
本文来自微信公众号:硅基研习社(ID:gh_8448ad119f2e),作者:叶子凌,编辑:戴老板,题图来自:《泰坦尼克号》
2015年,两名来自英国的创业者Simon Knowles和Nigel Toon正在为他们的人工智能(AI)芯片项目寻找资金。
负责技术的Simon Knowles于1980年代毕业于剑桥大学,早期在英国政府研究实验室研究神经网络,创办的第一家公司Element 14即成为90年代的独角兽,并在2000年以6.4亿美元的价格出售给博通。而Nigel Toon则是商业人才,在1990年代加入美国科技企业Altera,并在Altera担任欧洲业务的副总裁与总经理。

左:Nigel Toon,右:Simon Knowles(图片来自graphcore官网)
2002年,两人合伙创办了一家叫做Icera的3G modem(蜂窝调制解调器)芯片公司,并于2011年成功地以3.7亿美元的价格卖给英伟达。从风投角度来看,二人的履历应该是最受追捧的团队模板:背景光鲜,能力互补,连续创业,成功套现。
但尴尬的是,专用AI芯片赛道并不被主流VC认可,两人甚至一度找不到投资人开会。
这跟当时人工智能赛道的热闹截然相反。2015年的ImageNet大赛,所有排名靠前的玩家都在使用GPU进行图像识别,距离AlexNet模型第一次利用GPU训练神经网络模型夺冠已经过去了三年,行业内掀起AI热潮。
但实际上,AI在当时只是个业内自嗨的小众热点。Simon和Nigel寻求融资时,一半的投资人问“什么是AI芯片?”另一半投资人认可AI的前景,但对其上游的芯片设计却不感冒,原因是“认为英伟达的GPU可以覆盖行业需求”。[2]
眼看新项目就要胎死腹中,殊不知AI芯片已经走到了黎明时刻。
这一年,谷歌已秘密研发出一款专注于AI领域中机器学习算法的芯片,并将其用在内部的云计算数据中心,以取代英伟达的GPU。2016年5月,这款自研芯片公诸于世,就是大名鼎鼎的TPU。这名字一出来,内行外行都看懂了:GPU并不是AI芯片的唯一选择,新的处理器设计可能存在市场空间。
TPU的推出也给两位创业者带来了信心。一个月后,Knowles和Toon的AI芯片公司:Graphcore正式成立,由Nigel Toon担任CEO,Simon Knowles担任CTO。
Graphcore火速筹到的A轮3200万美元,于2016年10月到位。在随后的四年里,其融资进程也是一路狂飙:2020年12月,E轮融资落地。Graphcore四年间共获投7.1亿美元,市值27.7亿美元,一跃成为融资和估值最高的AI硬件初创公司,投资者包括三星、微软、戴尔等科技巨头,也包括红杉资本、柏基投资(Baillie Gifford)等顶级风投。
成功“上岸”的Simon Knowles自然是吃水不忘挖井人,特地给谷歌AI业务的负责人Jeff Dean写了一封感谢邮件,内容是[1]:“同志,谢谢你!”(Thanks, mate.)
如果站在今天的时间点,Jeff Dean可能会回复一句:别高兴得太早。
产品:专为AI加速而生的芯片
Graphcore的核心产品叫做IPU(Intelligence Processing Unit)。
IPU诞生的背景是,随着芯片制程的迭代,半导体行业的两大定律——摩尔定律和登纳德缩放比例定律(Dennard Scaling)在逐渐失效。
摩尔定律说的是:集成电路上可以容纳的晶体管数目大约每经过18个月到24个月便会增加一倍。登纳德缩放比例定律认为随着晶体管密度的增加,单个晶体管的功耗会下降,因此芯片的功耗需求会保持不变。
这两条定律都曾在过去几十年被行业视为金科玉律,GPU和CPU的发展都受益于此。但今天的情况是,芯片上晶体管很难再增加,而芯片的功耗需求也变得越来越高,芯片本身就越来越烫。
因此,就像香港的房屋一样,在面积有限的情况下想要提高生活质量,势必要在布局结构上大动干戈,市场上关于“架构创新”的呼声越来越大。专用计算芯片(ASIC)的需求应运而生,因为针对具体应用场景的优化,可以比通用计算带来更高的能效比。
ASIC的特点是彻底牺牲通用性,换取在特定应用上的极致效率。举一个通俗的例子比喻:
GPU是能提供汉堡、披萨、包子、面条等所有食物类目的综合餐厅,优点是什么都会做,缺点是特别出彩的产品,出餐效率也一般。而ASIC是专做披萨或汉堡的美食专门店,味道极好,出餐效率也特别高,缺点则是想转型做其他产品,就没那么容易了。
TPU就是典型的ASIC,它专为谷歌的超级业务云计算数据中心而生。事实上,谷歌自研TPU的原因之一,就是因为GPU会“烧”。
不过,和ASIC相比,IPU有更大的野心。
按照Nigel Toon的话来说,Graphcore不属于CPU、GPU和ASIC中的任何一类,而是一款全新的,专为AI加速而生的处理器:既有极高的运算能力以处理高性能计算业务(HPC),又和GPU一样可编程,以满足不同的场景需求。[3]
Graphcore的IPU主要有三个特点:
图片来源:Graphcore官网
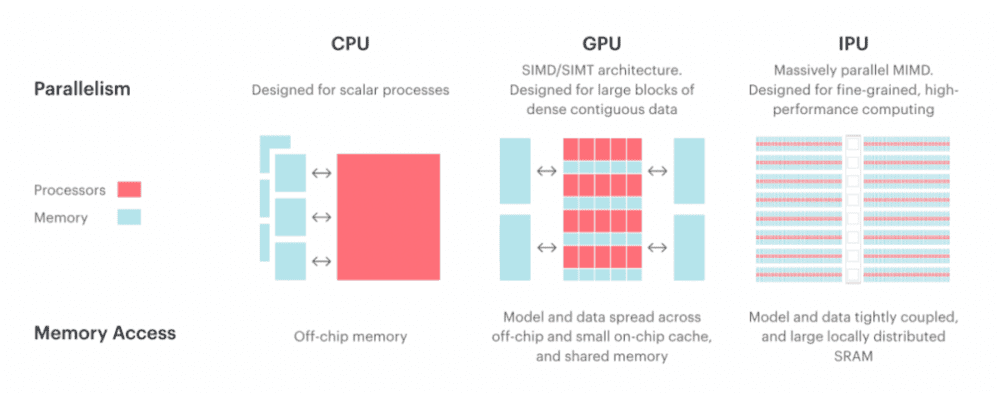
1. 计算核心有多达 1400 多个处理器内核,每个内核可运行 6 个线程。
内核数量的意义在于体现芯片的计算能力,二者呈正相关。每个内核里都有一个计算单元(ALU),业界有一个非常典型的比喻:CPU就是一名会高等数学的大学生,会解复杂题型,而GPU和IPU是成百上千个中学生,精通加减乘除。
在AI深度学习所需要的恰恰是大量简单特定的运算,也就是“加减乘除”。在这种情况下,成百上千个中学生加在一起的效率,比一个优秀的大学生更高。
而IPU和GPU的核心区别在于,处理器核采用了不同的架构。延续上文的比喻,两支中学生团队使用不同的计算方法。
GPU使用的SIMD架构通常用于处理器执行大量计算的问题,这些计算需要处理器并行执行相同命令,就像划船比赛中,所有队员做同样的事,共同提高团队效率。
而 IPU使用的MIMD则将复杂算法分割为无关的、独立的部分,每个部分分配给一个不同的处理器来并发处理的解决方案,好比足球比赛中,队员们虽然有同样的进球目标,但是每个人承担的职责不同。[4]
因此,IPU用到的MIMD架构能够处理更复杂的操作。

图左:SIMD架构的工作方式(GPU);图右:MIMD架构的工作方式(IPU)
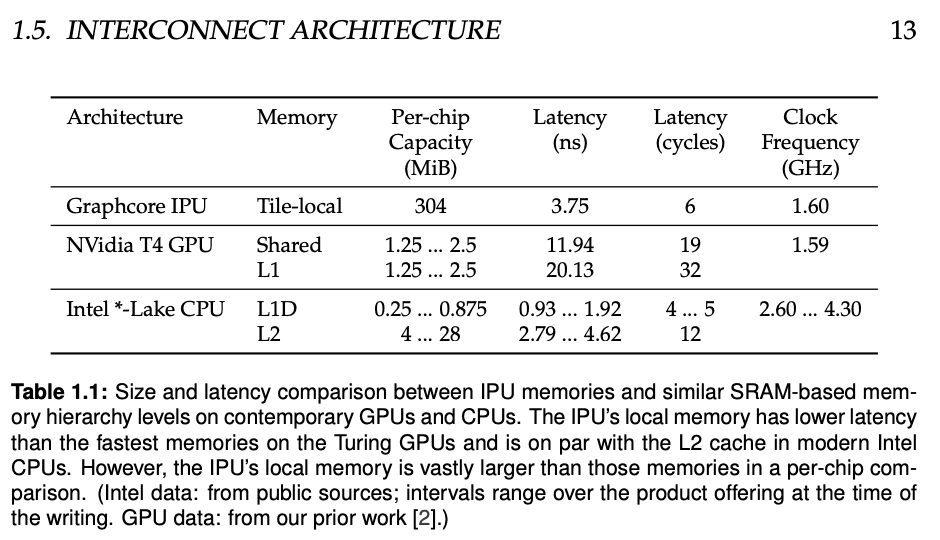
2. IPU采用处理器片内分布式存储架构,而GPU采用显存或高宽带显存HBM,是片外的大型存储。
与GPU的存储架构中直接连接动态随机存储器(DRAM)相比,处理器的内存由IPU的本地静态随机存储器(SRAM)组成,每个内核(tile)都执行只在本地内存上进行的计算。[5]
这样可以避免了频繁访问外部存储资源,大幅度提升频宽、降低延迟和功耗,在特定情境下甚至可能会有近50倍的增幅。[6]
图片来源:Citadel Securities Technical Report
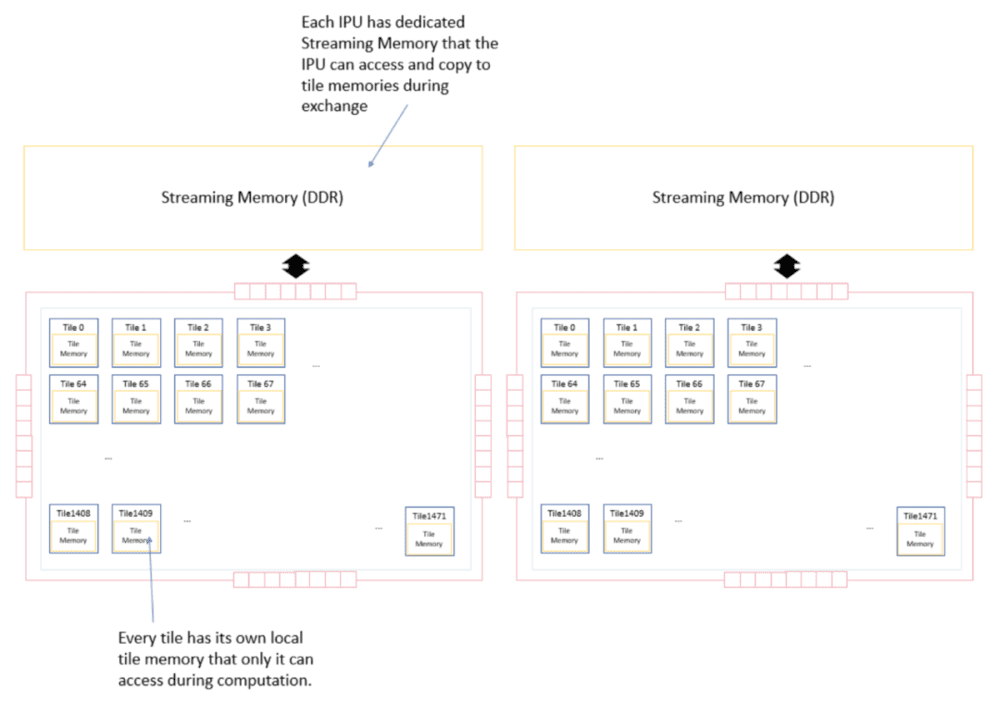
3. 在跨芯片多核通信调度设计上, Graphcore IPU设计了BSP(Bulk Synchronous Parallel)的软硬件结合算法,让芯片内1000多个内核,以及多芯片可以跨IPU连接。
而GPU是以多核多线程呈现,开发者需要处理不同线程之间的通信与数据同步问题。简而言之,对软件工程师或者开发者来说,采用BSP后的AI芯片非常易于编程。[8]
IPU的架构 图片来源:Graphcore官网
定位:和英伟达的竞争和差异化
在技术负责人Simon Knowles眼里,与英伟达展开全面竞争,实在不算一件聪明的事。
在接受海外博客节目The Robot Brains Podcast的采访时,他分享了自己的创业准则:绝不试图生产大公司现有产品的强化版。[9]因为大公司有庞大的市场基础,初创企业在同一产品上很难与之抗衡。
Simon的观点是:AI会存在于人类未来技术的任何领域,而所有行业的需求不可能由同一个架构来支持。而对于Graphcore来说,IPU只需要在特定领域表现得比GPU好,在这个爆炸式增长的市场中分到一杯羹就足够了。
正如上文所提及,由于MIMD架构下的芯片能够处理更复杂的操作,IPU对于目前在CPU和GPU上无法最佳运行的高性能计算任务具有吸引力。其中有关“稀疏数据”的处理就是它最主要的应用方向。
稀疏数据是指在数据集中绝大多数数值缺失或者为零的数据,比如在电商平台,相对海量商品而言,每个消费者购买的只是小部分产品,所以单个消费者的购买记录就是一个稀疏数据。
在现实生活中,就常常要在海量的复杂信息中寻找指定关键信息,因此有关稀疏数据的计算非常普遍,而IPU能够独立和并行地执行许多非常不同的计算,恰符合稀疏计算的特点。
其中,分子就是稀疏数据结构最典型的应用案例。分子排列不规律,行为复杂,而且很小。而IPU大规模并行结构的特征,恰恰适合操作不规则的数据结构。[9]
具体到行业,IPU在化学材料和医疗领域都能得到应用,还曾被证明可用于辅助研究冠状病毒。
2020年5月,微软机器学习科学家Sujeeth Bharadwaj就曾将Graphcore IPU内置于微软Azure操作系统中,并在胸部X光片中识别新冠[11]。他说:“Graphcore芯片可以在30分钟内完成在英伟达传统芯片上需要5个小时才能完成的工作。”
在商业模式上,Graphcore不直接对外销售芯片,而是将IPU内置于叫“pods”的系统中,打包出售给下游的云计算和服务器厂商。
微软作为Graphcore的投资人之一,在2019年第一款IPU产品发布时就已成为其最早使用的客户。而另外一个大股东戴尔也鼎力支持,第一批用上了IPU。
除了自家投资人捧场,Graphore的主要客户是欧洲的厂商。作为欧洲唯一的AI独角兽,难免要打着“国货之光”的招牌向欧洲乡亲拉票。
2018年The Wired采访人工智能大师Geoff Hinton,Hinton帮Graphcore做了一次超级公关,他对记者说:“我认为我们需要转向不同类型的计算机。幸运的是,我这里有一个。”然后伸手进入他的钱包,拿出一个又大又亮的芯片,这个芯片就是Graphcore的IPU。
2021年,Graphcore与法国超级计算机制造商Atos和超级计算机芯片设计公司SiPearl都展开了合作,还在英国爱丁堡大学的EPCC超级计算中心安装了基于IPU的Bow Pod系统。[12]
2022年6月,Graphcore又与德国框架供应商Aleph Alpha签署协议,共同研究下一代多模态语言和视觉模型的预培训、微调和推断。与德国合作后,欧盟还特地强调,欧洲供应商需要这样一条供应链,而不是依赖英伟达等美国公司的人工智能[13]。
一个自主可控的“欧洲英伟达”,这个梦想无比性感。那些当年想做“欧洲谷歌”“欧洲苹果”“欧洲亚马逊”的人也曾经这样幻想过。
触礁:Graphcore面临的问题
Simon说[9]:“如果你打算开发一种新型处理器,真的需要有一个20年的长远视角。”不过,就算在技术层面规划了未来20年。但在商业层面,却未必过得好眼下这两年。
2022年10月,英国《泰晤士报》突然爆出,Graphcore和微软的合作已经泡汤了[14]。此前,IPU被内置于微软Azure平台上, 而现在可以明确的是,目前微软Azure平台上所用的AI芯片基本都来自英伟达,而且微软已经自己下场做AI芯片了。

图片来源:The Times
2023年4月18日,著名科技媒体The Information爆料:微软正在秘密研发自己的AI芯片,代号雅典娜(Athena)[18]。
雅典娜芯片由台积电代工,采用5nm先进制程。据悉,微软从2019年就开始研发这款芯片,目前已在测试阶段。雅典娜的首个目标是为OpenAI提供算力引擎,以替代昂贵的英伟达A100/H100,节省成本。而下一步,可能就将剑指Azure云服务,瓜分英伟达的蛋糕。
缺少大客户的采购,Graphcore的业绩一路低迷。外媒报道,2021年,Graphcore销售额仅为500万美元,税前亏损1.835亿美元。账目显示,截至2021年底,现金、现金等价物和短期投资为3.27亿美元。[15]
这导致英美的顶级风投都抛售了Graphcore的股份,Baillie Gifford减记对其1660万美元的投资,减记幅度达58%,红杉资本也有类似的减持操作[16]。这给Graphcore带来的直接影响是估值暴跌10亿美元,与巅峰时期的28亿美元相比,减少了35%。
Graphcore的困境揭示了一个残酷的事实:初创公司挑战英伟达帝国,是一件如登天一样难的事情。
一方面,英伟达通过CUDA平台、TensorCore、NVLink等技术来不断巩固GPU的护城河,尤其是CUDA生态,连Intel和AMD这种大厂都难以逾越,中小客户几乎没有放弃英伟达、押注新玩家的可能。
而对于想降低成本、增加对英伟达谈判能力的大厂,他们基本上都有能力组织资源自研AI芯片,谷歌、微软、亚马逊、特斯拉都已经入局,国内华为、阿里、百度也都在开发自己的AI芯片。
尽管IPU的诞生源于处理器设计空间具有新的“可能性”,但在眼下混沌又激烈的AI军备竞赛中,芯片客户更需要“确定性”。
有投资人曾对外媒UK Tech News表示,“人们对英伟达的关注度很高——人们希望使用他们的技术,因为这是安全的赌注。要把人们的注意力从这上面转移开,是一个非常非常艰巨的挑战。”[16]
投资者也在用脚投票。截至2022年12月5日,2022年全球半导体初创企业的风险投资达到78亿美元,这与2021年创纪录的145亿美元的投资额相比下降了46%,即便是与2020年103亿美元相比也下降了24%。
Graphcore的融资神话止步在2020年末。但见GPU笑,哪闻IPU哭。
今年,ChatGPT火爆,英伟达狂飙。而Graphcore的CEO Nigel Toon却心灰意冷地向英国政府发出一封公开信,希望政府“抵制外国大型科技公司的诱惑,它们正试图排挤我们的英国公司”。
更具体一些,他直接点名道姓了英伟达。Toon说:“除非预算的很大一部分明确指定给英国供应商,否则这笔资金承诺将很快被美国芯片制造商英伟达等数字巨头消耗掉。”
Toon认为,英伟达等公司凭借其主导市场份额的优势,一直在以低成本提供GPU,以激励英国研究人员使用这些GPU,这种方式塑造了人工智能从业者和研究人员的习惯,并排斥了其他硬件供应商。因此,他呼吁英国政府,将耗资9亿英镑的新超级计算机项目使用Graphcore芯片。
一家诞生于老牌资本主义国家的公司,竟然主动呼吁本国贸易保护、封禁对手,说明事情已经到了绝望的地步。
尾声
除了Graphcore之外,还曾涌现出不少中小AI芯片公司,比如Cerebras、Habana Labs、Mythic等。其中Habana Labs的结局可能算得上最好——被英特尔以20亿美金收购。
中小AI芯片公司所面临的问题跟Graphcore类似:英伟达帝国坚不可摧,大客户自研暗流涌动,人工智能行业一日千里,技术路线像六月的天气一样变化多端,能从英伟达碗里夺食的可能只有像谷歌和微软这样的大厂。
半导体行业的金科玉律是:规模效应,芯片产量越大,芯片价格越低。英伟达和Graphcore等设计公司虽然没有重资产的Foundry产线,巨额的研发费用同样也是一种“重资产”,出货1万片和出货100万片的企业成本相差悬殊。
中国的寒武纪相比英国的“寒武纪”,一个优势就是英伟达的最先进芯片如A100和H100根本卖不进来,只能卖阉割过后的A800。Nigel Toon梦寐以求的“贸易保护”,在中国厂商这里反而能轻松获得。
但抛开这点优势,国内AI芯片公司所面临的问题和Graphcore并无二致。即使是残血的A800,在今年春节后也被国内大厂疯狂抢购。OV小米可以无障碍地购买高通最新款消费级芯片,国内AI大厂却不行,因此他们自研AI芯片的决心会比谷歌和微软更大。
所以,无论是国内还是国外,各种“xPU”们想来分英伟达的羹,都没那么容易。
参考资料
[1] 全球CEO峰会重磅演讲者:Graphcore CEO:Nigel Toon的英国情结,EE Times China
[2] NVIDIA and the battle for the future of AI chips,Wired
[3] Graphcore的AI芯片什么水平?MLPerf告诉你,半导体行业观察
[4] Differences Between SIMD and MIMDMitchell White
[5] IPU Programmer's Guide,graphcore官网
[6] 摩尔定律放缓,靠啥提升AI晶片运算力?EE Times Taiwan
[7] Dissecting the Graphcore IPU Architecture via Microbenchmarking,Citadel Securities Technical Report
[8] 直击CPU、GPU弱项!第三类AI处理器IPU正在崛起,雷峰网
[9] Simon Knowles on pushing AI computing to the limit by rethinking chips,The Robot Brains Podcast(视频)
[10] NanoBatch Privacy: Enabling fast Differentially Private learning on the IPU,Edward H. Lee等
[11] Microsoft detect Covid-10 in chest X-rays in 30 mins on IPU,Graphcore官网
[12] Graphcore signs strategic deal with Atos,EE News Europe
[13] Graphcore aims at European AI supply chain with German deal,EE News Europe
[14] Graphcore value crashes by $1bn after Microsoft deal is axed,The Times
[15] AI 'unicorn' Graphcore set to cut jobs, EE News Europe
[16] Graphcore loses Microsoft deal as key investors write down stake value,UK Tech News
[17] Using the Graphcore IPU for traditional HPC applications,Thorben Louw,Simon McIntosh-Smith
[18] Microsoft Readies AI Chip as Machine Learning Costs Surge,the information
本文来自微信公众号:硅基研习社(ID:gh_8448ad119f2e),作者:叶子凌,编辑:戴老板