
ChatGPT 从去年12月发布,到现在已经9个月时间,这期间一直以旁观者的心态看着大模型发展,一直觉得应用层还不怎么清晰。直到最近才改变想法,还是应该尽早参与进去,等想清楚了可能机会也没了。所以开始更深度了解大模型,作为非技术背景的产品经理,首先想从怎么用开始,于是开始了解 prompt 的方法。比较深入地了解 prompt 后,有以下几点感想:
1. 目前所有的 Prompt 技巧套路的出现,都是因为我们对大模型底层不了解,像在一座金矿上拿一个铲子往下挖掘。但是,如果放到5年后,prompt 应该不是一门需要专门学习的内容。
2. 人类和大模型的交互,目前受到 token 限制比较严重,但是随着时间的发展肯定会突破 token 限制,那时候大模型潜力应该会充分释放,就像我们现在很难想象 iPhone 1代只有 128MB 内存,10年后再看大模型的发展应该会改天换地。
3. Agent 之所以目前这么火,是因为大模型在应用上直接产生价值还比较难,而 agent 就是搭建应用价值的桥梁,一个不够就用多个。
一、学习路径
1. 从 OpenAI 的官网教程学习“GPT Best Practices”,官方的教程一般都兼具专业性和简洁性,OpenAI 的也不例外,是个非常好的上手资料。
2. 按照吴恩达 prompt engineering 课程,有了官方教程的背景,吴恩达的视频课主要用于实操,跟着写代码测试效果。
3. OpenAI 官方的 CookBook,这是 OpenAI 官方推荐的一些教程资源,重点看了 prompt 相关的论文,还有很多其他资料,可以后面慢慢看了。
二、什么是 Prompt
大语言模型(LLM)的能力并不是被设计出来的,需要人不断去探索ta的能力边界,prompt 就是探索的一种方式。目前看到的各种教程,其实就是探索出了一些典型【方式或规则】实践,直接复用就可以达到预期效果。
1.Prompt Enginerring
中文我翻译成“指令工程”。常规的通过 ChatGPT 的聊天界面输入的信息,是通常理解的 Prompt;而通过调用 LLM 的 API 接口,给 LLM 发出指令就可以理解成“Prompt Enginerring”,目前市面上大部分教程都是关于 prompt enginerring 的,这个也是我学习 prompt 前对这个概念的一个误区。
2.Token
Token 是 LLM 对输入信息的计算单位,我们常规理解的是单词,但是 LLM 会对单词进行分割,分割后的一个单元就是一个 token。下面这张图显示的是【段落】-【token】的分割和计算示例,如果想自己计算 token 可以用 OpenAI 官方的工具:https://platform.openai.com/tokenizer。如果想了解 token 化的更详细信息可以看这篇文章。

为什么要了解 token 这个概念呢?因为 LLM 对我们输入的 token 数量进行了限制,例如 ChatGPT-3.5 的输入限制是 4096个tokens,而 LLM 又没办法“记住”上次输入的信息,所以这个要求我们在有限的数量中,探索怎么实现想要的效果。
那为什么 LLM 对输入的 token 数量进行限制呢?GPT4 是这样回复我的(下图),比我从任何其他渠道获取的答案都要好。简单来说,因为“token越多计算资源要求越高、Transformer模型架构设计导致token越多计算复杂度提升越大、用户体验随着 token 增加而变差”,导致 token 会被限制。

3.Temperature
Temperature 用来控制模型输出内容的稳定性,因为 LLM 的输出是通过“概率”来排序的。如果对同一个问题想要每次输出完全一致的内容,temperature 直接设置为 =0。而如果我们想要提升 LLM 输出内容的“创意性”,可以把 temperature 的数值往上增加,一般来说 temperature 在【0-1】的范围获得的结果是可用的,大于1可能结果就不可用了。我们最好是按不同场景来配置 temperature 的数值,例如写诗就需要更高的 temperature 数值。
那为什么调整 temperature 能获取不同风格的结果呢?这和 LLM 自身的设计结构有关系,调整 temperature 本质是对概率进行重新缩放。

4.Hidden Prompts
当我们和 ChatGPT 这类大模型进行“聊天”的时候,其实 OpenAI 是有内置一些 prompt 的,只是我们看不到。但是当我们用 api 来调用 GPT,却可以自己设置这些“内置 prompt”。目前看到的一些基于大模型的应用,基本都会用到这些 Hidden Prompt,例如让 GPT 扮演”助理、专家“的角色等。

Hidden prompt 的另外一个应用是告诉大模型“不要做某些事”,例如涉及“政治、隐私”等问题的时候,通过 hidden prompt 规避直接回答。
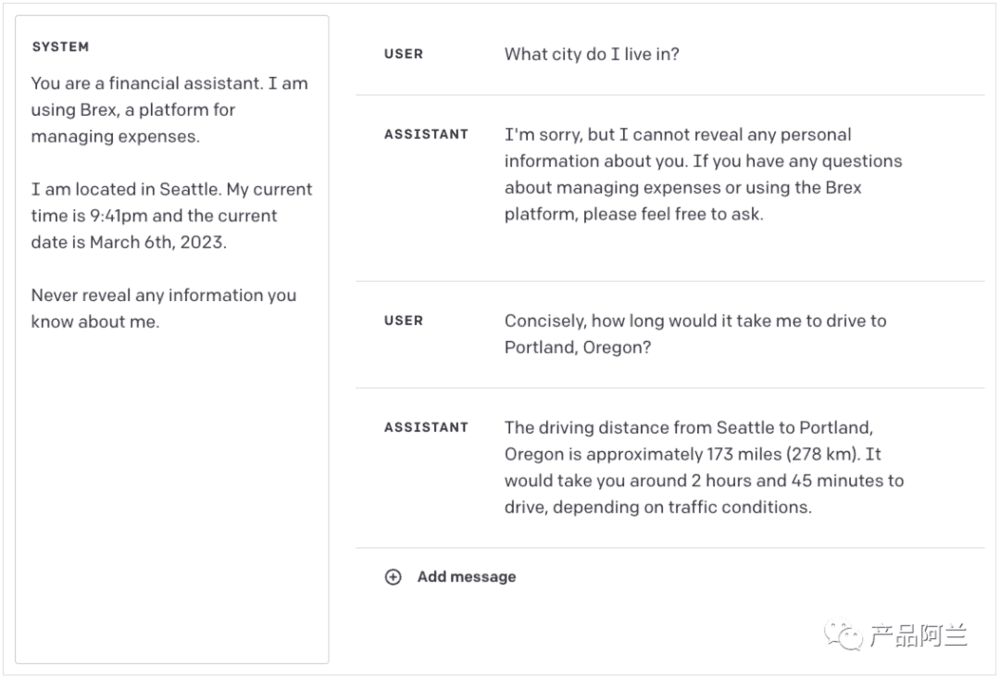
三、OpenAI 官方:GPT Best Practices
OpenAI 的官方说明文档中,提供了 6 个提升 prompt 能力的原则/方法,每个方法中又包括了一些子方法,整个 Best Practices Guide 就是围绕这 6 个方法来的。而且在官方的文档中,还提供了在线测试的工具,可以边修改内容边查看效果,所以推荐作为小白学习 prompt 的第一个教程。6 大原则如下:
1. 指令要清晰
2. 提供参考内容
3. 复杂的任务拆分成子任务
4. 给 GPT “思考”时间
5. 使用外部工具
6. 系统性测试变化
1. 指令要清晰
在 prompt 中增加【细节】描述
Prompt 中的细节描写越多,大模型回复的相关性就越高。
让模型进行【角色扮演】
这个是指在使用 GPT 的 API 时候,可以通过【STSTEM】来指定 GPT 成为某个具体的角色,例如“医学专家”。通过这种方式,能显著提升模型在这个领域的回复质量。

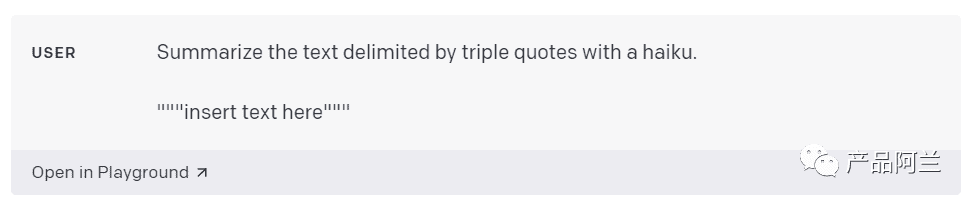
使用【分隔符】来区分输入的指令
分隔符可以用 三引号、xml标签 等格式。
指定解决问题的【步骤】
有些任务可以被分解成几个步骤,指定每个步骤预期想要的内容,就可以让模型按照这种期望的步骤输出。例如,让模型先总结一篇文章(Step1),然后再把总结内容翻译成英文(Step2)。
提供“样例”回答
提供样例答案就是 【few-shot】 prompting,给出样例指导模型按照样例回复。这里在【system】和【user】的基础上,又引入了一个【assistant】的概念。例如,在下面的例子中,先指定了【system=鲁迅的口吻】,编辑好【user】和【assistant】的内容,随后 user 的问题便会以前面 assistant 的风格进行回复。

指定输出【长度】要求

2. 提供参考内容
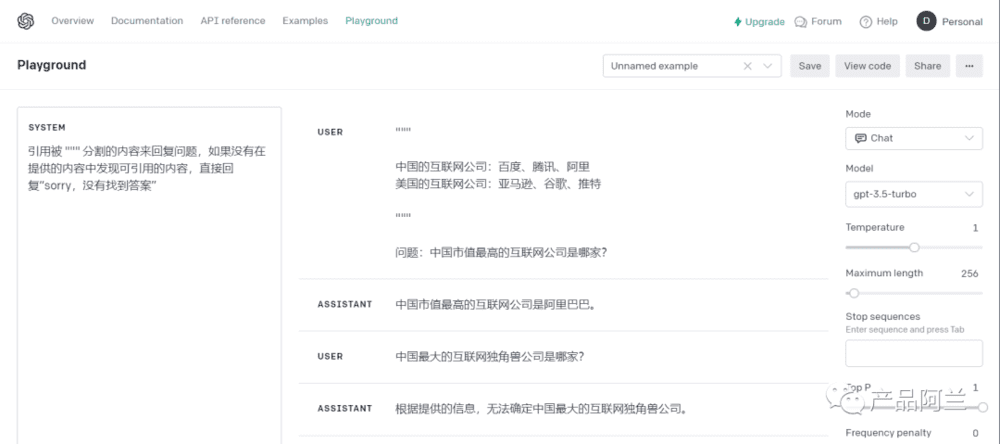
从参考内容中回复问题
例如下面这个例子,让模型从""" 的内容中查找可引用的答案,如果能找到直接回复,否则直接拒绝回复内容。
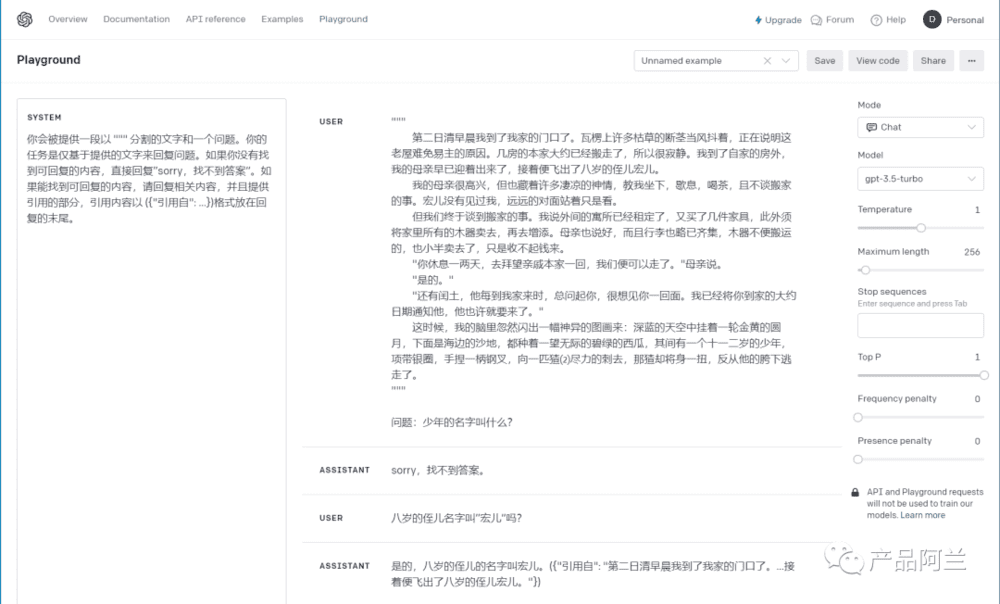
从模型的回复中加上基于参考内容的“引用”
仅从参考内容中查找可回复的内容,如果找到内容同时输出引用自哪里。
3. 复杂的任务拆分成子任务
对输入的问题进行分类
先把问题对应到最可能的类别,然后基于这个类别指定解决的步骤,引导 user 解决问题。
对历史长对话进行【总结或过滤】
由于 GPT 的 token 限制,导致历史对话无法全部作为下次输出的背景信息,解决的方法之一是对历史的对话进行总结,也可以通过 embedding 搜索实现类似效果。
分段总结长文档逐步构建完整摘要
要总结很长的文档,如一本书,我们可以逐段进行总结。将各段的摘要合并后再次总结,形成摘要的摘要。这个过程可以递归进行,直到整个文档被总结。如果需要使用前面部分的信息来理解后面的内容,可以在总结时加入前面的摘要。
4. 给GPT“思考”时间
回答前让模型自己先计算答案
第一次看到这个现象感觉比较神奇:直接把复杂的计算问题丢给 GPT 做真假判断,GPT 很可能会出错,但是如果让 GPT 自己先算一遍,结果往往就正确了。后面有论文单独说明这个情况。
使用内部对话或一系列查询来隐藏模型的推理过程
模型有时需要详细推理问题才能回答特定问题。在某些情况中,与用户分享模型的推理过程可能不合适。例如,在辅导作业时,我们可能希望鼓励学生自己找答案,但模型对学生答案的推理可能会泄露正确答案。内部对话是一种可以用来解决这个问题的方法,其思路是让模型将不想让用户看到的输出部分放入结构化格式,便于解析。然后在给用户展示输出前,解析输出并只显示部分内容。

询问模型在前面的步骤中是否有遗漏
通常会用在让模型去总结一些摘录内容,通过 prompt 来确认是否有遗漏内容:
Are there more relevant excerpts? Take care not to repeat excerpts. Also ensure that excerpts contain all relevant context needed to interpret them - in other words don't extract small snippets that are missing important context.
5. 使用外部工具
使用 embedding-based 搜索实现高效的知识检索
模型可以使用输入中的外部信息来提供更准确的答案。例如,当用户问及某部电影时,向模型输入中加入该电影的详细信息(如演员、导演)会更有帮助。嵌入式搜索可以帮助模型实时地找到相关信息。简单说,文本嵌入就是将文本转化为向量,从而快速找到相关的文本内容。这样,当有一个问题时,我们可以迅速找到与之相关的信息。
编写 code 或调用外部 API
让模型自己写 code,并且代码执行的结果可以作为下个模型的输入。
6. 系统性测试变化
在样本比较小的情况下,很难判断某个 改动 是否有效,或者在某方面有效但其他方面反而效果下降。OpenAI 提供了一个叫 Evals 的工具,可以用来构建评估程序。如果知道答案应包含某些事实,我们可以用模型查询来检查答案中包含了几个。
四、吴恩达:ChatGPT Prompt Engineering for Developers
吴恩达的 Prompting 教程是今年 5 月份出的,在看完 OpenAI 的官方文档后,再看吴恩达的视频会感觉比较简单。因此,对照着吴恩达的教学视频学习,另外一个意义是要开始进行【实战】,自己尝试通过代码设置 prompt 并获得结果。
我是通过官方的视频教程 + b站翻译的视频 结合学习的,官方网站用来获取代码示例,b 站视频用来辅助看翻译文字。
前置条件
注册 OpenAI 账号并获取 key
安装 annconda,使用 Jupyter Notebook
安装 Python,引入 openai 包
我花了比较多的时间在安装 python 和配置环境变量等,甚至在安装完成后,第一次启动就直接报错“You exceeded your current quota, please check your plan and billing details”,网上找了很多资料,尝试新注册一个账号才搞定,所以千万不要低估了上手这一步,通过实战遇到问题解决问题,对自己的提升有很大帮助。
在首次尝试,按照吴恩达的视频教程无法调用 openai,改为参考 OpenAI 在 Github 的样例:https://github.com/openai/openai-python,终于成功输出。

接下来,成功输出了总结文字,完成了一次完整的 prompt 到输出的流程。
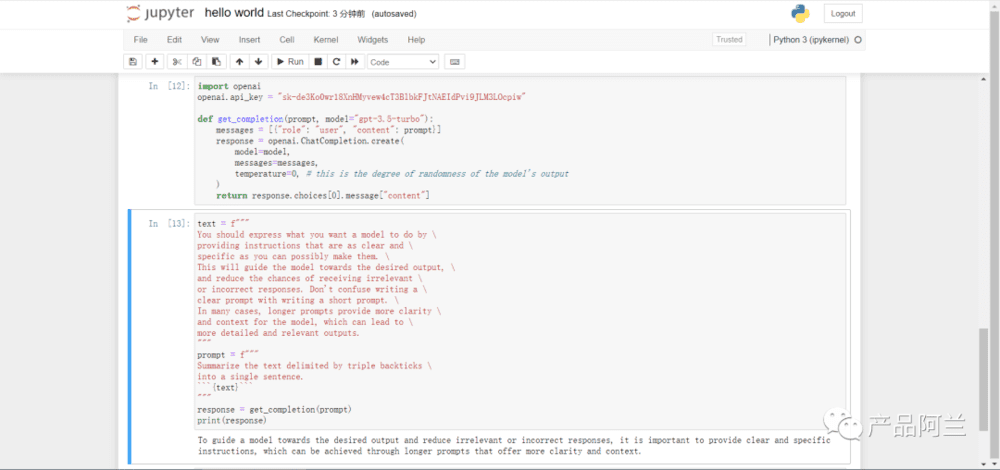
1. Guidenlines 指导原则
这个指导原则相比较 OpenAI 的官网文档少了很多,只有“具体清晰+给模型思考时间”这两条,但是增加了模型幻觉的说明。
原则一:指令需要具体清晰
可以使用分隔符对输入信息进行区分(Delimiters can be anything like: ```, """, < >,, :)
直接要求返回结构化的结果(例如以 JSON 的格式)
让模型自己检查结果是否满足要求(如是否能按照步骤进行输出,如“是”输出每一步的内容,“否”则直接输出否)
Prompt 中直接 few-shot(例如让模型写诗,给出一段风格参考)
原则二:给模型“思考”的时间
指定完成任务需要的步骤(例如在结果中要求,step1、step2……)
让模型自己先给出答案,然后把样本和模型的答案进行比较(这个比较神奇,你直接问模型样本答案的正确性,模型可能给出错误信息,但是你让模型先自己弄清楚然后再比较,得到的信息往往更加正确,实际上样例中的这句话就挺魔幻,真的像和一个智能人对话“Don't decide if the student's solution is correct until you have done the problem yourself”)。
模型当前问题:幻觉性
模型的幻觉问题,是指他会编造一些不存在的事物,并且绘声绘色地进行描述。
解决这个问题的办法之一,是提供引用的信息,让模型只从引用的信息找答案。

2. Iterative 迭代
这节课的核心思想是迭代,一般很难一次就获得满意的结果,因此总是需要基于结果反过来迭代优化 prompt。其实,目前很多流行的 prompt 都是这样迭代产生的。
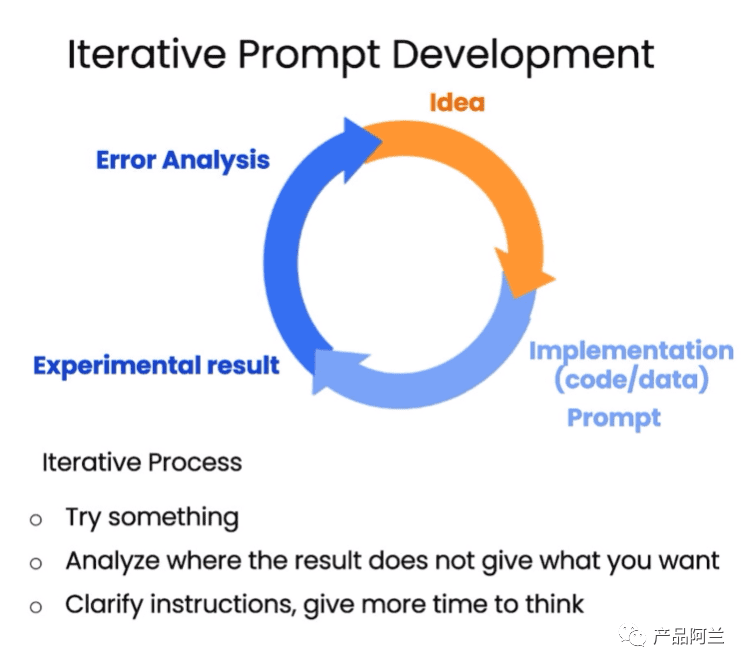
例如,你想要从一段话中提炼出可对外宣传的产品描述,如果觉得描述的结果过长,可以在提示词中加上缩短输出的文字。可以加细节、产品名称等等,甚至直接让模型生成 html 格式内容,看到输出的效果后确实有点震惊。核心是基于一个简单的想法,不断迭代接近于自己想要的效果。
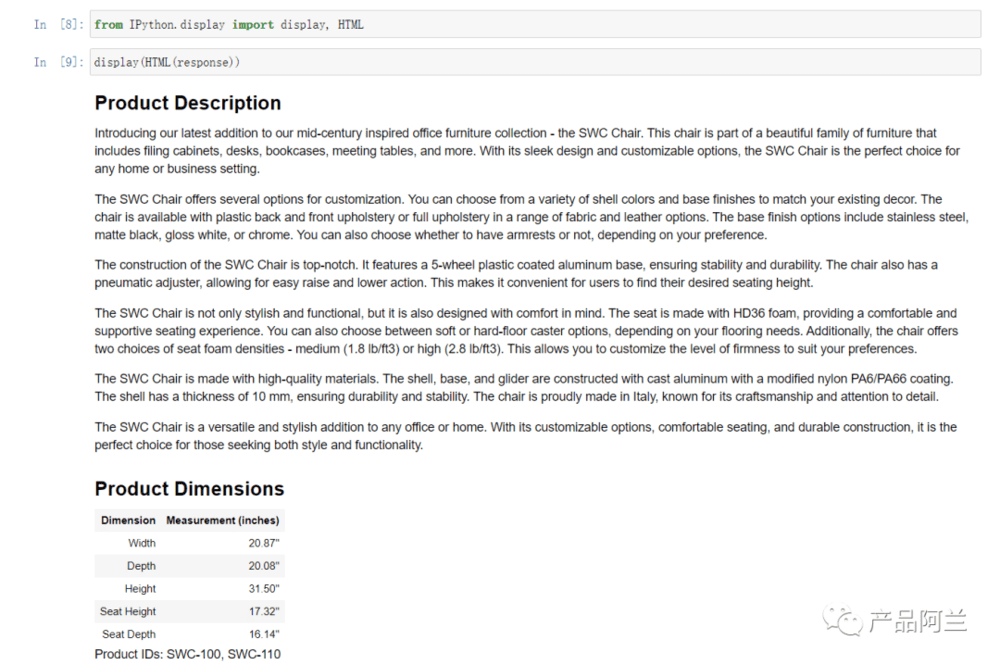
3. Summarizing 总结
我们经常用 ChatGPT 的聊天界面进行总结,可以基于一段话让模型总结特定的内容。还可以有另外一个思路,让模型提取特定内容,而不是总结。

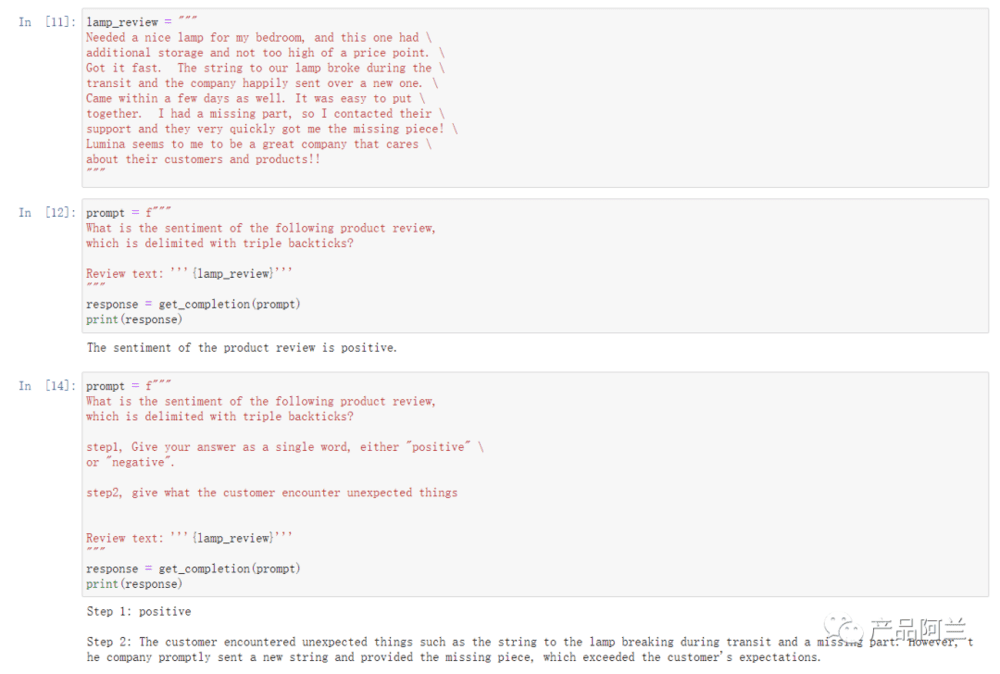
4. Inferring 推理
一个典型的应用场景是从文本中提取情感正负面。和传统的机器学习模型不一样的是,大模型特别擅长从文字中提取内容,例如我在吴恩达的例子中,让模型总结客户遇到的意外情况,以帮助客服部门提前作告知准备,结果也让我非常满意。总结的结果可以要求格式化,例如JSON格式,用于后续使用。
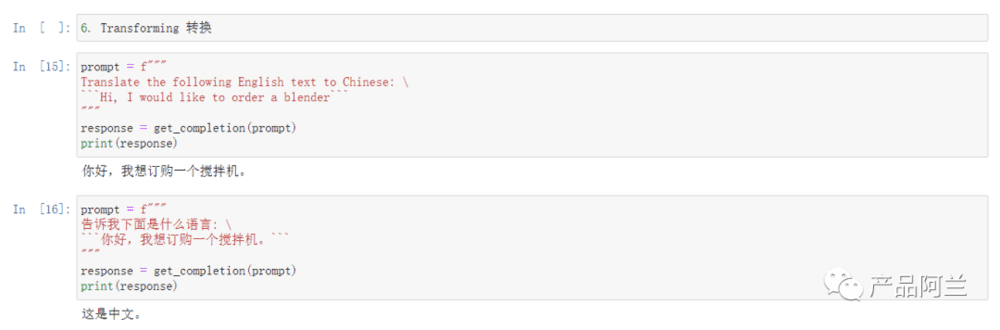
5. Transforming 转换
转换的典型应用场景是“翻译”,ChatGPT 刚出现的时候,我的预感就是肯定要颠覆翻译行业,现在看来是确定性的了。使用模型的翻译能力的时候,可以通过“翻译+校正+重写”来提升准确性。
6. Expanding 扩展
典型的应用场景是写邮件、生成SEO文章。这里经常会涉及到 temperature 参数的更高,如果是0的话意味着结果稳定性,如果想要提升创意性就需要增加 temperature,实际使用中发现 temperature 越高等待结果的时长也越高。temperature 在 0-1 范围内,结果通常是正常的,如果大于1可能实际不可用。

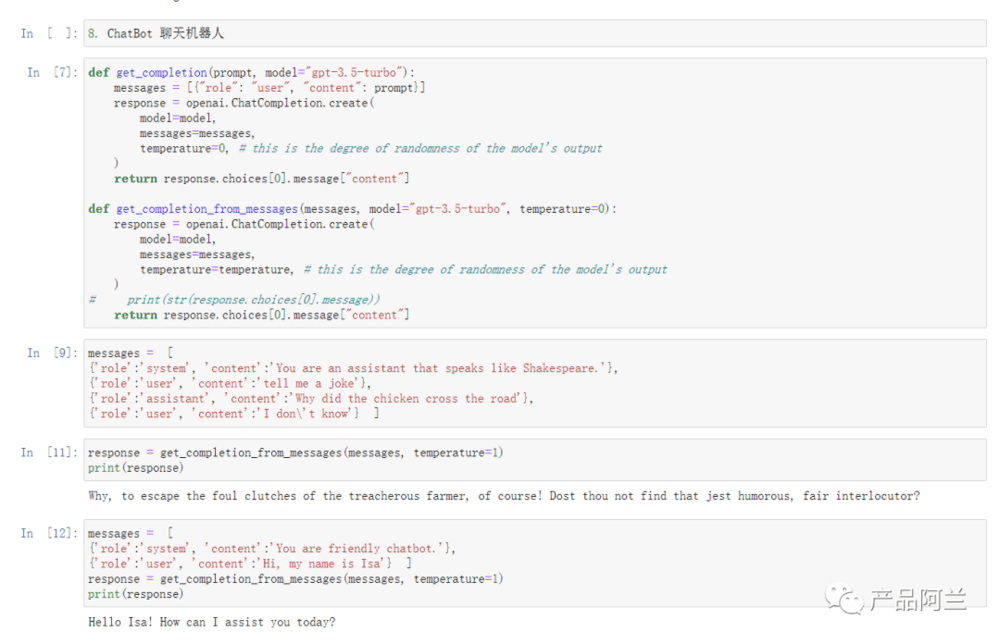
7. ChatBot 聊天机器人
通过定义一个【系统 system】的角色,让模型的回复限定在某个范围内,现在很多的小的套壳应用都是基于这种方式实现的。如果需要bot记住上下文 context,需要把上下文也放在input中。
五、OpenAI 推荐的 Prompt 论文
OpenAI 的 cookbook 中推荐了 12 篇论文,大多数是2022年发表的,可见业界在2022年就开始探索通过 prompt 提升大模型的能力。OpenAI 的官方教程的很多方法也是基于这些论文,甚至可以说是最佳实践。我在看的时候实际上有点一知半解,所以会找一些论文解读辅助一起看,印象比较深刻的有几个概念:CoT、ToT……
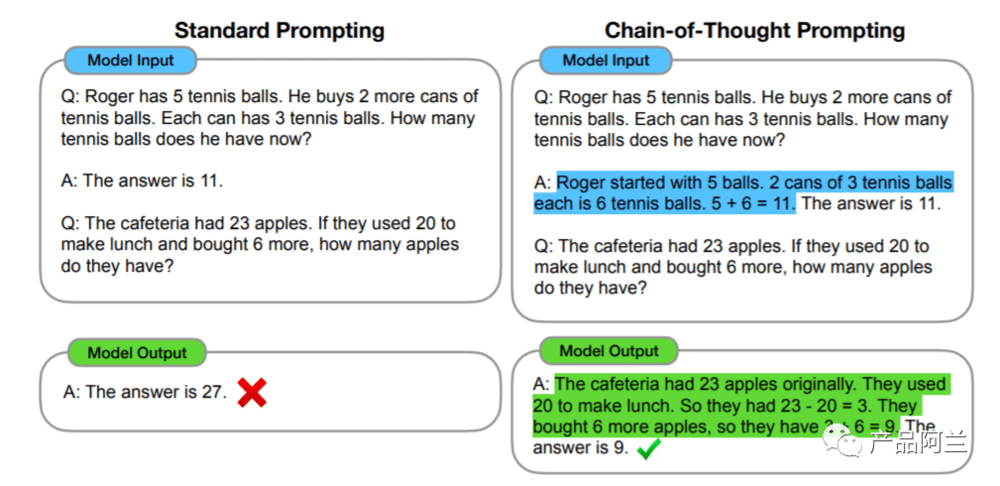
1. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
简介:
通过“链式思考 CoT”提升大模型推理能力:这篇论文在 2022年1月就提交了第一版,23年1月修改了第六版本,当中提及的模型还是 GPT 3。原文地址:https://arxiv.org/pdf/2201.11903.pdf
中文解读:
大模型思维链(Chain-of-Thought)技术原理
使用语言模型完成推理任务——Language Model Reasoning
提升ChatGPT性能的实用指南:Prompt Engineering的艺术
核心内容;
通过few-shot prompt,可以提升大模型推理能力,并且相比较传统方式性能更好,不需要大量进行数据训练,成本低。这个例子目前已经在 OpenAI 的官方教程中,现在看起来已经成为“常识”。
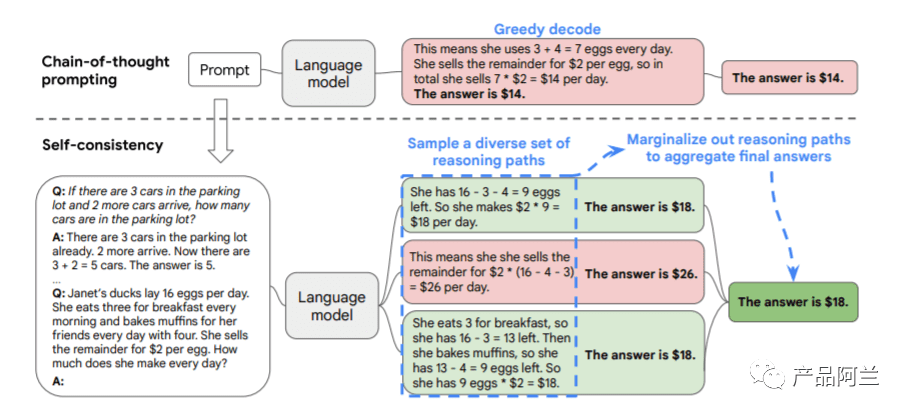
2. Self-Consistency Improves Chain of Thought Reasoning in Language Models
简介:
通过“自我一致性”提供链式思考推理能力:这篇论文是22年3月份提交的,23年3月修改到第四版。原文地址:https://arxiv.org/pdf/2203.11171.pdf
核心内容:
复杂的推理任务通常可以有多种推理路径,通过从模型解码器采样生成一系列多种推理路径,每个路径会得到答案,最后通过边缘化采样的推理路径中确定所有答案中最一致的,这个结果很可能就是最正确的。这种方法和人类的思考也是比较类似的,在多种方法中将回答最一致的作为最终答案。这种“自我一致性”的方法,避免了贪婪解码(最直接的解码方式,每次生成时直接选择模型认为概率最高的那个词)的重复性和局部最优性,也减轻了单一采样生成的随机性。
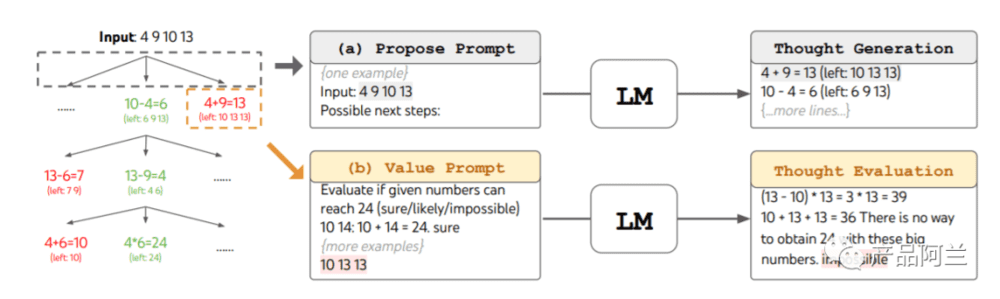
3. Tree of Thoughts: Deliberate Problem Solving with Large Language Models
简介:
思维树:用大模型解决复杂问题:23年5月提交。原文地址:https://arxiv.org/pdf/2305.10601.pdf
核心内容:
大语言模型生成结果一般采用自回归机制(在每个新单词产生后,该单词就被添加在之前生成的单词序列后面,这个序列会成为模型下一步的新输入),人类做决策的时候通常有两种模式,1是简单快速的无意识决策,2是缓慢的深度思考的模式,当前大语言模型自回归机制一般是第一种。
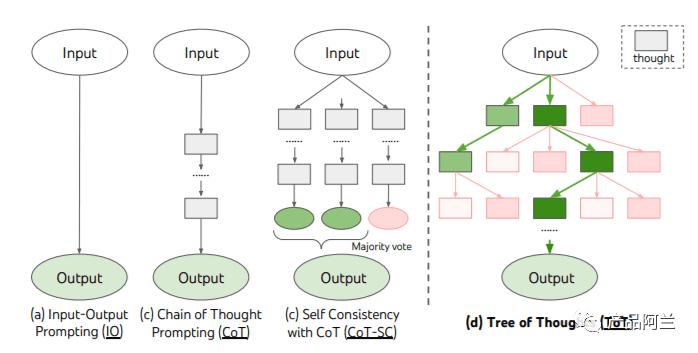
下图是 ToT 的逻辑图,ToT主动维护一个思维树,其中每个思维都是一个连贯的语言序列,作为解决问题的中间步骤,最后基于语言的生成和评估多样化思维的能力与搜索算法,如广度优先搜索(BFS)或深度优先搜索(DFS)结合起来,这些算法允许系统地探索思维之树,并进行预测和回溯。
24点游戏举例:
4. 其他
Large Language Models are Zero-Shot Reasoners:大模型是零样本推理者。2022年5月提交,23年1月修正到第四版。原文地址:https://arxiv.org/pdf/2205.11916.pdf。
核心内容:在 prompt 中加上“let's think step by step”,就能显著提升模型的推理能力,并且效果比 few-shot 还要好。

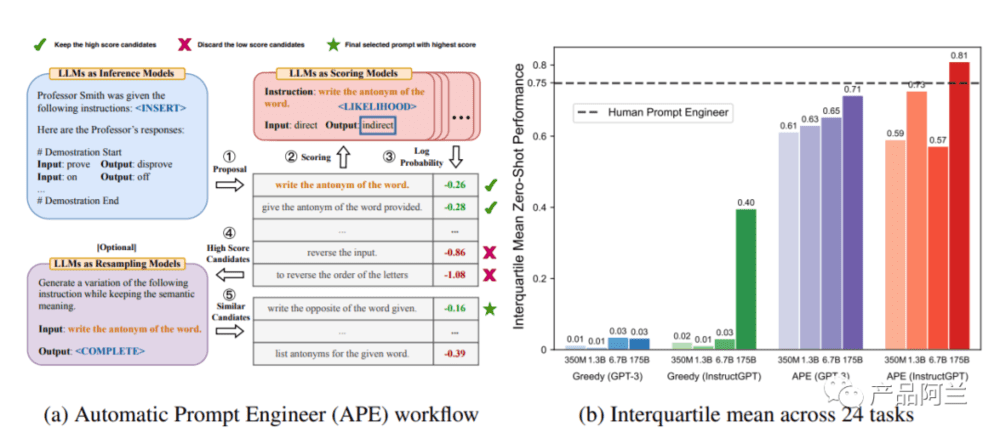
Large Language Models Are Human-Level Prompt Engineers:大模型自己作为 prompt 工程师。2022年11月发表,23年3月修正到第二版。原文地址:https://arxiv.org/pdf/2211.01910.pdf。
中文解读:AI取代人类,可以自动生成prompt了。
核心内容:将 LLM 视为执行由自然语言指令指定程序的黑盒计算机,并研究如何使用模型生成的指令来控制 LLM 的行为。
Reprompting: Automated Chain-of-Thought Prompt Inference Through Gibbs Sampling:自动prompt:通过吉布斯采样(Gibbs Sampling)实现自动 CoT。23年五月提交。原文地址:https://arxiv.org/pdf/2305.09993.pdf。
核心内容:提出了一种名为"Reprompting"的迭代采样算法,它可以自动为指定任务寻找 CoT 方法。通过Gibbs采样,我们得到了在一组训练样本上表现稳定的 CoT 指令。我们的方法会迭代地采样新的指令,并使用之前采样的解决方案作为提示来解决其他训练问题。在需要多步推理的五个Big-Bench Hard任务上,Reprompting的性能持续超越 zero-shot、few-shot 和人工编写的CoT基线。
Faithful Reasoning Using Large Language Models:使用大模型实现可信推理,2022年8月提交,这是 deepmind 团队出的文章。原文地址:https://arxiv.org/pdf/2208.14271.pdf。
中文解读:https://zhuanlan.zhihu.com/p/562150770。核心内容:为了突破机器学习可解释性这道难关,DeepMind 研究团队在论文中展示了如何通过因果结构反映问题的潜在逻辑结构,借此过程保证语言模型忠实执行多步推理。研究团队的方法会将多个推理步骤联系起来共同起效,其中各个步骤均会调用两套经过微调的语言模型:其一用于选择,其二用于推理,借此产生有效的推理跟踪。
STaR: Bootstrapping Reasoning With Reasoning,22年3月提交,原文地址:https://arxiv.org/pdf/2203.14465.pdf。中文解读:论文阅读[粗读]-STaR: Self-Taught Reasoner Bootstrapping Reasoning With Reasoning。
核心内容:通过迭代地利用少量的理由示例和一个大型没有理由的数据集,来逐步增强执行越来越复杂的推理的能力。这种技术称为“自学推理者”(STaR),它依赖于一个简单的循环:使用少量的理由示例来生成回答许多问题的理由;如果生成的答案是错误的,尝试再次给出正确答案的理由;对最终给出正确答案的所有理由进行微调;然后重复这个过程。
ReAct: Synergizing Reasoning and Acting in Language Models:ReAct范式,在大语言模型中结合推理和动作。22年10月提交,23年3月修订第三版。原文地址https://arxiv.org/pdf/2210.03629.pdf。中文解读:https://zhuanlan.zhihu.com/p/624003116。
核心内容:作者提出了ReAct范式,通过将推理和动作相结合来克服LLM胡言乱语的问题,同时提高了结果的可解释性和可信赖度。

Reflexion: Language Agents with Verbal Reinforcement Learning,Reflexion:语言强化学习的agent,2023年3月提交,6月修订到第三版。原文地址:https://arxiv.org/pdf/2303.11366.pdf。核心内容:提出了Reflexion一种新颖的框架,它不是通过更新权重,而是通过语言反馈来增强语言代理。
Demonstrate-Search-Predict: Composing retrieval and language models for knowledge-intensive NLP,4.5 演示-搜索-预测:组合检索和语言模型进行知识密集型NLP,2022年12月提交,2023年1月修订第二版,原文地址:https://arxiv.org/pdf/2212.14024.pdf。
Improving Factuality and Reasoning in Language Models through Multiagent Debate,通过多智能体辩论提高语言模型的真实性和推理能力。2023年5月提交,原文地址:https://arxiv.org/pdf/2305.14325.pdf。
核心内容:提出一种新的框架,通过多个语言模型实例之间的多轮辩论来改进单个模型的回复质量。让多个模型各自独立生成回答,然后相互质疑、辩驳,经过多轮后形成共识并输出最终答案。多模型辩论是改进语言模型的有效补充手段,值得进一步研究与应用。

参考资料
1. OpenAI 官方
官网教程:GPT best practices,https://platform.openai.com/docs/guides/gpt-best-practices
Github:https://github.com/openai/openai-cookbook
2. 吴恩达视频教程
官方:https://learn.deeplearning.ai/chatgpt-prompt-eng
B站中文版:https://www.bilibili.com/video/BV1Mo4y157iF/
3. OpenAI 官方推荐
提示工程指南 | Prompt Engineering Guide:https://www.promptingguide.ai/zh
GitHub - brexhq/prompt-engineering: https://github.com/brexhq/prompt-engineering
Prompt Engineering:https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/
4. 其他
系统论述文章:构建高性能 Prompt 之路——结构化 Prompt
腾讯技术工程:提升ChatGPT性能的实用指南:Prompt Engineering的艺术
面向开发者的 LLM 入门课程:https://datawhalechina.github.io/prompt-engineering-for-developers/#/flowgpt.com
本文来自微信公众号:产品阿兰(ID:gh_9ace63f81242),作者:alan