
本文来自微信公众号:深思圈 (ID:gh_352a572cf923),作者:Maithra Raghu(Samaya AI)、 Matei Zaharia(Databricks)、Eric Schmidt(Schmidt Futures),编译:深思圈,头图来源:视觉中国
今天看到了一篇不错的文章《Does One Large Model Rule Them All? Predictions on the Future AI Ecosystem》,这篇文章的三位作者都是大佬级的人物,分别是谷歌前CEO Eric Schmidt、Databricks的首席科学家同时也是斯坦福教授的Matei Zaharia和Samaya AI创始人Maithra Raghu。这篇文章从一个大模型是否会吃掉整个AI生态的问题出发,用Workflow(工作流)和Value(价值)这两个衡量标准来预测未来AI生态格局。以下是这篇文章的中文翻译,基本都由GPT-4完成,希望给大家有所启发和思考。
过去的10年里,人工智能不断取得进展,每一波新的发展都带来了令人兴奋的新功能和应用。最大的一波无疑是最近出现的单一通用人工智能模型,例如大型语言模型(LLMs),它们可以用于执行多种多样的任务,从代码生成、图像理解到科学推理等。
这些任务的执行质量之高,以至于一整代新的技术应用正在被定义和开发。尽管考虑到潜在的影响,这令人兴奋不已,但这种飞速的成功确实让我们对未来的人工智能生态系统产生了一个深度的不安问题:
未来的人工智能领域是否会被单一通用AI模型所主导?
具体来说,未来的人工智能领域是否会:
由少数(<5)公司拥有的大型通用AI模型主导?
这些通用AI模型是否会成为驱动所有重要技术AI进步和产品的关键组件?
随着类似ChatGPT和GPT-4等模型的发布,这些模型已经改变了我们对AI能做什么的理解,以及开发这类模型的成本不断上升,这已经成为一种普遍的观点。
然而,我们持相反的看法。
将会有很多公司为AI生态系统的发展做出贡献。
并且,许多具有高实用性的AI系统将出现,它们将不同于(单一)通用AI模型。
这些AI系统在结构上将非常复杂,由多个AI模型、API等驱动,并将推动新的技术AI发展。
针对明确定义的、高价值的工作流程,主要将由专用AI系统而非通用AI模型来解决。
我们可以用以下示意图来说明我们对AI生态系统的预测:
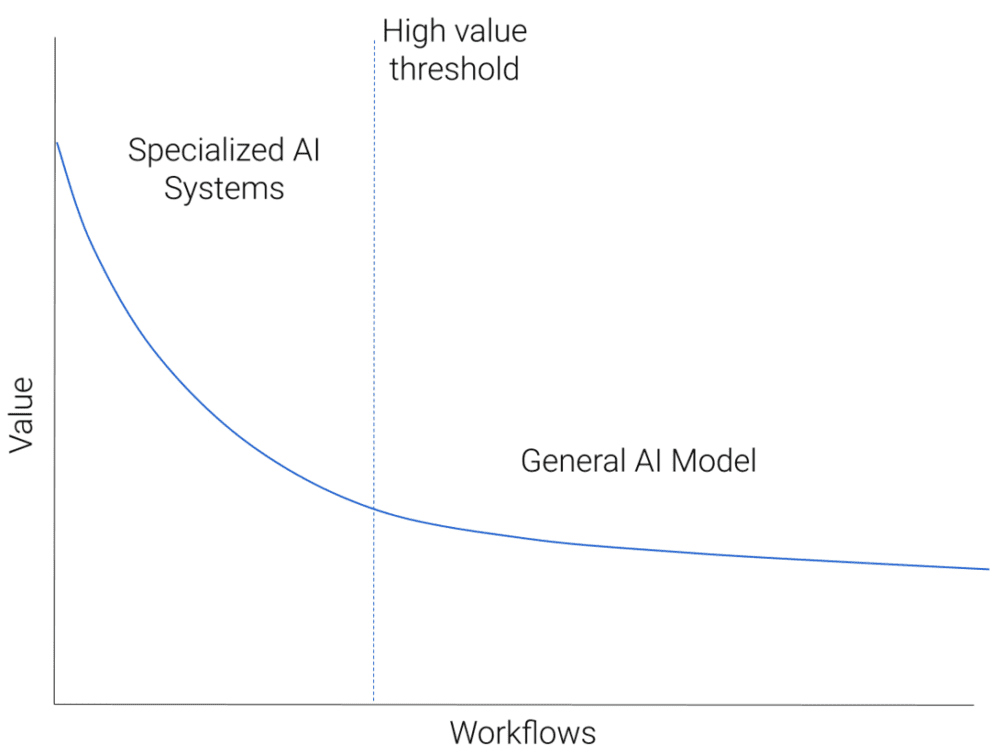
假设,我们将所有适用于基于AI的解决方案的工作流程按照“价值”降序排列。价值可以是潜在收入,也可以是对用户的实用性。会有少量非常高价值的工作流程,例如一个庞大的市场或者拥有大量用户且明确可通过AI解决的痛点。这将衍生出一长串繁杂但价值较低的工作流程,代表了许多AI可以协助的定制预测任务。
高价值工作流程的例子有哪些?虽然还很早,但我们已经看到了编码助手、视觉内容创作、搜索和写作助手等方面的令人兴奋的发展。
那么,低价值工作流程的重尾部分呢?这些将是不太明确的定制需求,源于特定的情境。例如,通过分类对客服机器人的请求进行分级处理。
我们预测,在图表的左上角(高价值工作流程)将由专业化AI系统主导,随着我们沿着蓝色曲线下降至较低价值的工作流程,通用AI模型将成为主导方法。
乍一看,这个画面似乎违反直觉。一些最先进的AI能力似乎来自通用模型。那么为什么这些模型不主导高价值工作流程呢?但是,通过思考生态系统可能的演变,有一些重要因素支持这个观点,我们将在下面详细展开。
一、专业化对于质量至关重要
高价值工作流程需要高质量,并奖励任何质量的提升。应用于高价值工作流程的AI解决方案会不断调整以提高质量。由于工作流程特定的问题导致质量差距,这种调整将导致专业化。
专业化可以简单地通过针对特定工作流程的数据进行调优,或者(更可能)开发多个专业化的AI组件。
我们可以通过考虑当前用于自动驾驶汽车的AI系统来具体说明。这些系统有多个AI组件,从规划组件到检测组件,以及数据标注和生成组件。将这个专业化的AI系统用类似GPT-4的通用AI模型替换,将导致质量急剧下降。
但是,更先进的通用AI模型,如GPT-(4+n),能否战略性地执行此工作流程?
我们可以进行一个思维实验来展示这可能如何发展:
假设GPT-(4+n)发布,具有非常有用的功能,包括自动驾驶。
我们无法立即替换整个现有系统。
因此,我们确定GPT-(4+n)最有用的功能,并考虑将其作为另一个组件添加进来,可能是通过API调用。
然后对这个新系统进行测试,不可避免地会发现质量差距。
有压力要解决这些差距,由于它们来自特定的工作流程(自动驾驶),因此会开发特定于工作流程的解决方案。
最终结果可能是用一个新的、专门的AI组件完全替换API调用,或者与其他专门的组件一起增强。
虽然这个思维实验可能不完全准确,但它说明了我们可能从通用AI模型开始,然后大量地专门化它以提高质量。
总之:(1)高价值工作流程的质量很重要;(2)专业化有助于提高质量。
二、充分利用用户反馈
与质量考虑密切相关的是用户反馈的作用。有明确证据表明,在高质量的人类“使用”数据(例如偏好、指令、提示和响应等)上进行仔细调整,对于推动通用AI模型的能力至关重要。
在大模型中,诸如RLHF(从人类反馈中学习强化学习)和监督学习在类似人类的指令/偏好数据上已经在获取高质量生成和指令执行行为方面发挥了关键作用。这在ChatGPT中得到了显著证明,现在正在推动许多大模型的发展。
同样,我们期望用户反馈在推动特定工作流程的AI能力方面发挥关键作用。但是,有效地整合这些反馈需要对AI系统进行细粒度的控制。我们不仅要仔细调整基础模型以适应用户反馈(由于成本和有限访问权限,通用AI模型难以实现),而且可能需要调整整个AI系统的结构,例如定义数据、AI模型和工具之间的互动。
为通用AI模型设置这种细粒度控制在工程(多样化的微调方法、API调用、处理不同的AI组件)、成本(大型模型调整昂贵)和安全性(参数泄露、数据共享)方面具有挑战性。
总之,实现用户反馈所需的细粒度控制更容易在专门的AI系统中实现。
三、专有数据和专有知识
许多高价值、领域特定的工作流程依赖于丰富的专有数据集。针对这些工作流程的最佳AI解决方案需要在这些数据上进行训练。然而,拥有这些数据集的实体将专注于保护其数据壁垒,不太可能允许第三方进行AI训练的非联合访问。因此,这些实体将在内部或通过特定合作伙伴建立专门针对这些工作流程的AI系统。这些系统将与通用AI模型不同。
与此相关的是,许多领域还使用专有知识——仅由少数人类专家了解的“商业秘密”。例如,台积电(TSMC)用于尖端芯片制造的技术,或顶级对冲基金使用的定量算法。利用这种专有知识的AI解决方案将再次在内部建立,专门针对这些工作流程。
这些是许多先前技术周期发生的“建设与购买”计算的例子,同样也会在这个波浪中重现。
四、AI模型的商品化
与开发昂贵的专有模型(如GPT-4)的努力同时进行的是构建和发布AI模型,然后迅速优化。这些是
(1)基于成本的效用和(2)效率之间激烈竞争的例子。
效率是指在保持效用的同时,快速降低新AI技术的成本。这是由于以下几个关键属性:
AI领域深厚的合作、发表研究和开源传统,使技术见解的知识传播迅速。
受欢迎的AI模型的计算成本迅速降低,原因是硬件、基础设施和培训方法更优越。
收集、整理和开源数据集的努力有助于民主化模型构建并提高质量。
对于我们目前最强大的模型,效率似乎最可能在竞赛中获胜,从而导致这些模型的商品化。
五、通用AI模型的未来?
但是,这是否意味着所有大型通用AI模型都将被商品化?
这取决于另一个竞争者,基于成本的效用。如果AI模型有用但成本也很高,那么效率过程就需要更长的时间——前期成本越高,降低成本所需的时间就越长。
如果成本保持在今天的范围内,那么我们很可能会看到完全的商品化。
如果成本增加了一个数量级,但效用呈递减趋势,那么我们同样会看到商品化。
如果成本增加了一个数量级,并且效用成比例增加,那么很可能会有少量非常高成本的通用AI模型,而不是商品化。
哪种情况最有可能发生?
很难确切预测。未来的AI模型肯定有用更大量/类型的数据和增加计算的空间。如果效用也继续增加,我们将拥有少量昂贵的通用AI模型,用于处理大量多样化、难以定义的工作流程,如上图所示——这对AI来说就像云对计算所做的那样。
总结
尽管经历了长达十年的AI进步浪潮,AI的未来仍然比过去更多姿多彩!我们预计一个丰富的生态系统将出现,其中包括各种高价值、专业化的AI系统,由不同的AI组件驱动,以及少量通用AI模型,支持大量多样化的AI工作流程。
参考材料:[1]https://maithraraghu.com/blog/2023/does-one-model-rule-them-all/
本文来自微信公众号:深思圈 (ID:gh_352a572cf923),作者:Maithra Raghu(Samaya AI)、 Matei Zaharia(Databricks)、Eric Schmidt(Schmidt Futures),编译:深思圈