
本文来自微信公众号:量子位 (ID:QbitAI),作者:金磊、丰色,原文标题:《视频版Midjourney免费开放,一句话拍大片!网友:上一次这么激动还是上次了》,头图来自:Gen2
现在做个影视级视频,也就是一句话的事了!
例如只需简单输入“丛林(Jungle)”,大片镜头便可立刻呈现:

而且围绕着“丛林”变换几个搭配的词语,比如“河流”“瀑布”“黄昏”“白天”等,这个AI也能秒懂你的意思。
还有下面这些自然美景、宇宙奇观、微观细胞等高清视频,统统只需一句话。

这就是Stable Diffusion和《瞬息全宇宙》背后技术公司Runway,出品的AI视频编辑工具Gen2。
而且就在最近,一个好消息突然袭来——Gen2可以免费试用了!
这可把网友们开心坏了,纷纷开始尝鲜了起来。
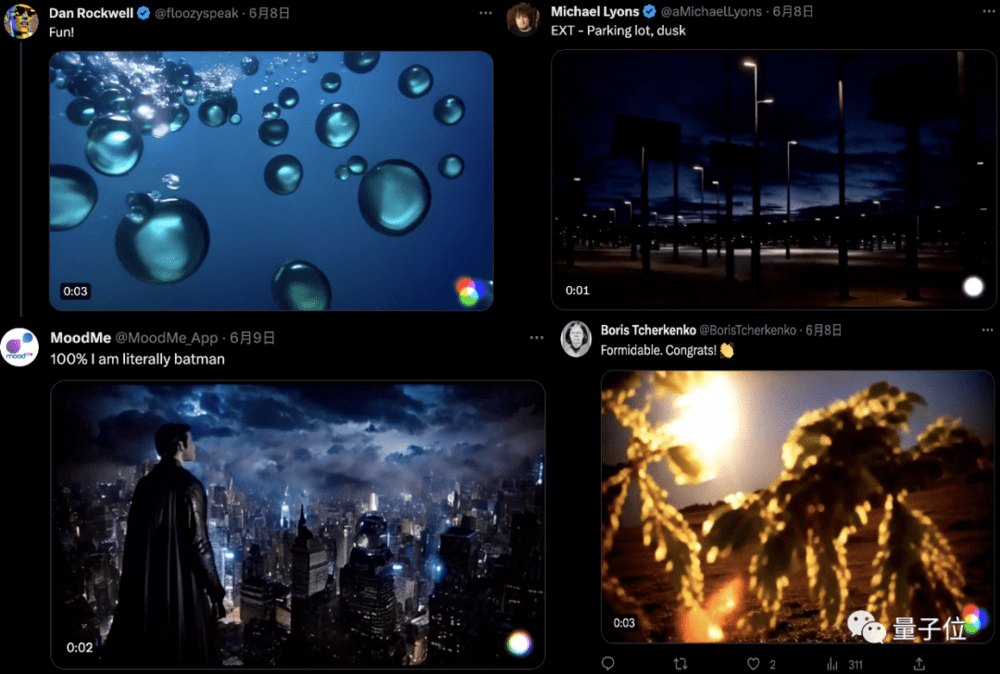
体验Gen2实录
如此好玩的技术,我们当然也要亲手体验上一番。
例如我们给Gen2投喂了一句中文:
上海外滩夜景,影视风格。

一个航拍视角的视频片段便立即被做了出来。
如果想让视频的风格变换一下,也可以上传一张图片,例如我们用的是一张赛博朋克风格的城市照片。

那么Gen2就会把你输出的提示词和照片风格做一个“合体”:

目前Runway官网可免费体验Gen2的功能是文生视频(Text to Video),但Gen1也开放了视频生视频(Video to Video)的功能。

例如一个国外小哥可能受《瞬息全宇宙》的启发,凭借Gen1也玩了一把更刺激的穿越。
他先是在家录了一段打响指的视频,然后“啪的一下”,瞬间让自己步入欧洲皇室贵族的“片场”:

然后……就连物种、性别,都可以随随便便地切换:

最后,再经历几次不同时空、人种的穿越之后,小哥一个响指又回到了自己的家里:

在看完Gen2生成的这波“大秀”之后,网友们不淡定了,直呼:
娱乐圈要被生成式AI重新定义了。
PC、手机都能玩
网页端和移动端(仅限iOS系统)现在均可正式开始体验。
以网页端为例,进入Runway官方主页(文末链接[1]),点击上方“TRY NOW”并注册账号,就可以进入下面的界面:
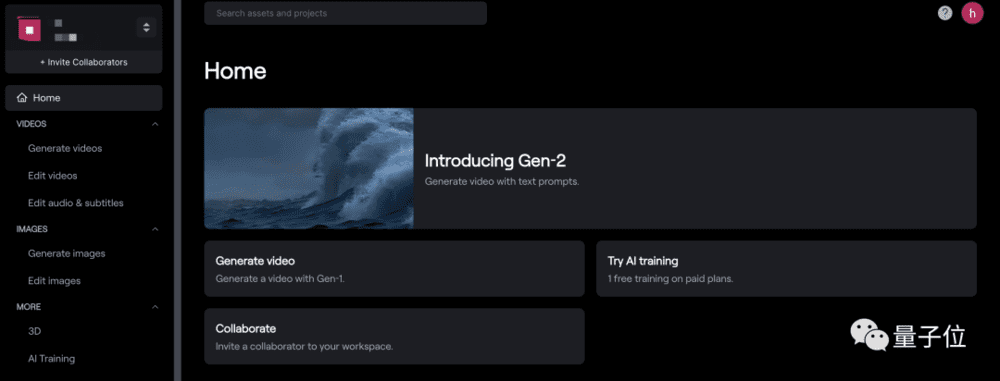
点击右方的“Introducing Gen2”,我们就可以正式开玩了。
首先,输入提示词,最多320个字符,然后在左边的设置菜单里进行一些基础配置(包括种子参数、插值等),点击“Generate”。

(当然,你也可以为视频提供一张参考图像,点击右边的图像图标即可。)
不到1分钟的工夫,视频就出来了。
点击下方播放按钮即可查看效果,视频可以直接保存到本地,也可以只保存在你的账户中。
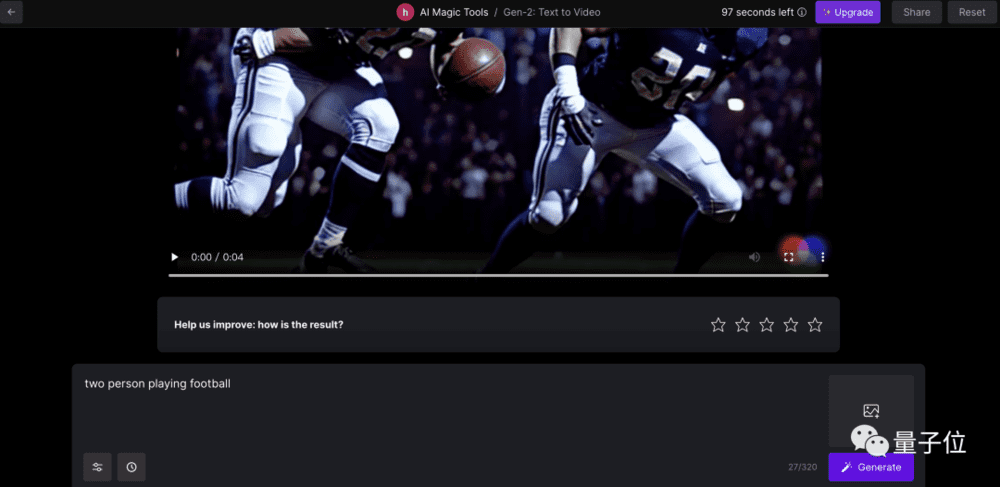
当然,如果你不满意,还能在下方的提示词框中继续修改。
需要注意的是,免费试用的额度为105秒(右上角显示剩余额度),每个视频为4秒,也就是大约可免费生成26个Gen2视频。

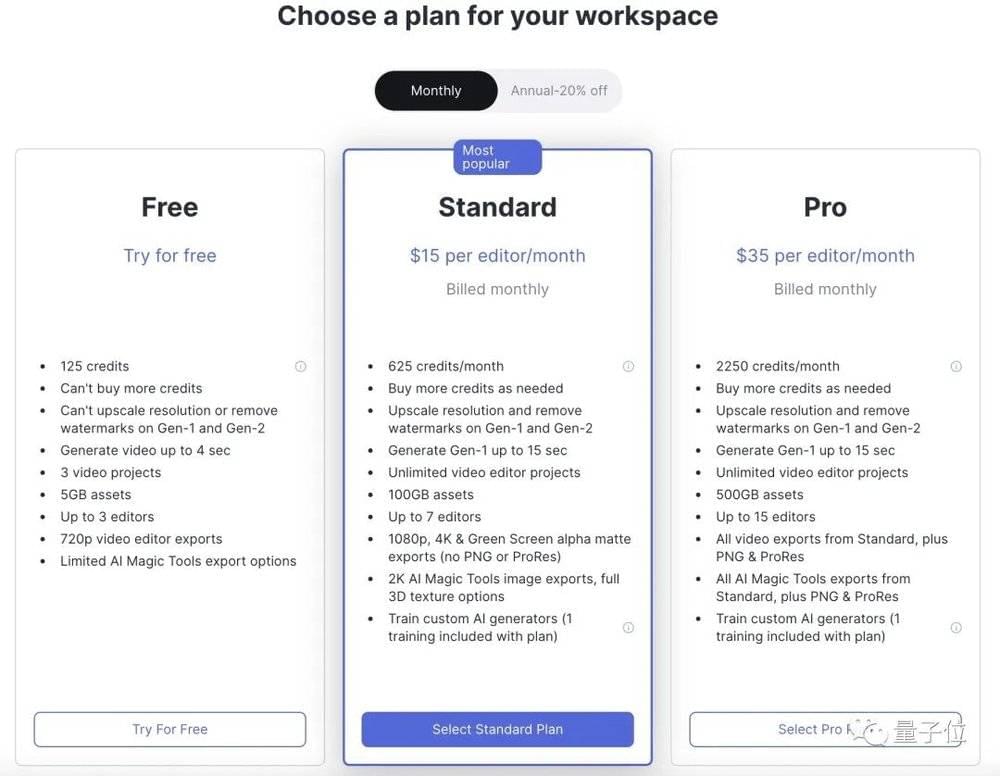
额度用完或者你想体验去水印、提升分辨率等额外功能,就需要买会员,标准版为15美元一个月,Pro版35美元,年付更便宜一些。
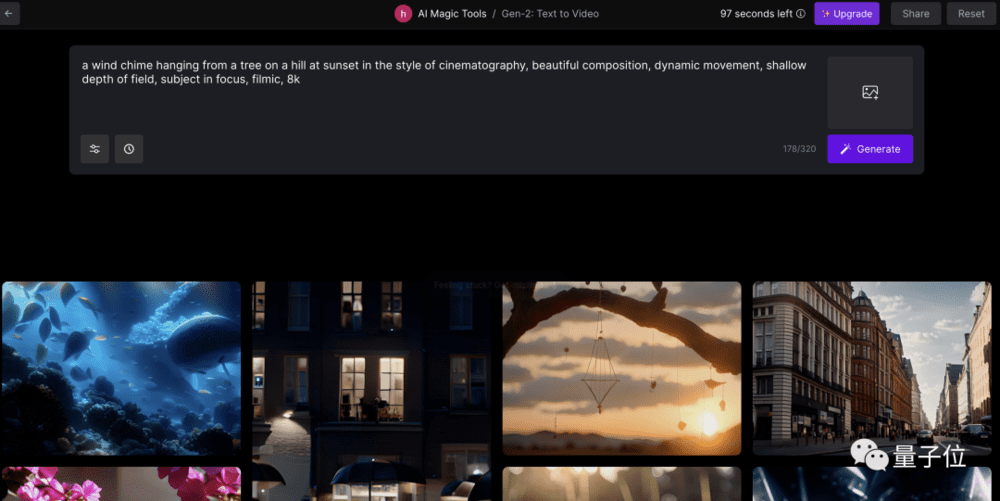
如果你想要生成效果更好,可以多使用“in the style of xxx”的形式,比如:
A palm tree on a tropical beach in the style of professional cinematography, shallow depth of field, feature film.(如下图)
A palm tree on a tropical beach in the style of 2D animation, cartoon, hand drawn animation.

或者直接去它的灵感库,选择一个你喜欢的视频然后点击“try it”即可查看它的提示词是怎么写的,然后在上面进行编辑或模仿就好了:
还有网友表示,使用“cinematic shot of”开头,也能让你的视频更具动感(解决了很多人试出来的视频不怎么动的问题)。

什么来头?
Gen2于今年3月20日正式发布,经历了两个多月的内测,现在终于正式上线。
它的前代Gen1只比它早了一个多月(2月发布),所以说迭代速度相当快。
作为一个基于扩散的生成模型,Gen1通过在预训练图像模型中引入时间层,并在图像和视频数据上进行联合训练,完成了潜扩散模型到视频生成领域的扩展。
其中也包括使用一种全新的引导方法完成了对生成结果时间一致性的精确控制。
其架构如图所示:
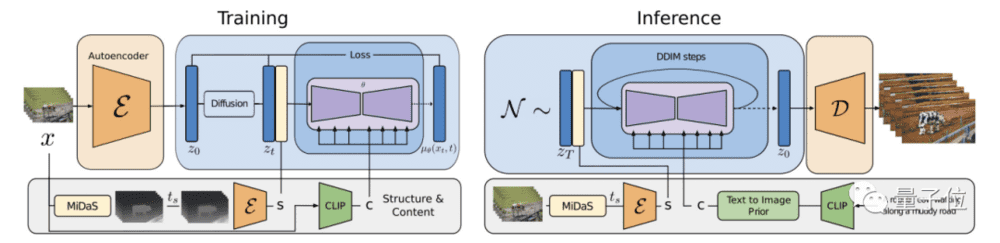
在训练阶段,先用固定编码器将输入视频x编码为z0,并扩散为zt。
然后对MiDaS获得的深度图进行编码,提取出结构表示s;再用CLIP对其中一个帧进行编码来获取内容表示c。
接着,在s的帮助下,模型学习反转潜空间中的扩散过程(其中s与c以及通过交叉注意块生成的c相连)。
在推理阶段,模型以相同的方式提供输入视频的结构s。
为了通过文本生成内容,作者还通过一个prior将CLIP文本嵌入转换为图像嵌入。
最终,Gen1可以生成细粒度可控的视频,也能对一些参考图像进行定制。
不过,一开始对公众发布的Gen1只能对已有视频进行编辑,Gen2才直接完成了文生视频的“蜕变”。
并且一口气带来了另外7大功能,包括文本+参考图像生成视频、静态图片转视频、视频风格迁移等等。
这样的Gen2,也在内测阶段就被网友称赞为“视频界的Midjourney”。
而根据官方的调研数据,Gen2确实更受用户欢迎:用户得分比Stable Diffusion 1.5要高73.53%,比Text2Live则高上了88.24%。
如今正式上线以后,果然迅速迎来一大波体验群众,有人表示:
上一次体会到这么激动的感觉,还是用AI生成图像的时候。
那么,不知道这波,参与开发了SD的Runway,能否再带着Gen2创造生成式AI领域的下一大热趋势。
如果答案是肯定的,还需要多久、还要解决哪些问题?
就且拭目以待。
参考链接:
[1]https://runwayml.com/
[2]]https://research.runwayml.com/gen2
[3]https://twitter.com/SteveMills/status/1666799229996785666
[4]https://twitter.com/runwayml/status/1666429706932043776[5]https://www.youtube.com/watch?v=dq8GZeDEqH8
本文来自微信公众号:量子位 (ID:QbitAI),作者:金磊、丰色