元等各种高性能计算芯片,外加一堆外围的如主板北桥芯片,南桥芯片,电源管理IC, 模拟芯片,当然还有重要的外部通信接口,就是由各种网卡芯片组成。
以前服务器用千兆,万兆网卡,随着数据量越大越大,现在高端的都是光模块,从25G到400G不等,未来甚至有800G,1.6T,可见半导体下游应用中,通信细分排第一不是没有道理的,毕竟我们身处信息社会中。
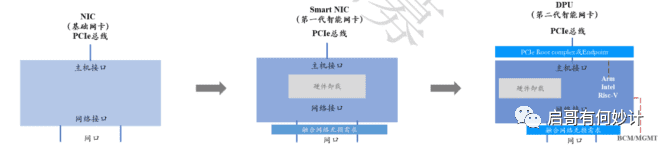
这个网卡,以前叫NIC,即基础网卡,或者叫以太网控制器,网络适配器,它以有线网线和其他网络设备连接,因为价格便宜而且以太网标准普遍存在,应用非常广泛。
在国内这是一个80-100亿市场的规模,并且还以年均增长13.5%左右的增速和国内2000多亿的服务器市场遥相呼应。
随着公有云中虚拟化技术的发展以及软件定义网络(SDN)技术的兴起,对端系统协议栈提出了更高的要求,而传统的高性能网卡已经难以满足这些要求。所以,智能网卡(Smart NIC)技术逐渐发展起来。不同于传统网卡,智能网卡同时具备高性能及可编程的能力,既能处理高速的网络数据流,又能对网卡进行编程,实现定制化的处理逻辑。
和传统网卡相比,智能网卡有了很大的变化。其中硬件中普遍卸载了部分传输层和路由层的处理逻辑,如校验和计算、传输层分片重组等,来减轻CPU的处理负担。甚至有些网卡如RDMA网卡还将整个传输层的处理都卸载到网卡硬件上,以完全解放CPU。得益于这些硬件卸载技术,服务器端系统的网络协议栈处理才能与现有的高速网络相匹配。
不同的加速工作负载,智能网卡又分成基本连接型NIC,面向网路加速型的智能网卡,以及面向存储加速型的智能网卡等。
智能网卡的内部结构方案也五花八门,有多个CPU组合的ASIC,有基于FPGA(可编程门整列)的,或者是FPGA+ASIC的方案。
这个存储加速型的方向我特别看好,后面细聊。
再往下一代就是现在炒得火热的DPU。
DPU,也就是Date Processing Unit ,也就是数据处理器。它和CPU,GPU/GPGPU不同的是,专门针对大型算力中心的网络信息处理进行优化。
在数据中心里,时时刻刻都有大量的数据在进行传输。主机在收发数据时,需要进行海量的网络协议处理。根据传统的计算架构,这些协议处理都是由CPU完成的。
有人统计过,想要线速处理10G(万兆)的网络,需要约4个英特尔志强CPU的核。也就是说,仅仅是进行网络数据包的处理,就要占用个8核CPU的一半满负荷时候的算力。现在数据中心网络不断升级,从10G到40G 、100G,400G,以及未来还有800G,1.6T的网络速率,这些性能开销显然是承受不起的。
把大量宝贵的CPU运算资源浪费在这上面,显然是毫无必要的,所以就有把网络处理协议先从CPU“卸载”到智能网卡上,分担CPU负荷这样的操作。
2015年,云计算厂商AWS就率先使用这种智能网卡,同步他们也收购了Annapurna LABS公司,并于2017年推出Nitro系统。同年阿里云也搞出了类似功能的神龙(X-Dragon)架构。
再然后的故事大家都知道。
2019年3月,英伟达花费69亿美元的巨资收购了以色列芯片公司Mellanox(麦洛斯)。英伟达将Mellanox的ConnectX系列高速网卡技术与自己的已有技术相结合,于2020年正式推出了两款DPU产品:BlueField-2 DPU和BlueField-2X DPU 。
因此2020年也称为DPU元年,之后国内的DPU初创公司如雨后春笋一般冒出来,扎堆DPU领域。
从某种角度上来讲,DPU也可以说是智能网卡的扩展升级版。
DPU在智能网卡的基础上,将存储,安全,虚拟化等工作从CPU上“卸载”然后加载到自己身上,等于把CPU从部分繁重且和计算没关系的工作拆出来,让DPU来处理。
综上所述,DPU 芯片的作用本质,就是卸载、加速和隔离——把CPU的部分工作卸载到自己身上;利用自己的算力特长,对这些工作进行加速运算,整个过程实现了计算的隔离,增加性能,减轻CPU的负荷。
所以有人说DPU也是大型服务器中心的三大U,CPU,GPU/GPGPU,DPU,也对。
下面这个图应该非常清楚了。
到现在为了配合Ai和加速计算而设计的DPU,DPU针对多用户,云生态环境进行各种优化,提供数据中心级的软件定义和硬件加速的网络、存储、安全和管理等各种服务。
到2025年,有专业机构预测这个DPU,有望超过120亿美元的市场空间。
在这个领域,国内国外公司就非常多了,包括英特尔,英伟达(Mellanox),博通,还有微软,亚马逊,Marvell等。当然主要就是英特尔,英伟达,博通这三家。国内目前这类公司也不少。
总的来说,过去服务器都是用普通的千兆,万兆网卡的那就是用NIC网络适配器,俗称网卡芯片。
之后开始升级,出现了智能网卡分担一部分CPU的功能,到现在出现DPU,实现更多功能,至于连接方式,也早不再是网线,而是光纤。
两幅图帮助各位理解:
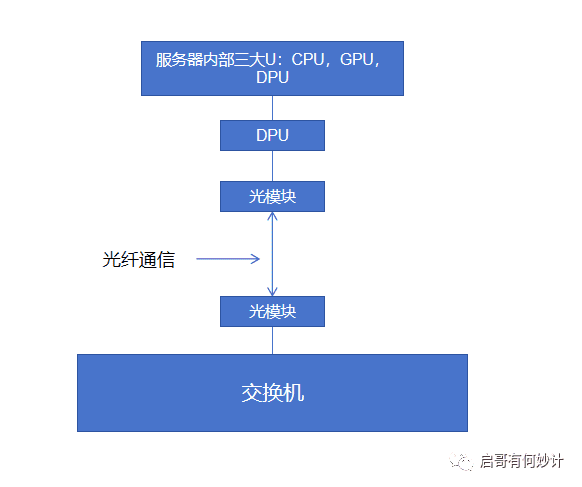
DPU的定位
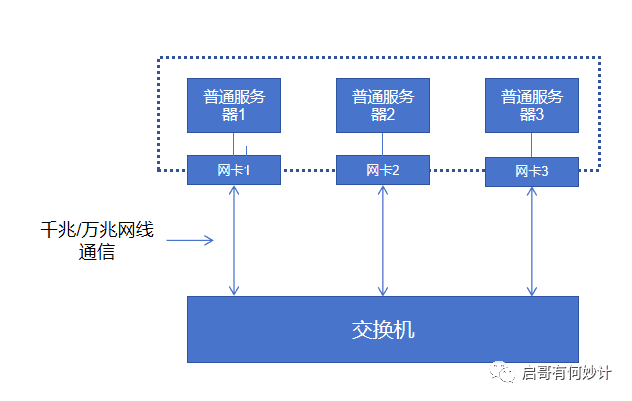
网卡仅仅是承担了网络连接功能
服务器端的网络芯片就讲到这里。
网络设备端:路由,交换与无线设备的心脏
网络设备就是指各种路由器,交换机以及无线设备。
这些设备是整个网络的核心硬件,它通过使用数据包交换来接收数据,转发数据来到计算机网络里指定的设备上。
在整个网络设备,交换机规模排第一,大概占56%,其次是路由器占比为约30%,其余是网络无线设备占比约14%。
在交换机领域,有家大家都非常熟悉的美国公司,思科(Cisco)。
我当年参加过CCNA的认证考试(思科网络工程师的资格认证考试,有初级CCNA,中级CCNP,高级专家CCIE三种),为了敲这篇文章,把我书架上灰都三尺厚的这本书拿出来,再好好地复习了一遍。
交换机领域经过这些年的发展,其实国内外竞争格局非常稳定。
国外就是思科,Arista,HPE惠普这些。其中思科独霸全球市场40%以上;Arista排第二,国内互联网公司也有不少用它的设备,因此国内也有一定的市场份额;HPE惠普主要是服务器市场多,交换机不多,但是由于收购了Aruba Networks(阿鲁巴),在企业级无线领域有一定的占有率。
而国内,华为+新华三+锐捷三两家则占了90%左右的市场份额,其余几家分剩下的那点市场份额。
华为,新华三不说了,国内占主导地位。锐捷以前专注教育网,在医疗网络也比较厉害,现在也往B端客户,如数据中心,服务器中心,互联网企业此类客户去切。此外就是中兴,但是中兴的交换机不是强项,它的强项是无线基站,固定网络通信,家里的FTTH,光纤到家光猫,以及中心汇聚那些。
新华三历史上换过多次大股东,从华为+3COM的合资公司,到惠普,再到紫光,最近紫光股份想收255亿收购剩余的股份但被暂缓。
讲完交换机再讲路由器的格局。
在路由器领域,基本就是思科和华为两家,处于寡头垄断,两家加一起占了60%的份额,其他就是瞻博(Juniper),新华三分剩下的,零零散散还有烽火通信,腾达,TP-LINK(普联)等公司主要是消费级市场,家用为主,在大企业端市场基本没有存在感。
在无线领域,又分两部分,第一是基站侧,传统电信运营商那种就是华为,诺基亚,爱立信,中兴等传统电信设备巨头;第二是Wi-Fi端,包括企业级就是思科,华为,锐捷,中兴,以及收了阿鲁巴的惠普,而消费级就是普联技术,D-LINK,Netgate网件这种,这个太多了按下不表。
随着Ai计算,数据中心,大型服务器的崛起,这个网络硬件领域变得越来越重要,特别是交换机。
9月11日,IDC发布数据显示,2023年第二季度,全球以太网交换机市场收入同比增长38.4%,达到118亿美元,算是一个快速增长的市场。
光大证券发布研究报告称,随着数据流量增长,高带宽业务开展和部署对网络设备要求增多,交换机由集线器(一层交换机)升级为第四代多业务产品,数据中心场景由于东西向流量占据主流叶脊网络架构取代传统三层网络架构,AI大模型训练南北向流量增加,或驱动向“Fat-Tree”架构转变,增加交换机使用数量,交换机在数据中心市场迎来巨大发展空间。
所以从行业发展趋势来看,交换机市场是最大的增量红利。
了解完这个行业大概之后,再来聊聊设备里的芯片。先从交换机的核心心脏——交换机芯片,Switch Chip。
交换机的心脏
以太网交换设备在逻辑层次上遵从 OSI 模型开放式通信系统互联参考模型,包括物理层,数据链路层,网络层,传输层,会话层,表示层,应用层,一共7层。
对,学过网络的小伙伴对这个一定不陌生,这个就是OSI 7层模型。

以前交换机主要工作在物理层、数据链路层这两层上;而路由器则工作在网络层和传输层上。
但是现在交换机和路由器定位也逐渐模糊。现在很多数据中心,如果也不是单纯用几个大型路由器组网,这样成本太高了。现在做交换机设备的公司,会把部分带有路由功能芯片装入交换机里面,比如在思科在自己的交换机里面加上博通的芯片,让交换机具有一定的路由功能,这样客户侧组网的成本会大大降低,特别是那些互联网公司已经不再单纯依赖路由器组网,而是选择使用带有路由功能的交换机组网来降低硬件投入成本。当然,传统电信公司还是走传统路线,该用啥用啥,但是不可否认的是交换机功能越来越强大,市场份额也在扩大。
思科之前收购过一家澳大利亚的FPGA的芯片公司, Exablaze,并把它芯片用于自家交换机上,等于交换机内部带有编程功能,可以在物理层做低延迟,优化过后特别适用于期货,证券交易这类客户,因此在这个领域思科还是很有竞争力的。
以太网交换设备拥有一条高带宽的背部总线和内部交换矩阵,在同一时刻可进行多个端口对之间的数据传输和数据报文处理。
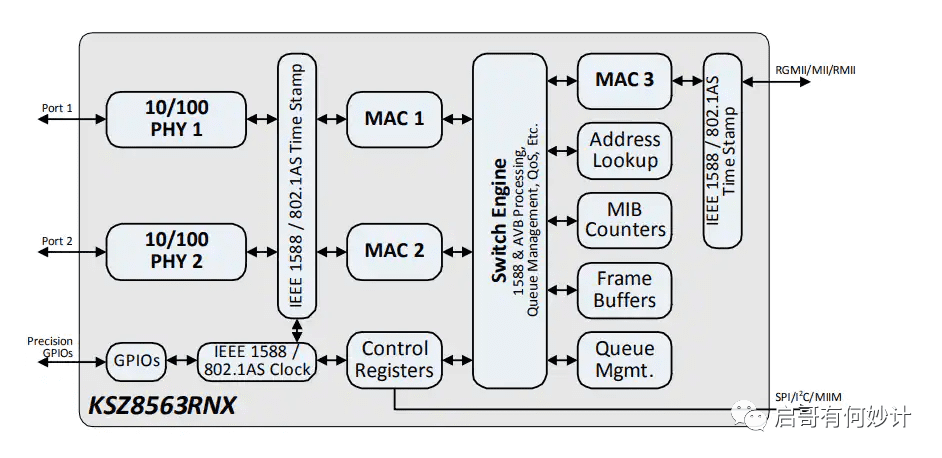
MicroChip KSZ8563RNX的内部结构
为了实现这些功能,一个交换机里包括以太网交换芯片,CPU,PHY芯片,接口/端口等各种芯片和元件组成,当然带高级路由功能的交换机,更复杂,还有带FPGA,路由芯片之类的东西。
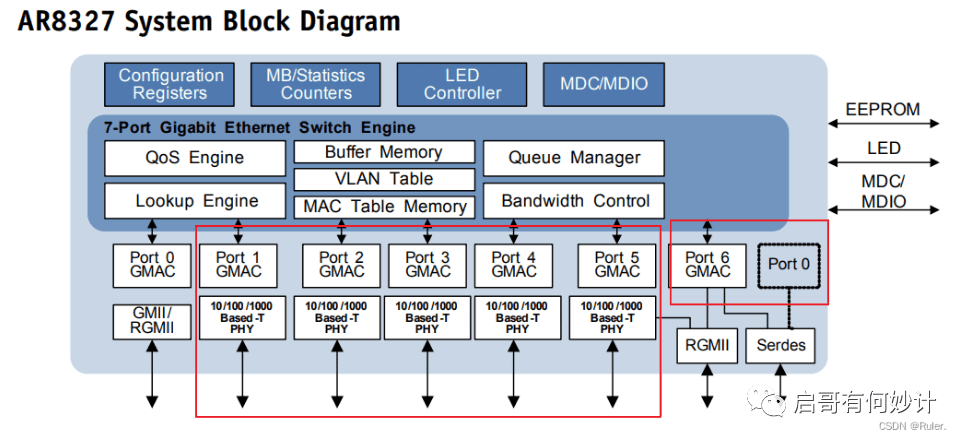
这是一个AR8327的网络交换机芯片,高通的,用来举例。
这上面一共7个端口,其中1-5接了PHY芯片,这些端口只接终端设备;端口0和端口6属于灵活部署,可接PHY,也可以接MAC,这两个端口可以根据开发者需求自己定义,修改CPU可以自定义的端口。
以太网交换芯片为用于交换处理大量数据及报文转发的专用芯片,是针对网络应用优化的专用集成电路。以太网交换芯片内部的逻辑通路由数百个特性集合组成,在协同工作的同时保持极高的数据处理能力,因此其架构实现具有复杂性;CPU是用来管理登录、协议交互的控制的通用芯片;PHY用于处理电接口的物理层数据。也有部分高端产品将CPU、PHY集成在以太网交换芯片内部,形成一颗大核SoC方案。
交换机SoC芯片好坏,直接决定了交换机性能,毕竟核心芯片支持交换机最大能支持多少端口速率,是百兆,还是千兆,万兆,还是25G,100G?性能区别非常大。
其次交换机主要功能是提供子网内的高性能和低延时交换,而高性能交换的功能主要由交换芯片完成。同时由于交换机的部署 节点多、规模大,需要交换机具备更低的功耗、和更低的成本,对交换芯片功耗和成本提出了更高的要求。
就当下而言,由于近几年数字经济的高速发展,推动了云计算,大数据,物联网,人工智能,大型算力中心的发展,这些对网络带宽提出了新的要求,100G以上的以太网交换机芯片增多,400G会成为下一代主流,因此谁能研发出高端的交换机芯片,谁就在未来具有核心竞争力。
这个领域根据不同的客户有不同的商业模式,这个领域交换机分为品牌交换机,裸机交换机,和白盒交换机。
品牌机,就是思科,华为,HPE惠普这类;裸机交换机,主要中国台湾的企业,比如Accton,Quanta QCT,Alpha Networks,Delta这一类ODM公司。
白盒交换机相当于买了裸机交换机和一个操作系统,买回去你自己折腾,这类厂商有Juniper,Arista,锐捷等。
这些厂家中,有些实力强, 核心芯片用的是自研的芯片;有些实力弱,只能用第三方的芯片方案,当然也有根据不同系列高低档次产品,自家的和第三方的搭配使用。
巨头思科、华为等大公司,当然都是自研芯片用于自家交换机上,其他厂商外购第三方厂商以太网交换芯片为主,这些多在白牌上比较常见。
这种商业格局有点类似SSD主控芯片领域。原厂如三星,海力士都有自己的主控芯片,但是也有慧荣,联芸,得一微,英韧,鹏钛,国科微,这种三方的SSD主控方案商,在其他普通品牌上常见,反正各有各的市场和客户群,凭自己本事赚钱。
国内刚刚上市的盛科通信(688702),就是干这个的,属于第三方芯片方案商,卖给类似新华三,锐捷这样的客户。
当然,国内在这个领域除了华为,基本就是弟弟。因为国外有巨无霸博通,此外还有barefoot,这家公司2019年被英特尔收购,还有Innovium,今年8月被Marvell以11亿美元收购了,中低端市场还有“小螃蟹”,Realtek。
因此这个领域占主导的要么就是自研型的思科,华为,要么就是第三方大公司,博通,Marvell,英特尔,国内公司除华为之外目前无论技术实力还是市占率离国外大公司还是有些差距。
交换机里的CPU就没啥好说的,主要就是英特尔和AMD,两家CPU巨头,不过国内目前也在力争上游,有用ARM构架的,RISC-V构架的基于各种构架在开发的各种CPU,还有用FPGA类芯片来满足特定的功能。
然后配套CPU的还有各种存储,包括各种DRAM,以及Nor FLASH之类的东西。
此外就是PHY芯片。
PHY芯片是物理层子系统,它负责将链路层设备(如交换芯片)连接到物理介质(如光纤,或普通网线),并将链路上的模拟信号转化为数字化的以太网帧。
在PHY芯片上,还有端口子系统,端口子系统负责读取端口配置、检测已安装端口的类型、初始化端口以及为端口提供与PHY芯片交互的接口。
说白了,PHY芯片就是一个转换接口芯片,属于数模混合类芯片。懂的都懂,涉及数模转换的都不简单,尽管看起来不起眼,但是要做好还真的挺难。
有人问,网络芯片里最重要的都讲差不多了,炒得火热的光模块在哪里?
简聊光模块
光模块在前文提到的服务器和网络设备上都有,目前高端的光模块从10G开始,25G,100G,400G,800G,以及未来的1.6T都用的是光口通信,而低端的1G(千兆),10G(万兆),多用普通网线口俗称电口通信。
所以现在电口和光口,可谓泾渭分明,电口也就是普通网络口,普通网络,PC,小企业,消费级用户;大型计算机中心,云计算中心,服务器中心,电信级运营商,都是用光口,也就是光模块通信。
说起光模块,我相信很多小伙伴都纷纷表示,这个我熟。
毕竟上半年A股光模块的主线,高潮迭起,相信各位赚到盆满钵满。
我就简单说几句。
光模块和前面提到的普通网线口其实基本功能差不多,但是速度快很多,主要用于大型服务器中心的数据交互,它也是工作在OSI的物理层上。
光模块里最重要的就是光发射和光接收芯片,此外还有各种无源被动件,放大器,驱动,CDR,调制解调等等。
在光发射由于使用的发光芯片不同,又分为比如半导体激光器LD,发光二极管LED,还有垂直腔体发射的VCSEL,甚至还有法布里FP,分布式反馈激光器DFB,电吸收调制激光器EML等等。
发射类型又分边射型(EEL)和VCSEL垂直发射型。
接收端,主要是就是PIN结型二极管 ,以及APD雪崩二极管这种光探测芯片。
在光发射芯片材料,基本都是磷化铟(InP),砷化镓(GaAs),甚至还有氮化镓(GaN)等,主要是由3-5族的化合物半导体材料制造。
而光接收,也就是光的探测芯片,基本都是磷化铟这种材料做的。
这下小伙伴们应该知道磷化铟和砷化镓,以及氮化镓在光模块里是干嘛的了吧,当时炒云南锗业,就是讲这个故事。
整个过程就是发射端的光芯片,发射响应速率的调制过的光信号,通过光纤传输后到光接收芯片,然后由光接收探测到之后转化为电信号,再经过前置发大器,属于响应码率的电信号。
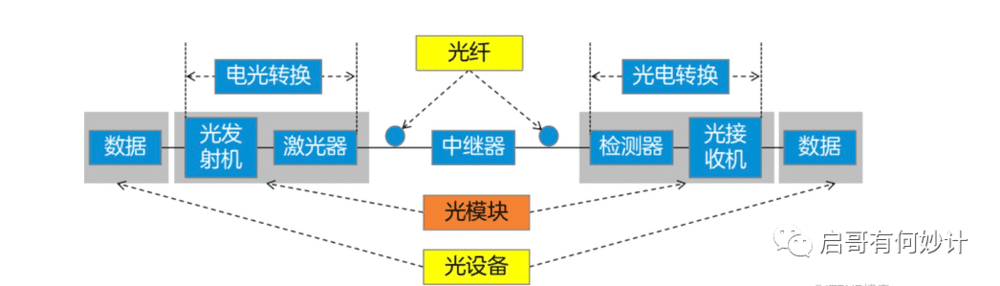
由于光有不同的波长,在实际应用中,一般以850nm(多模),1310nm(单模),1550nm(单模),三种波长的较为常见,这和光在光纤传播的损耗有密切关系,故业内多用这三种损耗小波长的光。
损耗越小,光纤的传输距离就越远,光信号的质量就越好。
在光传输的前后,还有CDR(时钟恢复),调制解调部分,放大器,驱动部分等各种芯片,它们负责光电信号的互相转换,即从电信号到光信号,然后再从光信号到电信号。
很不幸,这部分芯片全是德仪,ADI,Lumentum,美信,Marvell,瑞萨,博通之类的大公司,国内水平连弟弟都算不上。
因为这属于最高端的模拟电路,国内没有特别出彩的公司。
然后为了组成100G,400G,甚至800G的带宽。业内会有各种各种的光路多通道的组合方案,比如25*4=100G,或者100G*4=400G,这种这里就涉及光的拆分和复合的技术了。
牛x的都是多路复合光路,这样在同样的光纤上传输的信息就更多,速率也就更快,带宽更大。
那有人问,国内的光模块公司有什么芯片是自己的?难道只是一个组装方案商?
对,从严格意义上来讲,国内这些个光模块公司,它们仅仅是一个光模块封装方案商罢了。
因为光发射/接收以及光电转换,各种驱动,以及CDR,调制解调器,放大器之类的芯片都不是自己的。
当然了, 也不是说封装不重要,现在光模块的封装方案,发展实在太快了,看得我眼花缭乱。
包括远古时期的GBIC,XENPAK,后面的XFP,SFP,SFP+,SFP28,QSFP,QSFP28,CFP,CFP2,QSFP-DD,OSFP等等,大大小小几十种,连我也搞不清楚其中的区别。只知道不同的封装方案,适用不同的速率,有些支持1.25Gbps,有些支持25Gbps,10Gbps,有些是50Gbps。
然后还对应不同的传输距离,包括100米到160公里不等。
然后调制解调格式,也是五花八门,包括NRZ,PAM4,DP-QPSK;接口工作方式也分双向的Depluxh和单向的BiDi。
总之各位记住,光发射,光接收,以及光电转换和驱动这些个芯片领域,国内和国外比还有一定距离。
但是不管怎么说,这些公司的业绩增长也是实打实的,属于一个高增长的市场,今年上半年光模块概念炒得火热,也确实有基本面逻辑。
讲到这里,网络芯片相关概念大家应该都有一个清晰的认识了。
我再帮各位总结一下。
在服务器端上,所谓网络芯片是指网卡芯片从以前的普通的以太网控制器NIC, 开始向Smart NIC智能网卡,甚至DPU方向发展,核心逻辑是把部分浪费CPU算力资源的工作,从CPU的转移到智能网卡和DPU上,好刚用在刀刃上的思路。
在网络交换机上所谓的网络芯片,是指内部核心的交换机核心,以及配套的电口PHY芯片,以及光口,光模块相关芯片。
所以网络芯片其实是个很宽泛的概念。
讲完这些,回到各位最热切关注的DPU上。
打破冯·诺依曼构架?存算分离?
现代计算机的构架分成,控制器、运算器,存储器(寄存器),输入和输出系统,五个系统。
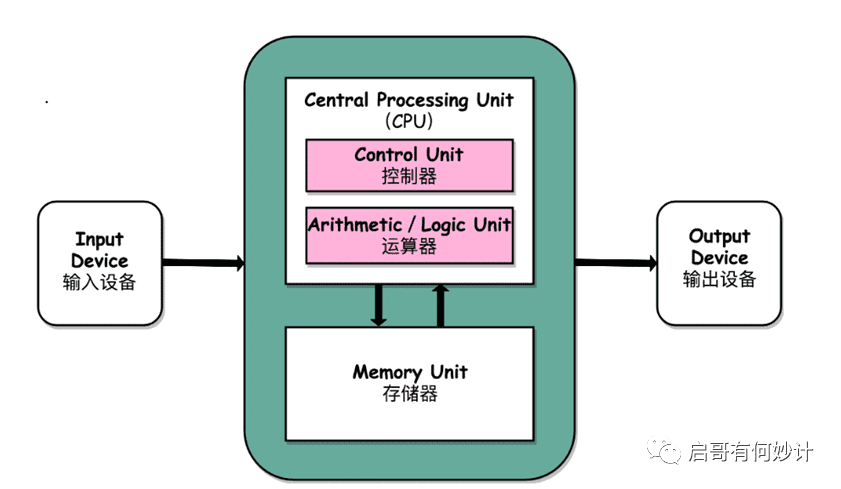
这就是冯·诺依曼的计算机体系结构,相信各位学计算机的小伙伴并不陌生。
和当年第一台电子计算机的“埃尼亚克”号相比,现代计算机性能有着巨大的提升,但是基本构架都是一样的,几十年过去了并没有改变。
但是发展至今,各种问题都来了,且听我仔细分析。
还是从存储角度入手,现在最大的系统瓶颈出现在存算上。
现在有两个存算概念,一个叫存算一体,一个叫存算分离。
有人说,你这不是上海宛平南路600号么,突出一个精神分裂,自相矛盾?
别急,听我讲。存储方面又分:内存和外存。
所谓内存,狭义上理解成内存条,它类似一个临时仓库,速度很快,但是断电不保存数据,也叫易失性,实际广义上的内存包括了内存条DRAM,以及SoC芯片内部的SRAM缓存区域,俗称L1级缓存,L2级缓存等。(一级放地址,二级放数据)。
实际上SRAM区域在一颗CPU内部占的面积是非常大的,比计算单元面积大多了。
外存,就是过去的机械硬盘,当然现在机械硬盘都不用了,改用NAND FLASH颗粒做成固态硬盘来永久保存数据,它能在断电情况下永久保存数据,因此叫非易性存储。
外存从严格意义上来讲,并不属于冯·诺依曼构架存储器,而是属于输入输出的外存。
尽管内存条的速度对于硬盘来讲快很多,但是对于CPU内部的速度而言还是太慢了,而且大量的能耗浪费在进进出出的数据搬运上。
在冯·诺伊曼架构之下,芯片的存储、计算区域是分离的。计算时,数据需要在两个区域之间来回搬运,而随着神经网络模型层数、规模以及数据处理量的不断增长,数据已经面临“跑不过来”的境况,成为高效能计算性能和功耗的瓶颈,也就是业内俗称的“存储墙”。
存储墙,能耗墙,编译墙,“三堵墙”导致算力无谓地浪费:据统计,在大算力的AI应用中,数据搬运操作消耗90%的时间和功耗,数据搬运的功耗是运算的650倍,打破“存储墙”势在必行。
因此当下解决方案是在CPU外挂HBM,拉近计算和存储之间的距离,用异构架的思路来打破“存储墙”,也就是Chiplet的解决思路。
对,直接把CPU/GPU和HBM高宽带内存封装到一起,进一步提升系统速度,毕竟插主板上的速度和在芯片内部封装到一起的相比,速度差了成千上万倍。
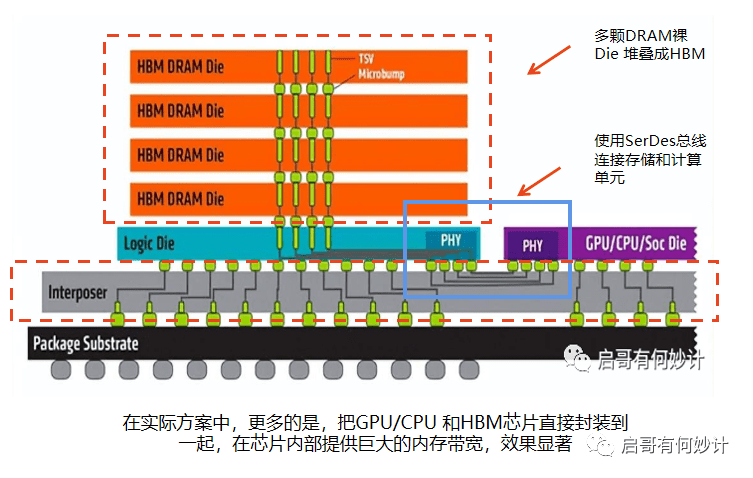
这就是存算一体。
再来聊存算分离。
一般来讲,在主板上以前有北桥芯片和南桥芯片之分,北桥芯片负责CPU和内存条之间的通信,当然了现在CPU都和HBM封到了一起了,CPU内部都有内存控制器直连了,北桥当然不需要了。
南桥芯片负责各种输入输出设备的接口,这其中包括硬盘和CPU之间的通信。
那么有没有一种可能,现在CPU和内存都在一起了,系统瓶颈是不是转移到硬盘和CPU之间了?
有没有办法把最后的一道系统瓶颈给打破?比如别用南桥芯片了,直接学CPU+HBM的方案算了,直接用一条高速总线,把硬盘和CPU直连得了。
这样其中一块服务器的主板上,就只要一个个高性能计算单元,而另外一块服务器上,只插各种硬盘,然后用高速光模块,把计算服务器和存储服务器连接在一起?最大程度节省资源?
这样不仅能省服务器的硬件成本,而且还能提供更快的连接带宽?
前面提到过,DPU中有一项重要功能:
“不同的加速工作负载,又分成基本连接型NIC,面向网路加速型的智能网卡,以及面向存储加速型的智能网卡。”
“到现在为了配合Ai和加速计算而设计的DPU,DPU针对多用户,云生态环境进行各种优化,提供数据中心级的软件定义和硬件加速的网络、存储、安全和管理等各种服务。”
对,非常的棒,如果这个方案可以试试,那可以把DPU功能再升级一下,进一步分摊CPU的工作,用一条高速通信的总线+光模块的方案把两个不同功能的服务器连接到一起,打破系统瓶颈,进一步提升性能。
因此在DPU的1.0功能时代,DPU也就分担了CPU网络通信功能,但是到2.0时代,DPU还能分担存储分离后数据预处理的功能。个人认为这才是未来DPU发展的重要方向,是不是非常哇噻?
这么一看,三大U里的DPU在未来分量真的非常重要,各位DPU初创公司是不是又有新的故事可以讲给投资人听了?
洋洋洒洒敲了11000多字,今日科普到此,希望各位看官老爷看完都有所收获。
参考资料:
生成式AI带火的不止GPU,网络芯片迎来下一轮大战;
核心Switch/PHY 芯片加持,千兆以太网持续放量;
中金 | 交换芯片:下游应用驱动规模及性能双升,长期受益国产替代;
中国路由器行业市场高度集中,前三企业占据接近90%的市场份额;
866.5亿,全球以太网交换机市场排名;
数据中心交换机芯片总结;
以太网交换设备及芯片行业发展概况;
光模块芯片方案浅析;
路由器市场格局;
中国交换机行业前景分析;
计算机冯诺依曼构架结构;
2023全球计算机市场网络设备制造规模及竞争格局;
本文来自微信公众号:启哥有何妙计(ID:qgyhmj),作者:陈启