
本文刊登于《北大金融评论》第16期,来自微信公众号:北大汇丰PFR(ID:pfr_2019),作者:魏炜(北京大学汇丰商学院管理学教授)、陈春花、林毓聪、黄洪武、徐明,编辑:杨静雯,原文标题:《魏炜:大模型技术企业的商业模式新选择》,头图来自:视觉中国
凯文·凯利在其撰写的《5000天后的世界》一书的开篇中就写到:“在未来的50年里,AI将成为可以与自动化和产业革命相提并论的,不,应该是影响更为深远的趋势。”按照凯文凯利的判断,未来的这个世界被称为“镜像世界”,在这个世界里,将会诞生“新的巨大平台”。他总结归纳得出如下判断:互联网作为第一大平台,将全世界的信息数字化;社交媒体作为第二大平台,解决了人际关系数字化;继两大平台之后,第三大平台也即将全新登场,即镜像世界,将现实世界全部数字化。
我们认同这一判断,也相信人类正在快速地进入AI世界,并因此更加深入去理解以ChatGPT为标志的人工智能带来的一系列的挑战和机遇。在此时此刻,企业和从业者的兴奋和焦虑、期待和失望、绝望和希望同时并存。如何在大模型时代抓住商业机会,构建独特的商业模式使其在大模型浪潮下依旧能披荆斩棘,是每个企业当下都需要思考的重要命题。
一、大模型时代构建新的力量和财富
自从美国的OpenAI公司发布了ChatGPT之后,通用人工智能(AIGC)达到了发展奇点,这也催生了一系列围绕AIGC的创业热潮。亚马逊首席科学家李沐近日离职,与其导师亚马逊前副总裁Alex Smola一同创业,阿里M6大模型的前带头人杨红霞加入字节人工智能实验室,参与语言生成大模型的研发。阿里VP贾扬清离职创业投身大模型,创新工场董事长兼首席执行官李开复近日宣布将筹组名为“AI2.0”的项目,表示将在全球范围寻找具有 AI大模型、语言生成模型、多模态等领域能力的优秀技术人才和研究员。诸多顶尖行业人才二次创业无不提示AIGC的盛世已在眼前。
人们为什么会如此敏感于大模型带来的变化,并快速投身其中,是源于它会带来新的力量与新的财富,更重要的是产生新的世界格局。想想互联网技术带来的产业与世界的现状,我们可以设想一下,未来的镜像世界中,所有的产业都将再一次被重塑,一方面再一次产生行业的新价值,另一方面加速淘汰落后产能。每个人都将要与智能机器一起生活和工作,并与数百万人一起协同工作,全新的工作方式需要“新人”,也同样有更多的“旧人”被淘汰。世界的格局,也不再是国家与国家相互作用来构建,而需要加上拥有大模型的科技巨头公司,那将是一种前所未有的格局。
二、寻找大模型时代的商业机会
正如我们感知大模型时代来临是从ChatGPT开始的,那么,要寻找大模型时代的机会,我们同样需要从认识OpenAI模式局限性开始。我们以商业机会作为思考的领域,也因此会关注目前领先的OpenAI公司和其他已知拥有大模型技术的公司的商业模式所存在的局限性,通过研究分析和思考,我们认为,OpenAI公司通过直接向订阅的企业客户和C端用户开放ChatGPT3.5/GPT4通用对话大模型接口来获取收入的商业模式,将会面临三方面的局限。
首先,由于用于专业知识训练的语料不够,ChatGPT在专业领域提供的回答通常过于肤浅,无法提供深入的建议和解答且无法溯源,甚至经常存在难以分辨的事实性错误以及生成质量不稳定、逻辑不连贯、重复或不一致的现象,这会导致回答缺乏可靠性,无法满足专业领域对回答质量的高要求。
第二,ChatGPT在专业领域存在隐私漏洞:ChatGPT将提问上传云端,在异地处理并反馈解答。这可能存在用户隐私泄露的危险。同时,ChatGPT将用户的输入作为训练的语料,这也会导致用户的输入信息安全无法得到保证(虽然最近OpenAI已决定不再使用用户数据训练,但此举必将限制OpenAI在专业领域的能力提升)。
第三,更为严重的是,由于用户数据与模型产权均被中心化公司所有,这种模式不能最大程度地激励用户在系统里创造新数据和新知识。
ChatGPT的上述问题是由于领域知识图谱的训练预料不足、闭源模式导致用户信息外泄和用户数据的产权被侵占等固有缺陷导致的,这就给企业通过用多年积累的领域知识对大模型进行微调和优化,从而获得本行业的领域大模型提供了窗口机会。
综上所述,现有OpenAI类公司提供的中心化、一体化、闭源的商业模式存在固有的缺陷,难以在各行各业广泛推广应用。
下面,我们将针对这些局限性提出一种未来可能的发展方向,即基于通用大模型和专业知识图谱构建领域大模型,并由此提出领域大模型的商业模式选择。
三、“生成式大模型+辨识型小模型”,形成领域大模型是出路
正如我们在开篇讨论的那样,随着ChatGPT的横空出世,人们或者因为敏感其带来的机会,或者因为焦虑其带来的颠覆,都在想办法让自己与其发生关联。但是,这是一个从0到1的过程,进入的路径非常多,同时坑也特别多。和之前发生的数字技术背景下生存的芯片、操作系统等领域不一样的地方是,现在没有时间的壁垒,先发者也不会形成累积性的竞争优势,正因为此,其对产业的颠覆也将超乎人们的想象。
在这样的变化特征下,大模型时代的商业模式,需要针对这样的变化特征做出应对,并利用这些变化特征产生新的商业价值机会,因此,需要在现在生成模型的基础上,解决行业知识与时间价值的问题,后者我们发现可以用行业辨识型模型来解决,即必须使用辨识模型来解决生成模型的不足。辨识模型补足的是两个比较重要的方面,一个是业务场景中特有的需求,另一个是结构化知识的生产,类似人类形成长期记忆。长期来讲,两者一定是缺一不可的。
从企业的视角去看,有关企业商业模式的构建,可以确定是一个领域大模型,这一大模型主要由小模型(辨识模型)产生的专业知识图谱、提供通用知识和语言理解与组织能力的大模型(生成模型)两部分组成。小模型的主要功能是基于知识图谱等技术,为大模型提供训练和微调的专业知识,以便生成式大模型进行专业知识的理解。
通用大模型的主要任务是面向客户直接进行语义理解和答案的生成,如闭源的ChatGPT、开源的LLaMA等均属于此类通用模型。我们可以简单介绍一下构建这样一个领域大模型的过程。
第一步是训练基于生成式大模型的自然语言处理模型,其训练主要分为预训练和迭代微调两个步骤。步骤一,预训练阶段,利用海量语料训练生成式大模型,得到大模型的模型文件。步骤二,迭代微调阶段,依据指令提示学习和思维链提示学习对上一步的模型文件进行微调,再通过强化学习的方式,分别进行奖励模型训练和生成策略优化。
第二步是用辨识型小模型生成领域知识图谱。小模型部分本身也是一个针对特定任务的自然语言处理模型,其训练同样分为预训练和微调两个步骤。步骤一,预训练阶段,可以采用BERT、T5等预训练模型。步骤二,微调阶段,利用各种针对不同下游任务的语料对预训练的模型进行特定领域的微调。利用微调后的自然语言处理模型,可以基于语义理解方面的能力,生成特定领域的专业知识图谱。
第三步,分析专业知识图谱,并进一步将从其中得到的专业信息用于大模型部分的增量预训练、微调、校验和溯源,产生具备专业知识能力的领域大模型。
第四步,利用加入了专业知识的领域大模型,实现专业领域的文本解析、报告生成和专业问答,同时也可以解决通用大模型在专业领域的非事实性回答的问题。
不同于行业某些专家认为“不要用知识图谱、它根本不起作用”的观点,我们通过开发实践证明知识图谱,在解决纯生成式大模型(如GPT4)关于事实性问题的缺陷方面不但能发挥关键作用,而且相比于生成式大模型+插件机制的架构(如Bing Chat),经过知识图谱微调、校验和溯源的领域大模型在事实准确率和生成内容的专业性方面有着非常突出的优势。
四、大模型的共生体和商业模式创新
领域大模型在未来拥有更加丰富的商业化场景,这些场景将形成一个如图1所示的大模型共生体。该共生体拥有以下角色和相应的业务活动环节,包括搭建训练框架、输出模型文件、模型微调、私有模型及其部署、开放API、构建知识图谱知识、构建终端应用和提供训练数据等。进入该共生体的企业可以通过选取不同的业务活动并在其中扮演特定的角色,与共生体中的其他主体交易,由此可以衍生出很多不同的商业模式。
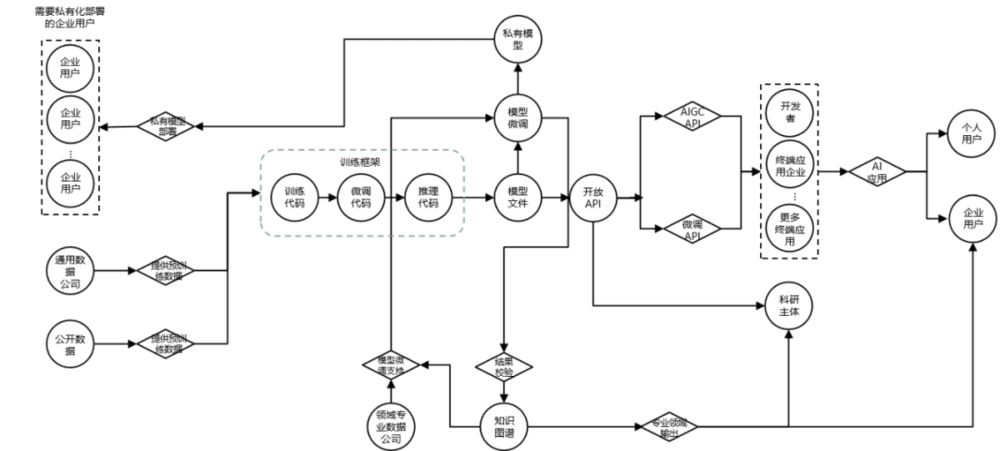
图1 领域大模型的共生体
商业模式创新的起点可以源于对共生体中不同角色的选择,这能够帮助企业定位其边界以及交易的主体。
如下图2所示,这是一个大模型共生体的三轴工具。其中,Y轴代表了上下游直接业务活动,包括了搭建训练框架、预训练、输出模型文件和终端应用等。
X轴是直接业务活动的横向展开,在不同的直接业务活动层面进一步区分出不同的活动。例如,训练框架、预训练数据可以选择是开源、闭源(私有)还是混合;在模型文件环节可以选择GPT-3、GPT-4、Stable Diffusion等不同的训练好的模型参数数据;在终端应用环节可以切入对话、搜索、画图、写作等多样化场景。
除此以外,Z轴代表了业务活动的竖向分层。例如,针对提供模型文件这一业务活动,将已有训练好的模型参数数据当作基础模型,企业可以通过模型微调使用特定领域或任务相关的全量或增量语料,对模型进行进一步训练。在模型微调的基础上企业可以提供客户的私有模型部署,客户将系统的组件和服务部署在自己的私有数据中心或基础设施中,不仅满足了对数据隐私和安全性的要求,还可以进行定制开发以满足特定的业务需求。
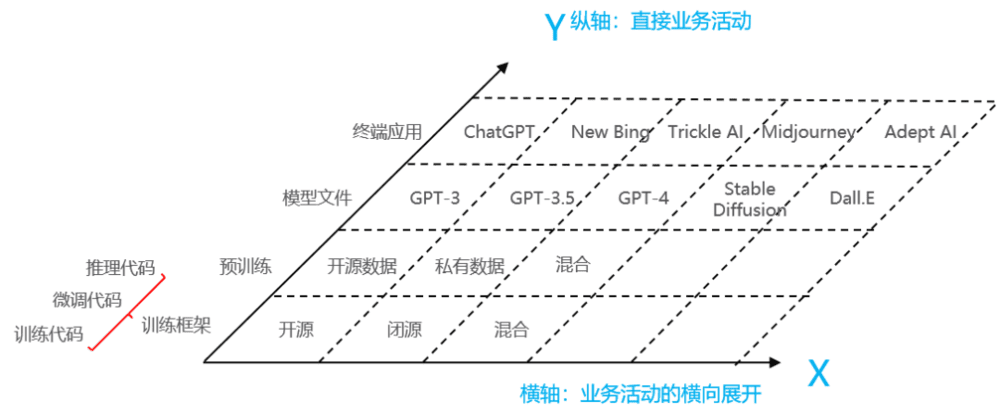
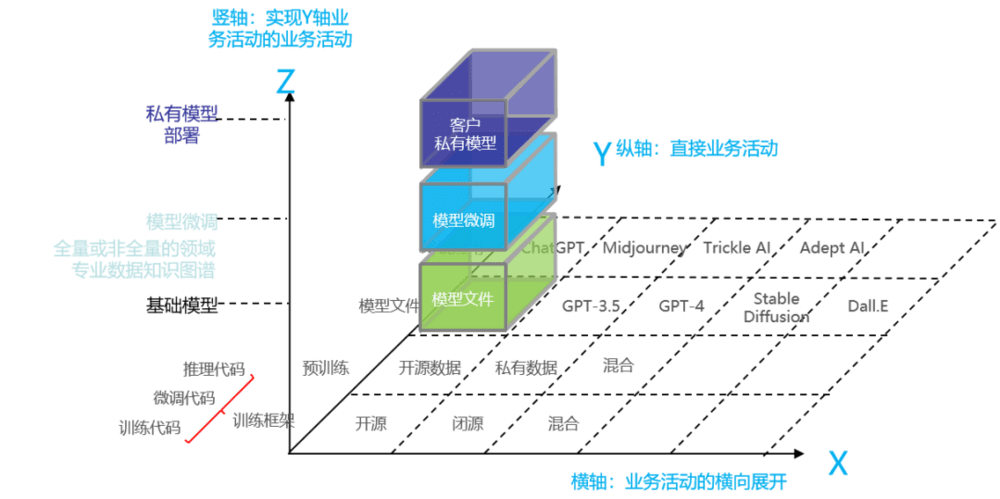
图2 大模型共生体的三轴工具
三个坐标轴充分表达了现有的业务活动。拥有不同初始禀赋、技术优势的企业可以从事共生体中不同的角色,从而采取不同的大模型的商业模式。例如:
模式1,通用大模型训练与提供模型文件的商业模式。企业的主要业务活动选择为基础的通用大模型训练,通过出租或销售通用大模型盈利。
模式2,企业自用领域大模型训练的商业模式。企业在自用场景下,对通用大模型的模型文件进行领域适应性的二次微调,输出一种满足专业企业需求的领域大模型。
模式3,为不同行业提供领域大模型文件的商业模式。企业可以结合领域专业数据公司提供的专业化数据构建领域知识图谱,训练更适用于垂直领域需要的领域大模型。
模式4,结合知识图谱的领域大模型训练的商业模式。这类企业的核心在于承担了知识图谱构建的活动,为某一领域构建更加专业化的解决方案。
模式5,平台型商业模式。这类企业将模型训练的基础设施开放给用户,让用户开发属于自己的领域大模型。
模式6,一体化且可私有化部署的商业模式。企业提供领域大模型或通用大模型,可提供模型文件给用户私有化部署。此模式与现行的OpenAI的API模式相比,能够激励行业客户创造专属的领域大模型。
五、这个路径的选择是普遍可应用的吗?
我们确定“生成式大模型+辨识型小模型”作为大模型时代企业的技术架构及大模型的商业模式选择路径,正是基于对行业发展、技术演进以及企业现状的梳理和判断,更重要的是,企业按照这个选择路径寻找大模型时代的商业模式创新机会,是相对可行且没有太大技术和投入壁垒的。
未来,我们相信基于“生成式大模型+辨识型小模型”技术架构的共生体,及其产生的商业模式将会拥有更广阔的创新发展空间。大量新玩家会通过重新定位、价值链延伸以崭新的身份与角色进入大模型的生态系统。相比于OpenAI的中心化一体化闭源模式,从大模型共生体中衍生出的几种局部闭源或开源模式将更可持续地创造价值。除此以外,也可以广泛地采用区块链技术甚至区块链系统。区块链作为一种去中心化、透明且不可篡改的分布式技术,可以提供一种可靠的方式来确保数据的确权和分配奖励,并记录用户的数据与知识来源、创造时间和所有权信息,通过智能合约来实现自动化的奖赏机制,为数据和知识的贡献者提供激励。
如果一定要探讨实现大模型条件下的商业模式创新的障碍问题,那么主要的障碍是人的思想不能转变过来。在现实的实践中,我们发现,即便是离AI最近的算法工程师,都很难完全理解目前技术上翻天覆地的变化,更何况其他人。而在大模型时代,人们的工作模式将发生根本的变化。新的工作模型,对从业者的要求不再仅仅是个人的胜任力,还要求有协同工作的能力,以及创造力、新的能力要求,一些从业者也许会无法转变到大模型时代所需要的能力结构中。
还有一个障碍是大部分老板对这个更不了解,仅仅知道需要很多资金和资源的投入,并且不一定有当期或者近期的产出,所以一直处在摇摆之中。
其实,后面的这一点,恰恰是我们建议企业选择做领域大模型商业模式创新的原因,因为这样的选择,先从行业的中游、下游去做,既可以发挥企业自身对行业所拥有的优势知识资源,又可以贴近顾客需求端,获得竞争优势。
亚马逊创始人杰夫·贝佐斯曾说过:“亚马逊必然会消亡”。据资料显示,自2000年以来,《财富》500强企业中有52%的公司宣布破产或被收购、兼并,但是,伴随着这些公司的消亡,一大批创新的公司正在茁壮成长,机遇到处都是,只是需要我们能够与机遇走在一起。
本文来自微信公众号:北大汇丰PFR(ID:pfr_2019),作者:魏炜(北京大学汇丰商学院管理学教授),陈春花(新华都商学院理事长、教授),林毓聪(北京理工大学医学技术学院深度学习方向博士后),黄洪武(深圳市司普科技有限公司CTO),徐明(玮锡科技创始人、架构师),编辑:杨静雯