
本文来自微信公众号:大数据文摘(ID:BigDataDigest),作者:Caleb,原文标题:《GPT-4满分通过MIT本科数学考试!却遭同门质疑“作弊”,数据集本身就有问题》,题图来自:《梅根》
这两天,相信大家都被GPT-4满分轻松拿下MIT本科数学考试的事儿给刷屏了。
给不知情的小伙伴们说一下,这次的测试是MIT、波士顿大学和康奈尔大学的研究团队共同根据MIT所有获得学位所需的数学、电气工程和计算机科学课程整理出4550个问题。
参与测试的AI模型有GPT-3.5、GPT-4、StableVicuna-13B、LLaMA-30B和LLaMA-60B。结果嘛,可想而知,GPT-4满分通过,但GPT-3.5却只做对了三分之一。

论文链接:https://huggingface.co/papers/2306.08997
这样的结果自然也是吸引到了众多网友的讨论,在网友们的一众惊呼声中,三位同样来自MIT的学生却发现了其中端倪。
揭开“网骗”GPT-4的面纱
在6月16日发现这篇论文后,三人决定深入挖掘一下。但是一小时内,他们对论文的方法论产生了怀疑。不到两个小时,他们意识到,数据集本身是有问题的。
论文中写到,研究人员“在没有图像和有解决方案”的问题中随机选择了288个问题的测试集。这个数据集(不包括用于微调开源LLM的训练集)也随着论文的发布被开源到了GitHub上,以及用于生成报告测试性能代码。
然而,Drori教授却删除了这个项目。
他们目前针对此发布了该测试集的注释副本:https://docs.google.com/spreadsheets/d/1FZ58hu-lZR-e70WP3ZPNjp9EK_4RgrQvQfsvjthQh_Y/edit#gid=1598949010
三人也表示,他们确信这个文件代表了论文中分析的测试集,因为评估代码中所有数据的文件路径都指向它,没有提供任何修改其内容的代码,而且在最初发布的GitHub仓库中也是可用的。此外,该文件也满足论文中规定的所有模式要求。
这些证据似乎非常有力地支持了一个主张,那就是:这个文件有可能被换成了一个用于测试的不同文件。如果是这样的话,证明责任在于作者公开发布这个数据和用它做的所有分析。
于是,他们开始检查各个数据点。
很快就发现,数据集中至少有10个问题是无法用提供的信息解决的,也就是说,根本不可能出现满分的情况。除此之外,还有几个问题在这个给出的背景下根本就不是有效的问题,这样的题目至少占了4%。
除了问题本身存在争议外,他们还发现,在所检查的288个问题中,有14个是重复的,在这些情况下,问题串之间的唯一区别是极小的字符级噪音,或者完全相同。
鉴于此,GPT-4能够获得满分不得不令人怀疑。得出这样的结果要么是在某个阶段将解决方案泄露到了提示中,要么是问题没有被正确评分。
这也促使他们进一步调查。最终发现,其实两边都占了。
它在演示一种更高级的“作弊”
在这里,还需要简单解释一下论文中提到的“小样本示例”(few-shot examples)。简而言之,研究人员对OpenAI嵌入的数据集内的类似问题进行余弦相似度搜索,并将这些问题和解决方案作为额外的背景纳入模型的提示,以帮助模型解决问题。这本身没什么问题,只要给出的例子和问题存在足够大的差异,以便不暴露不公平信息。
但是在随机扫描已发布的测试数据集时,他们注意到一些奇怪的事情。许多提供给模型的小样本示例几乎与问题本身一字不差,这种重叠情况可以用柱状图来表示:
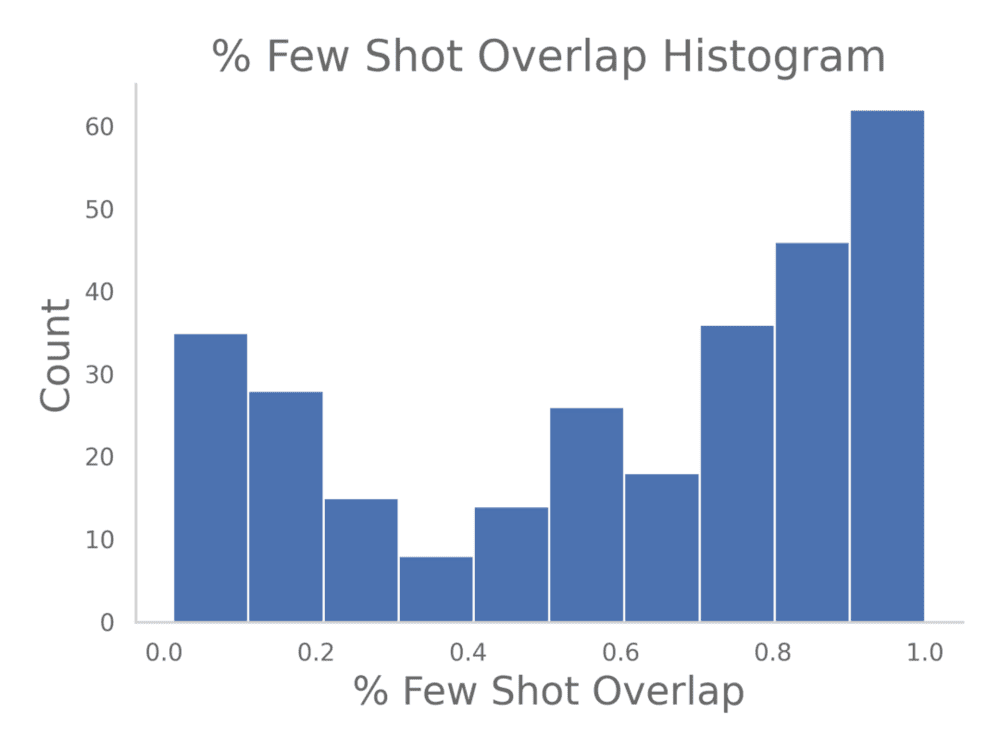
也就是说,模型得到的是问题的答案或与问题非常相似的问题。通常情况下,这来自于很多有类似背景的问题被反复提问。
在他们看来,为了正确评估GPT的解题能力,“多部分问题”(multi-part questions)的其他部分应该被完全排除在某一问题的小样本示例外。事实上,他们还发现,这些多部分问题的解决方案往往直接提到或给出模型被要求解决的另一部分问题的解决方案。
而在评分上,根据开源的打分机制中,他们也发现了一些问题。
比如流程是如何处理分级的。事实上,研究人员是利用GPT-4来打分的,包括原始问题、解决方案,和GPT自己的答案,作为分级提示的参数。
在其他技术领域,GPT更有可能出现隐性误解,这种自动评分也就更有可能出现自我安慰的结果。
此外,虽然prompt级联是最近许多GPT论文中常见的技术,但这里有大量数据泄露的可能性。每一级不仅提供基于基础事实的二元信息,而且还在prompt,直到达到正确答案。
虽然这些创建的prompt没有看到实际的解决方案,但重新prompt正确答案直到达到正确答案的二进制反馈是足够的,尤其是在占测试集16%的多选题中,无限地尝试保证了正确的答案。
这就好比有人拿着答题纸告诉学生他们是否得到了正确的答案,直到他们得到答案。
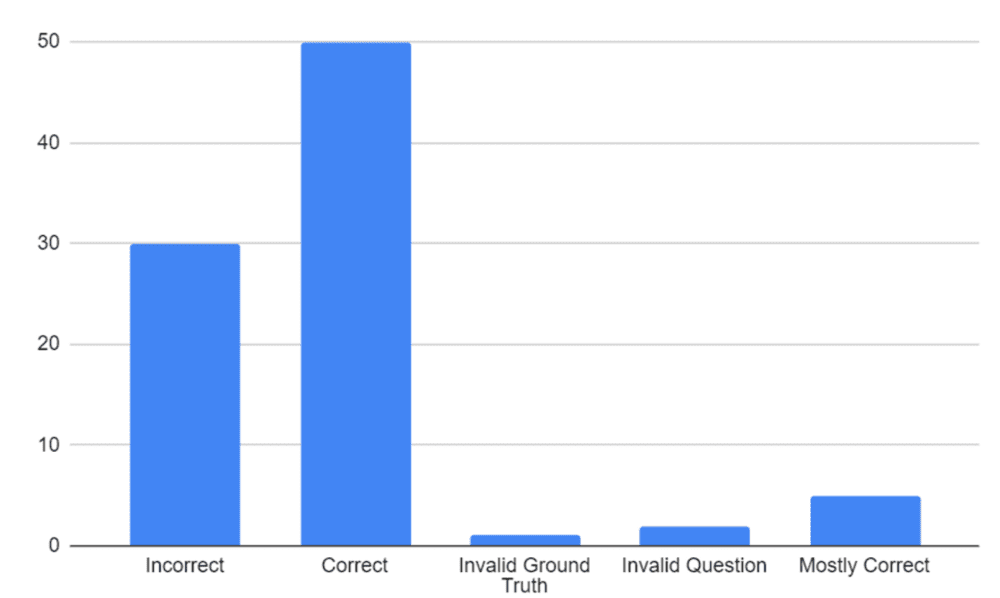
在戳破这层假象后,他们在数据集上完成了零样本GPT-4的运行,对数据的前30%进行了手动评分,结果与原论文可以说是“天壤之别”。
语言模型还不能被当作产生基础真理的神谕
最后,三人表示,他们目前提出的问题只是几个小时的审查中发现的最明显的问题,后期随着更多人更仔细的审查,会发现更多的漏洞。
他们也鼓励读者下载数据集,自己检查,毕竟只有通过了同行评估,才能得到最终肯定。
同时,他们也写到,他们对数据分析方法的完整性的观察是令人担忧的。这篇论文道出了最近人工智能研究的一个更大趋势:随着该领域的进展越来越快,研究时间线似乎在缩短,这其中就不可避免地存在走捷径的行为。
一个特别令人担忧的趋势,是使用像GPT-4这样基于语言的模型来评估另一个模型的准确性的技术。虽然它是一个有用的工具,但结论绝不应该被夸大,也不应该被当作真理。
最近有论文就写到,如果没有准确的真实信息,GPT-4的验证并不可靠。至少,应该选择一个随机的数据集子集,将GPT-4的性能与人类的对应物进行比较。语言模型还不能被当作产生基础真理的神谕。
此外,在使用数据之前,无论是用于训练、推理、基准测试还是其他方面,重新评估每一个数据点并进行基本的理智检查是极其重要的。鉴于有关数据集的规模较小,简单的人工验证很容易在工作范围内完成。
有网友在推特上打趣地说:“这是LLM和作者推荐必吃的甜点,如果你赶时间,让GPT-4预测以下哪种味道最好。”

看来,关于GPT的相关研究和衍生风波,都还会持续再刮一阵子。
参考资料:https://flower-nutria-41d.notion.site/No-GPT4-can-t-ace-MIT-b27e6796ab5a48368127a98216c76864#c49f4b29e01745de9bf1ffdf2170b067
本文来自微信公众号:大数据文摘(ID:BigDataDigest),作者:Caleb