
欧盟《人工智能法案》有望成为世界首个针对这一新兴技术的全面监管法案,而且凭借“布鲁塞尔效应”,它还有可能被视为人工智能监管的全球标准之一——就像欧盟《通用数据保护条例》(GDPR)对数据保护监管的作用一样。继6月欧洲议会通过一系列修正案后,人工智能法案的最终立法审议,三个相关立法机构——欧盟委员会、理事会和议会——将致力于制定一份商定的文本版本,即“三部曲”已经开始。
一般来说,在“三部曲”中,欧盟委员会代表欧盟整体利益,而欧洲理事会(代表成员国)和欧洲议会(代表人民利益)之间的一些分歧需要调和。传统上,欧洲议会对“立法文本中对权利严格保护”的强调被欧洲理事会所代表的成员国的经济和社会利益所抵消。
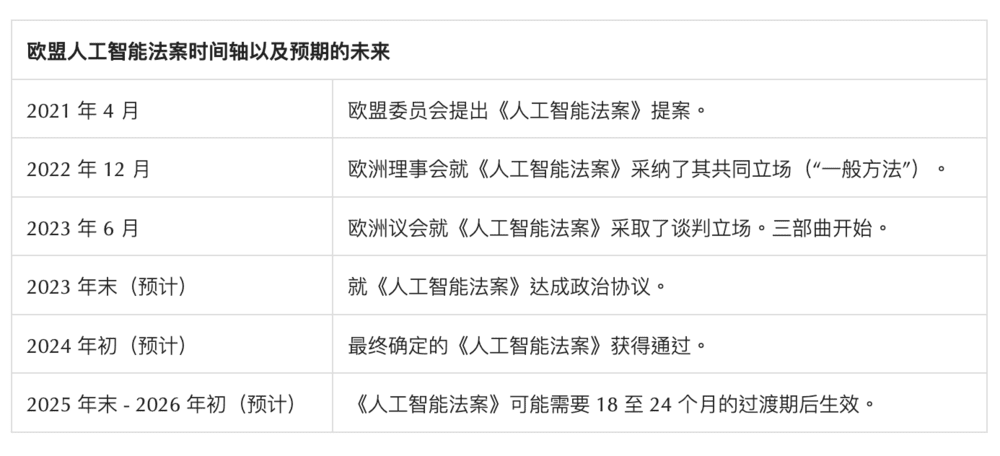
为了预测最终欧盟《人工智能法案》最终版本如何,本文分析了谈判前存在重大争议的几个领域:人工智能的定义、禁止的人工智能应用清单、高风险人工智能的义务、基础模型和执法机制。欧盟《人工智能法案》生效后将在成员国直接适用并立即强制执行。这使得其中列出的定义尤其重要,因为它们不会因国家实施法规的不同而存在差异。
一、人工智能的定义
在任何给定的法律中,定义与任何正式规则一样重要,或者具有与任何正式规则同等的法律效力。在人工智能这样复杂的领域,整个研究都致力于解决人工智能定义的挑战。
欧盟委员会提出的人工智能定义基于法规附录中列出的一系列技术。然而,欧洲理事会和议会都将定义移至文本正文中。欧洲议会还使第3条中“人工智能系统”的定义与OECD制定的定义保持一致。议会做出的其他重要术语更改包括将人工智能系统的用户称为“部署者”,以及添加“受影响人员”、“基础模型”和“通用人工智能系统”的新定义。
欧盟《人工智能法案》中对术语争论的核心在于两个极点之间:一方面,人们担心人工智能的定义可能“撒网太广”,包括像电子表格中的计算这样简单的东西;另一方面,过于精确的定义也会影响法律的效力,阻碍人工智能的积极发展。“面向未来”对于快速技术变革领域的立法尤其重要。
虽然在立法文本的每个阶段对人工智能的定义都取得了进展,但欧盟三场谈判都有可能改变人工智能价值链中各种术语的定义方式。
二、禁止的人工智能系统清单
总体而言,欧盟《人工智能法案》对人工智能采取基于风险的监管方式,即根据人工智能技术对个人健康和安全或基本权利构成的风险程度对其进行分类。法律的风险等级或风险类别包括不可接受、高、有限或最小。
其中,欧盟《人工智能法案》第5条完全禁止“不可接受的人工智能系统”,包括但不限于使用潜意识、操纵或欺骗技术来扭曲人的行为的人工智能系统,利用个人或群体的脆弱性的人工智能系统,或人工智能系统对自然人或群体进行社会评分评估或分类,从而导致其受到有害或不利的待遇。
关于哪些人工智能系统应该属于哪个风险类别一直存在争议。最重要的争论是关于在公共场所的何处放置生物识别监控的讨论。欧洲议会将公共空间中的“实时”远程生物识别系统添加到禁止使用人工智能的清单中,尽管中右翼欧洲人民党在最后一刻试图对该禁令进行减损,但最终没有成功。欧洲人民党(EPP)允许这种用途的立场与欧盟委员会的最初提案一致,欧洲理事会也维持了该提案。
虽然最终增加了执法部门在公共场所禁止使用远程生物识别系统的禁令,但欧洲议会允许在事先获得司法授权的情况下事后使用该系统。它还禁止使用性别、种族、民族、公民身份、宗教和政治取向等敏感特征的生物识别分类系统。
总而言之,争论的核心是,欧洲议会主张制定更广泛的禁止人工智能系统清单,包括从网络上抓取面部图像的软件,而欧洲理事会则更倾向于缩小范围。鉴于这种反对,第五条的进一步修改,包括围绕生物特征识别禁令及其例外的修改,可能会在三场对话期间进行。
三、高风险人工智能系统的要求
《人工智能法》第 6 条规定了高风险人工智能系统的义务。在附件三中,它列举了属于高风险定义的八种特定类型的人工智能系统的列表。根据法律规定,受最严格义务约束的高风险人工智能系统的一级类别是:
1. 关键基础设施
2. 自然人的生物特征识别
3. 教育和职业培训
4. 就业/劳动力管理
5. 基本的私人和公共服务
6. 执法
7. 边境管制
8. 司法和民主程序
每一个高风险人工智能系统类别中都有许多子类别。欧洲理事会和议会对欧盟委员会提出的最初清单进行了重大修改。例如,在其修正案中,欧洲议会在高风险分类中增加了某些社交媒体平台(即根据《数字服务法》被指定为“超大型在线平台”的平台)用于为用户生成建议的人工智能系统,以及意图影响选举或公投结果的人工智能系统。
确定哪些特定人工智能系统应被归类为高风险的方法仍然存在很大的模糊性。例如,应用人工智能倡议开展了一项风险分类研究,评估了 100 多个人工智能系统。总体而言,研究发现其中约 40% 的人的风险水平不明确。报告指出,关键基础设施、就业和执法是造成风险分类不明确的三个主要原因。相比之下,大约 1% 的人工智能系统被列为禁止类,18% 为高风险类,42% 为低/最小风险类。
四、对基础模型的要求
欧洲议会决定对基础模型施加一种制度,这种制度“在很大程度上借鉴了高风险人工智能应用的制度,特别是在风险管理和数据治理方面”,这也使什么是高风险人工智能系统的问题进一步复杂化。事实上,欧洲议会对人工智能法案文本提出的最重要的修改之一,是将“基础模型的提供者”纳入最低透明度要求之外的各种义务范围。
生成式 AI,包括大型语言模型或 LLM,例如 ChatGPT 和 Google Bard,是基础模型的子集,而基础模型本身也是通用AI的子集。欧洲议会在第28b(2)条中提出的关于基金会模式/LLM的新义务包括以下要求:
风险识别:使用“适当的设计、测试和分析”来展示“对健康、安全、基本权利、环境、民主和法治……的合理可预见风险的识别、减少和减轻”。
缓解措施:应用某些数据治理措施“检查数据源的适用性以及可能的偏差和适当的缓解措施”。
独立专家:让独立专家参与,记录分析,并进行“广泛的测试”,以实现“适当水平的性能、可预测性、可解释性、可纠正性、安全性和网络安全”。
环境影响测量:设计能够测量能源和资源消耗及其环境影响的基础模型。
技术说明:创建“广泛的技术文档和易于理解的说明”,使下游供应商能够遵守第16条和第28(1)条。
质量管理体系:建立“质量管理体系”,确保并记录遵守第28条的规定。
注册:在欧盟高风险人工智能系统数据库中注册基础模型。
相比之下,欧洲理事会对基础模型的做法是,要求欧盟委员会在人工智能法案生效一年半后为它们制定量身定制的义务。然而,随着欧洲议会提出一种更“详细”和明确的方法(上述),基础模型的精确义务集也可能成为“三部曲”中争论的焦点。
五、执法机制
欧盟《人工智能法案》的执行以及各个国家和欧盟当局之间的协调也是一个核心争论点。从架构上看,《人工智能法案》与《通用数据保护条例》(GDPR)类似,它将把各个国家主管部门聚集到一个“人工智能委员会”,其职能类似于“欧洲数据保护委员会”(EDPB)。欧洲议会版本的人工智能法案还将建立一个新的欧盟机构,名为人工智能办公室(第56条),该机构将拥有一系列行政、咨询、解释和执法相关的权力,并负责协调跨境调查。
在其修正案中,欧洲议会对可根据人工智能征收的罚款进行了实质性修订,将不遵守第5条(禁止的人工智能系统)的罚款提高到4000万欧元,或者对公司而言,最高可达其上一财政年度全球年营业额的7%,以较高者为准。第10条(数据治理)和第13条(透明度)违规行为将被处以较低级别的行政罚款(2000万欧元或全球营业额的4%),而其他违规行为将被处以1000万欧元或全球年营业额的2%的罚款。
但是,也许《人工智能法案》最有趣的执行动力在文本中找不到,而是体现在日益增长的欧洲数据保护监管机构的作用和执法力度上。数据保护当局“利用他们的经验和更成熟的隐私规则手册,是最早对基于人工智能的产品和服务展开调查的机构之一”。
回想一下,意大利数据保护机构 Garante在2023年4月因隐私问题暂停了ChatGPT。虽然 Garante 随后解除了禁令,但这可能是欧洲数据保护委员会随后决定成立ChatGPT工作组的催化剂,以促进合作并就数据保护机构可能采取的执法行动交换信息。
法国的DPA(国家信息与自由委员会)也将自己定位为人工智能执法机构。CNIL在其《人工智能行动计划》中指出,它将特别关注使用个人数据开发、培训或部署人工智能的行为者是否执行了“数据保护影响评估”(DPIA),并采取措施告知人们行使其权利。
鉴于这些在机构间和国际上发生的动态,欧盟《人工智能法案》的执行机制——以及数据保护监管机构在这个等式中的作用——不仅在三场谈判期间可能会引起争议,而且在法律生效后很长一段时间内都是有争议的。
结语:“三部曲”之后
由于欧盟《人工智能法案》具有“高风险、热点”的性质,欧盟立法者打算在今年年底前或最迟在定于2024年6月举行的欧洲议会选举之前就文本达成协议。
随着谈判的进行,也有很多专家表示,现有法律与人工智能法案之间的相互作用以避免双重监管、部署者的义务带来重大负担、创新条款和基本权利影响评估,也都可能成为争论的焦点。同时,随着欧盟《人工智能法案》文本最终版本的具体化,公司对适用的人工智能治理指南的需求会大大增加。
本文来自微信公众号:Internet Law Review(ID:Internet-law-review),作者:Müge Fazlioglu(国际隐私专业人士协会研究员),译者:互联网法律评论