
在《开源大模型LLaMA 2会扮演类似Android的角色么?》中我们提到过,AlphaGo基于数据飞轮,达到了人工智能一个现在还后无来者的高度,它用自己生成的数据训练自己,迅速达到围棋领域高点,远超人类。
但实际上用数据飞轮来形容这个过程有点以偏概全,数据飞轮是智能飞轮的一个部分。我有个做人工智能算法的朋友经常把自己的工作形容为大号炼丹师,按照这个类比智能飞轮是什么呢?基本上是九转金丹的方子(算法)、炉子(算力)和材料(数据飞轮)的综合。拿到了大概率炼出九转金丹,而吃了后基本立刻成仙。那智能飞轮到底是什么,有哪些关键影响要素,什么样的领域更可能出现新的智能飞轮呢?
智能飞轮
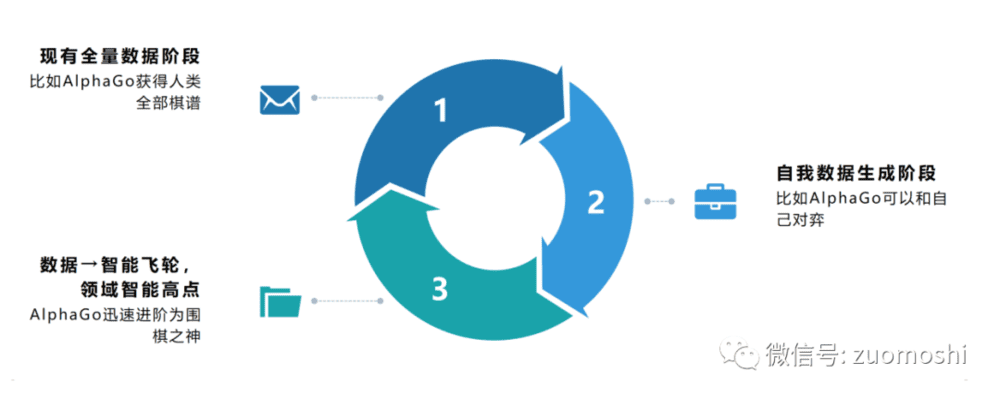
(AlphaGo的数据飞轮)
纯粹从技术角度看,智能飞轮和经常说的算力、算法、数据三要素相关。(比技术更关键的是场域,参见《到底什么是OpenAI成功的关键点,到底谁能干好大模型?》,这里不重复了。)算力基本上依赖于资本,算法依赖于团队,数据就复杂些,不单是有钱就行的。
从智能飞轮的视角来看,算力确实是炼丹炉,算法决定了这个轮子多大或者说到底是个什么样的轮子,数据飞轮则决定了智能飞轮转不转得起来。比如AlphaGo转起来了,但局限于围棋;chatGPT还没转起来,如果转起来,世界整个会被转进去,因为它这个轮子太大了,涵盖了世界太多方面的内容。
算力算法和过去其它商业场景其实类似,人工智能与其它不同的核心就在于数据。坏消息是数据因为生产和消费的失衡而潜在的很快会枯竭。
把模型训练看成消费端,把人和物的所有行为看成生产端,那消耗的速度显然大于生成的速度。几十年积累的数据可以在几次训练中被消耗掉。
而数据的生成并不像想的那么容易。
有效数据从哪里来?
并不是所有的数据都对模型有用。比如我们训练小爱同学这样的唤醒词时,如果你有海量数据但都是铁岭人的,那不管数据多到什么程度,训练结果到了广东都肯定不好使。
所以数据首先要有效,其次才是海量。
对于人工智能语境里的数据,用玄学和哲学一点的视角可能更容易抓到关键。
假设我们有一个“元真”世界,元真世界里面只有本质,比如圆的规律周长、面积、原点等的关系这类,而我们真实的世界其实是本质的各种表现(希腊先哲管这个叫:苍白摹本)。
现在大模型是通过海量的现实数据反向逼近本质和元真世界,那这个时候获取的现实表达种类越全,那无疑逼近的距离就越近。比如爬行动物种类给的越多,每个种类下给的特征越丰富,模型就越能找到爬行动物本质的部分并囊括它。只给一条鳄鱼或者全给鳄鱼就很难逼近到爬行动物的这个本质。

挑战是大多时候我们并不知道哪个是爬行动物
这是智能飞轮中最大的挑战,可以花钱把过往的数据整理出来都给模型,问题是然后呢?
对于上面爬行动物的例子,后续的增量大多还是鳄鱼的话,那和过去就是重叠的,重叠的对于逼近本质帮助就很小,帮助很小智能就不会提升,自然也就没有智能飞轮。(老给鳄鱼会导致不像鳄鱼就不是爬行动物这类结果)
算法不解决这个问题。
有新算法更可能是放大轮子的大小或者构造,对飞不飞得起来帮助不大。对构建出更好的应用帮助倒是很大。
那到哪里能找到这种对逼近本质和元真有帮助的多样化的数据呢?
现在看只有两种方法:一种方法是加大采集范围和力度,也就是说等着真实世界生产,但拿得更全;一种则是自生成。让人工智能生成的数据可以辅助人工智能的进化。前者对应多模态,后者则首先是领域本身的特质。
多模态解决问题么?
2010年前后开始的人工智能浪潮是从多模态开始的,虽然不同创业者往往从不同的维度开始,但最大的两个分支:视觉和语音依赖的正是声光电热力磁几个关键感知维度中的声和光。需要补充一点的是:声不单是常见的识别,还包括声纹、噪声检测、故障检测等,光也不单包括人脸识别,还可以用红外线来检查物品质量、问题,深度摄像头来做三维场景的感知等。
传感器的低成本和精度提升是多模态的基础。
多模态肯定能解决数据上量的问题,质的问题则不太行。
量上只要一定量的摄像头就可以每天获取大量信息。
但质上面因为你部署多少维度的传感器就有多少维度的信息,真要获取这些信息,纯粹依赖自己就需要慢慢部署累积;依赖合作则更困难,因为数据交易流转本身困难重重,所有权、使用权并不清楚。所以多模态在长时间轴上能帮助缓慢解决问题,但注定需要非常大的成本和时间,没可能辅助启动智能飞轮。
这很像一个大排气量的汽车配了个小的供油管,怎么使劲给油也是不够。
数据能够自生成么?
数据自生成有个悖论。
如果元真和本质配合着全量的规则,做数据的生成,那对本质的表达是充分的,这样你生成的数据是多样且有意义的,肯定有助于智能飞轮。但如果规则是局部的,那就会生成大量重复数据,这些数据都在原来的范畴里面等于垃圾数据。从他们也只会回到部分规则和本质。
这时候问题的关键变成到那里寻找一种随机性,并且这种随机性的结果,在领域或特定的范围里是真实的。你创造了一些爬行动物的数据,那得和蛇或者其它的什么一样,恐龙都行,否则就构成对爬行动物这个概念的污染。
从这个角度看大模型的幻觉是有益的,它提供了原始的可能。但这类幻觉有助于构建一个虚拟的世界,对现实问题则不行。如果任由它幻觉下去倒是可能有个智能飞轮,但没人知道它会飞到哪里去了。
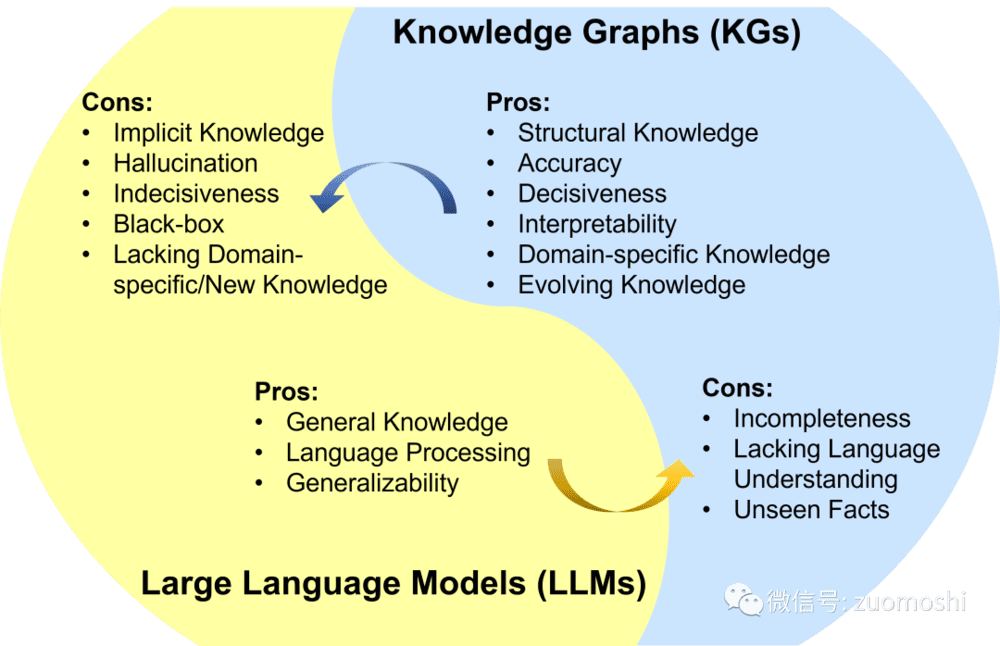
(这个幻觉缺点在数据生成场合可能并不是真的缺点)来自https://www.arxiv-vanity.com/papers/2306.08302/
那AlphaGo为什么行?
因为AlphaGo正好规则是清晰的,只要符合围棋规则的任何尝试都是真实的一部分。这时候“幻觉”反倒是有助于穷尽可能性。
从这里我们可以总结出数据自生成的关键:“幻觉”+规则。为了达成目标,最终当然还有目标上的反馈,比如成败。幻觉加规则能够进行快速的产出,在结果上能够快速反馈,这对于数据生成会非常关键。
下个AlphaGo在哪儿?
那还有什么领域符合这种特征,能够像AlphaGo一样启动智能飞轮么?
从前面的描述我们可以发现,这种领域的特征是前置的,反倒是和算法、数据现状关联不大。符合这种特征就意味着更可能快速炼出九转金丹。
游戏之外我马上能想到的是编程。
编译器等确保了编程的规则足够清楚,差一点都不行;
在很多场景下可以用测试驱动开发的方法定义最终结果对不对;
过往数据量也足够点燃第一把火。性能、稳定性等非功能性指标也都可以很量化地进行度量。
编程的难处在于新领域来的时候,要能把这种需求模糊性描述成一种可度量的数字型的目标。这样软件的产品就会变成对错清楚的一种系统,在这种情况下内部的各种构建可以让模型完成。
如果这是真的,那么程序员这个行业一定会面临巨大变化。
不是说消灭这个职业,而是说工作的内涵会和过往很不一样。
医疗是什么情况,虽然琢磨事这个号的读者很多会关注这个领域,但很不幸医疗不是有智能飞轮的领域,需要的是靠算法等进步一点点地推着往前走。(不是说AI对它没帮助,没机会,沃森类系统一定会出来)
因为病本身就不怎么清楚,“幻觉”和规则也就没法产生有效数据,如果基于这样的模拟数据来做模型,然后去指导给真人看病,再在反馈中修正,这怎么想也不靠谱。反馈代价也太高,没准人类都死光了还不够它验证幻觉的。
企业运营管理是什么情形?这反倒是部分可以。
这好像有点矛盾,理论上医院也是一种企业,为什么医院不行,企业就行?
因为企业内在差别很大,既有封闭系统,又有开放复杂系统。
企业里的场景和任务,其实是在封闭和开放之间连续的,比如总是既有外卖小哥这类工作,也有CEO的工作,前者就封闭后者就开放。然后不同的企业里不同类型的工作配比不一样,比如工厂里或者清洁公司就封闭度高,大学可能就开放度高。
这种配比决定组织的性质。
这就导致在很多贴近封闭场景的场合其实可以找到最优解,关键是边界要切清楚。切到极端其实和围棋是一样的,比如即使不用大模型物流怎么配送最优也可以用算法求解(求解器),因为它边界清晰。
最后想说的是反身性明显的领域,会比较困难,比如股票交易。理论上讲股票和游戏很像,数据非常充分,数据的获取也不困难,幻觉于规则对应的结果马上也有反馈。但股票市场的反身性太明显,这导致它近乎没有规则。这种情况下,AlphaGo这个意义上的智能飞轮转起来也没用,需要另外的视角和方法。
小结
结论是智能飞轮存在与否是个领域特质,和算力、算法关联不大。领域不对,就没数据飞轮,没数据飞轮的时候适合打呆仗,结合多模态逐步累积。这也就意味着在我们说的系统型超级应用对应的长尾曲线里面有智能飞轮效应的会跑在前面。
对于纯粹大模型的研发者,它们负责引领;对于系统型超级应用的开发方核心是寻找到有智能飞轮的领域并据此调配策略;对于长尾曲线上的应用,更适合的是快速产出体验。AI未来的格局倒是越来越清楚了。
本文来自微信公众号:琢磨事(ID:zuomoshi),作者:老李话一三