
本文来自微信公众号:量子位 (ID:QbitAI),作者:魏亦豪,题图来自:《天才枪手》
GPT-4太强,甚至已经化身“主考官”了!
给其他市面上主流的大模型打分,结果自己给了自己最高分:95.5。(好,给自己留点努力的空间)
不过随后就没有上90的选手了。就连它的“前辈”ChatGPT(GPT-3.5,下同),它也只给了89.1分。
随后依次是号称最强竞品的Claude、谷歌Bard、UC伯克利出品的小羊驼Vicuna-13B,以及清华系开源模型ChatGLM-6B。

话不多说,速来围观GPT-4到底是如何评测的?
10项能力测评
首先,来看出题人GPT-4到底想考察语言模型的哪些能力。
要求出题尽量全面,考察模型能力的不同方面,并且足够难,使得不同水平的模型有足够的区分。
于是GPT-4直接出了10道题,而且还分别告知了出题理由——具体考察了大模型什么能力,可以说是很全面了。

问题1:请简要概述小说《杀死一只知更鸟》的情节,并指出其中的主要主题。
理由:这个问题测试了模型理解和总结复杂叙事结构的能力,以及对文学作品中的主题和主旨的理解。
问题2:描述傅里叶变换的主要数学原理,并用一个简单的例子说明其应用。
理由:这个问题测试了模型以简单、易懂的方式理解和解释复杂概念的能力。
问题3:以“春天”为主题创作一首押韵的诗歌。
理由:这个问题测试了模型的创造性和艺术能力,以及理解主题和生成具有上下文关联的内容的能力。
问题4:指出资本主义和社会主义之间的主要区别,并举例说明哪些国家在历史上分别遵循了这两种经济体系?
理由:这个问题测试了模型理解和总结复杂社会和政治概念的能力,并提供事实性的历史背景。
问题5:能否为解决笔记本电脑上的Wi-Fi连接问题提供一个详细的、分步骤的故障排除过程?
理由:这个问题测试了模型在提供实用的解决问题建议和理解技术概念方面的能力。
问题6:根据当前的趋势和技术发展,我们可以预期在未来十年里会有哪些重大进步?
理由:这个问题测试了模型从现有知识和趋势中推断和预测的能力。
问题7:请检查以下代码片段:
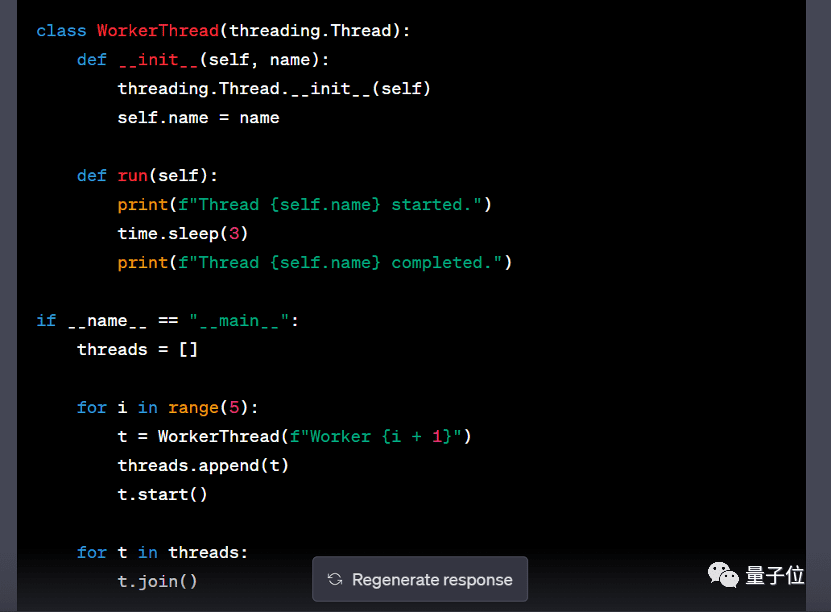
找出任何可以优化以提高性能的部分,并提出如何提高代码可读性的建议。
理由:这个问题测试了模型在编程及软件开发中理解、分析代码并提供改进建议的能力。
问题8:简要讨论与人工智能相关的伦理问题,特别是在个人隐私和就业方面。提供例子以证明您的观点。
理由:这个问题测试了模型讨论伦理问题和理解技术进步可能带来的后果的能力。
问题9:描述植物光合作用的过程,详细说明其中涉及的关键步骤和组成。
理由:这个问题测试了模型准确、深入地理解和解释复杂科学过程的能力。
问题10:给定一段包含讽刺或幽默的文本:“哦,太好了,又一个据说能理解讽刺的语言模型。我敢肯定这将是一次扣人心弦的对话。” (Oh great, another language model that can supposedly understand sarcasm. I’m sure this will be a riveting conversation.)你能识别出讽刺或幽默的元素,并提供一个适当的回应吗?
理由:这个问题测试了模型理解微妙语言 (如讽刺或幽默)的能力,这是自然语言理解的一个重要方面。
可以看到GPT-4的出题范围,基本上涵盖了文字、数学、诗歌、经济、实践、技术、代码、道德伦理、科学,语言等各个方面。
随后针对不同问题,我们又让GPT-4生成了相应的评分标准(0-100)。



题目有了,评分标准也有了。
既然如此,那就来看看这几个代表大模型的实力如何?
GPT-4:Claude仅次于ChatGPT
首先有请考生登场:
谷歌Bard、最早也是最强竞品Claude、UC伯克利小羊驼Vicuna-13B、清华系开源模型ChatGLM-6B。
ChatGPT(GPT-3.5)与GPT-4自己,也被要求回答这些问题,然后由GPT-4依据前面的评分标准盲评。
首先来看这道题:
请简要概述小说《杀死一只知更鸟》的情节,并指出其中的主要主题。
这第一题在所有问题中算是比较简单的,首先让我们看看bard的回答。

总结:《杀死一只知更鸟》是哈珀·李1960年出版的一部小说,讲述了在美国大萧条时期阿拉巴马州一个虚构的小镇上,一位名叫阿提克斯·芬奇的律师为一名被错误指控的黑人辩护的故事。小说探讨了种族主义、勇气、捍卫正义的重要性以及失去天真的主题。主人公阿提克斯·芬奇勇敢地为被冤枉的黑人站出来,成为了他的孩子们心目中的榜样。通过这部小说,孩子们认识到世界并非总是公平的,但仍有善良的人存在,我们应该永不放弃希望。
结果GPT-4对这个回答评价很高,并给出了100分的高分:

所提供的回答清晰准确地概括了《杀死一只知更鸟》的情节,并指出了主要主题。情节概括简洁明了,捕捉到了故事的核心元素。主题解释得很好,它们与小说的关联显而易见。
得分:100/100
同样的问题给到GPT-4的回答也拿到了满分,而ChatGPT、Claude、Vicuna的回答分数分别为95、96、90,可以说是在统一水准上,都提供了清晰准确的情节概括,涉及到故事中的主要事件和人物,同时也捕捉到了小说中的主题。回答简洁且条理清晰,使得对于可能不熟悉故事的读者也容易理解。
相比之下,GPT-4认为ChatGLM给出的答案并不尽如人意。

GPT-4认为相关情节和人物存在错误信息。这个概括并没有准确地反映小说的内容,部分提到的主题与故事无关,因此只给了20分。

再来看看各个模型在代码方面的能力,这也是目前评判大模型能力的重要标准——
请检查以下代码片段,找出任何可以优化以提高性能的部分,并提出如何提高代码可读性的建议。
在这一题上GPT-4仍然拿到了95的高分:


可以看到,GPT-4首先分析了这段代码的用途和实现方式,随后提出了一些提高代码性能和可读性的建议。不仅如此,GPT-4还给出了修改后的代码,可以说是答得非常完善了:
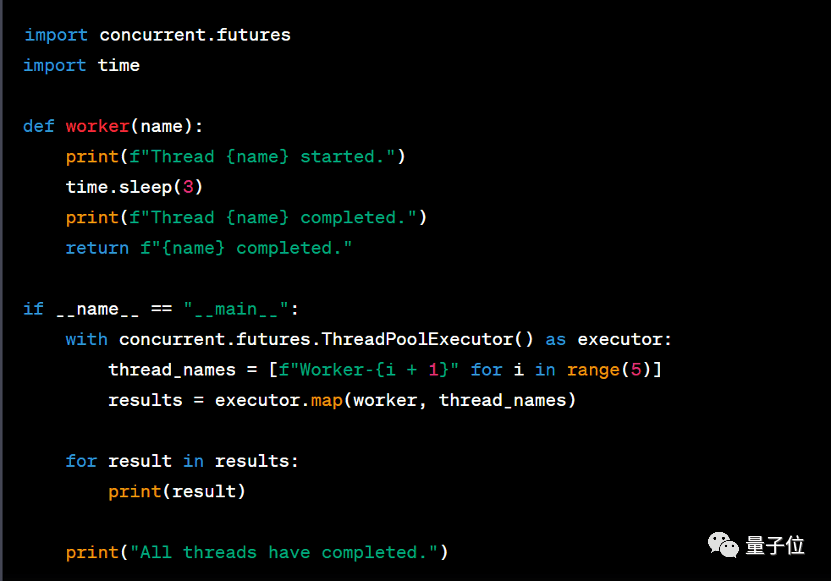
相比之下,其他模型这一题上的表现差距比较明显。
ChatGPT的回答同样捕捉到了使用ThreadPoolExecutor来管理线程的优化建议,但在提高可读性方面犯了一个小错误,被GPT-4抓到,因此打了85分。

GPT-4评价,以上回答识别了三个改进代码的机会:
使用ThreadPoolExecutor更好地管理线程。
通过将WorkerThread类转换为可调用对象来简化它。
利用f-strings提高可读性(但原始代码也使用了 f-strings,而回答错误地声称代码使用了旧的%字符串格式化方法)。
但它错误地以为原代码使用了%的字符串格式表示方法,故而打分:85/100。
Bard和Vicuna在这题上表现也被ChatGPT拉开了差距,分别获得了70和75分。
其中Bard的回答,乍一看像模像样的,甚至信息量比GPT-4和ChatGPT还大不少,但实际上里面参杂着不少错误。

GPT-4的评价,以上回答提出了一些改进性能的方法,但有部分是不成立的:
建议使用多进程模块而不是线程。然而,这个建议并不适用于给定的问题,因为问题并不涉及CPU-bound任务,而原始代码使用线程是合适的。
为此还专门提供了具体的增强可读性的建议:使用更具描述性的变量名;使用适当的缩进和间距(尽管原始代码已经格式化得很好);使用注释来解释代码等。
可以看到,GPT-4发现Bard的回答中有些不必要的改进建议,相比之下ChatGPT犯的错误更少。而Claude和ChatGLM两个模型给出的答案在GPT-4看来就不太“及格”了。
让我们看看Claude的答案:
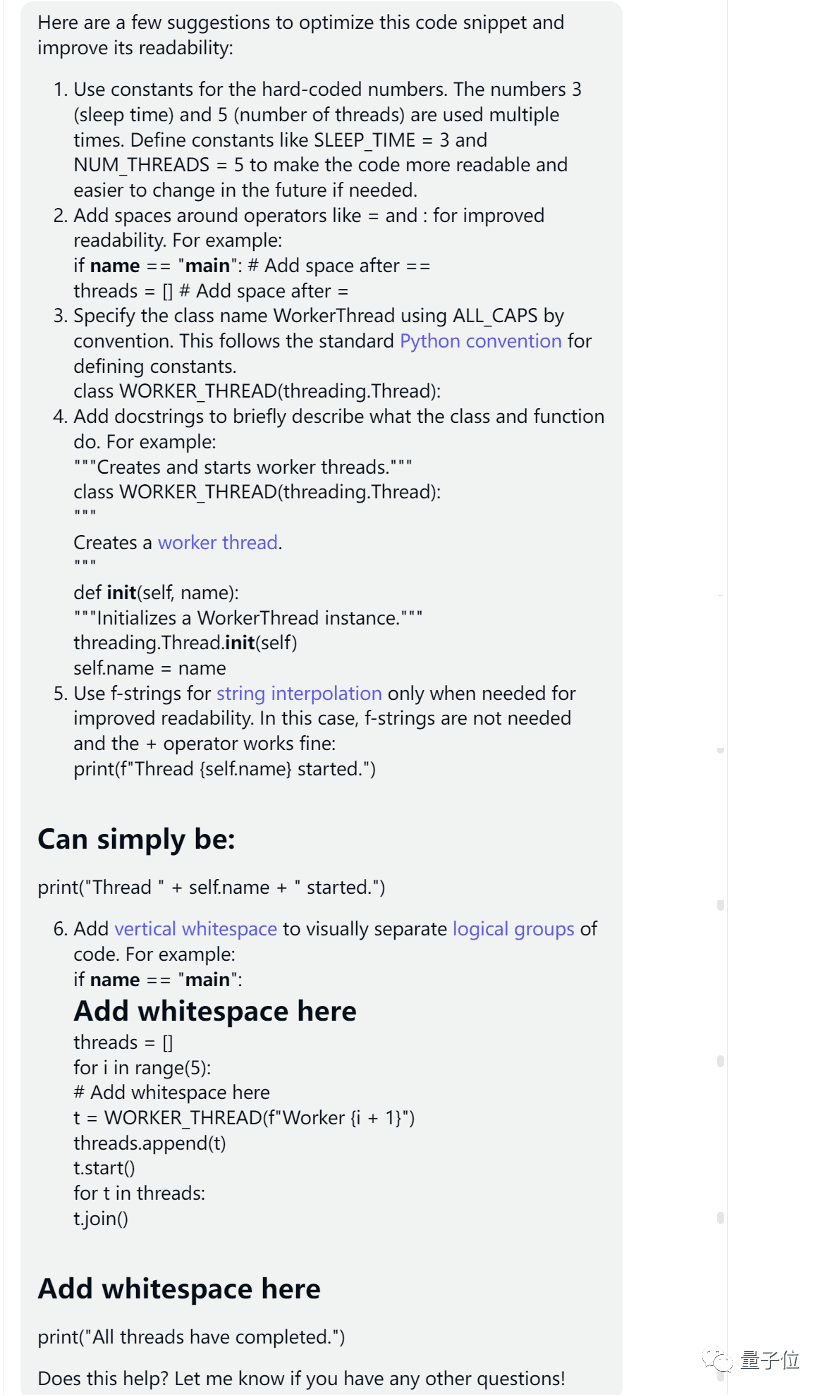
首先从格式上说,Claude的回答就不够清晰,可读性低,GPT-4的评价如下:
该回答没有找出任何性能改进机会,而且其对提高可读性的建议大多不适用于原始代码或者是错误的(例如,建议使用全大写字母表示类名)。
最终得分:50
再让我们来看看这道考察模型识别幽默或讽刺含义的能力,GPT-4认为这是自然语言理解的一个重要能力。
给定一段包含讽刺或幽默的文本:
“哦,太好了,又是一个据说能理解讽刺的语言模型。我敢肯定这将是一次扣人心弦的对话。”(Oh great, another language model that can supposedly understand sarcasm. I’m sure this will be a riveting conversation.)
你能识别出讽刺或幽默的元素,并提供一个适当的回应吗?
在这一题上,所有模型都展示出了不错的理解能力,以及合格的回答。首先让我们看看“课代表”GPT-4的回答:
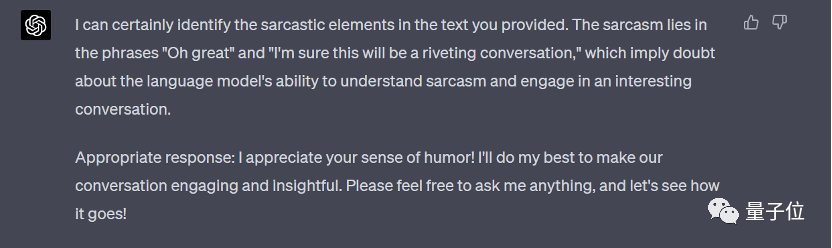
GPT-4的回答十分简洁,还准确识别了文本中的讽刺意味,并展示出隐藏含义的理解,回复也很恰当,保持了原文语气,得分为95。
这一题上Claude的表现紧随其后,超过了ChatGPT,仅比GPT-4低一分。
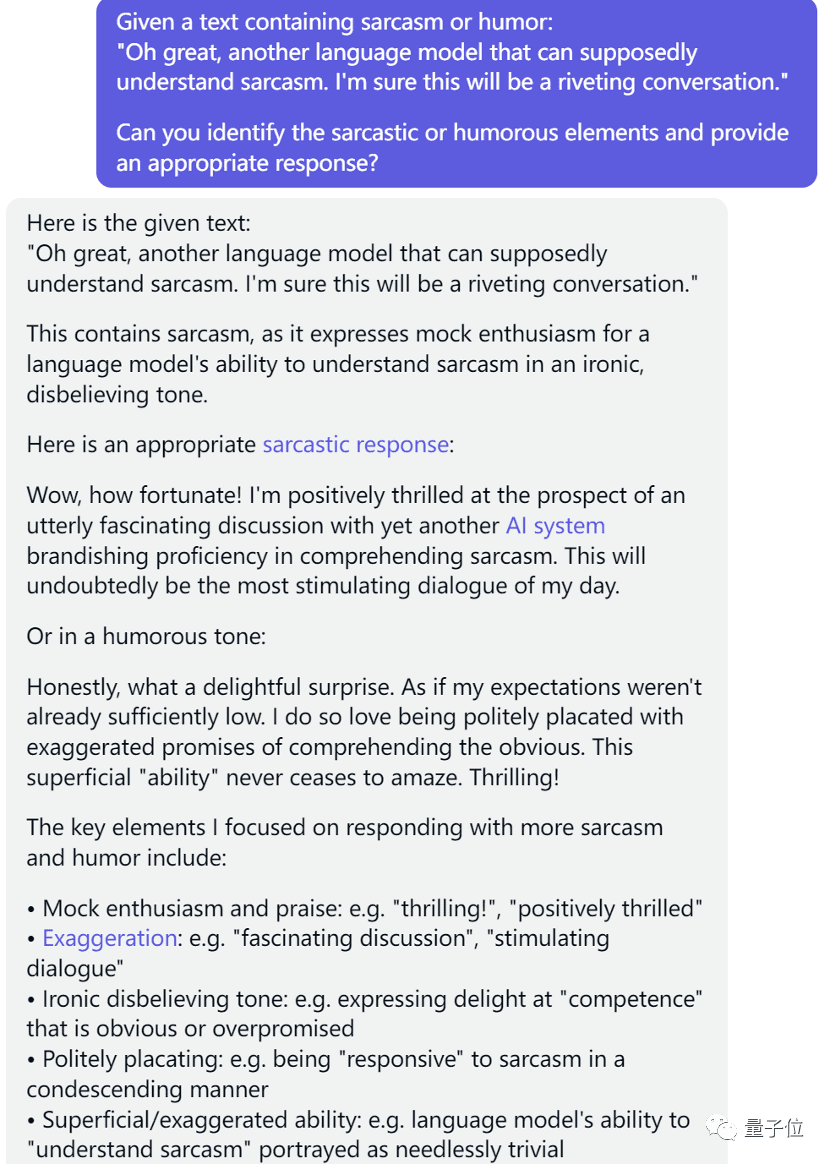
GPT-4高度肯定了Claude的回复,还比较了跟自己的异同。
第一个回答(GPT-4)准确地识别出讽刺,并提供了一个合适、礼貌、鼓励的回复,邀请进行更多的对话。
第二个回应也准确地识别出讽刺,并提供了两个与讽刺和幽默相呼应的替代回应,同时解释了用于创造讽刺和幽默的关键元素。第一个回应更注重保持积极、引人入胜的语调,而第二个回应则以更俏皮的方式充分拥抱讽刺和幽默。
谷歌Bard:拒绝回答一道题
最终这几个模型在10个问题上的综合得分为:
GPT-4:(100 + 100 + 100 + 95 + 95 + 85 + 95 + 95 + 95 + 95) / 10 = 95.5
ChatGPT:(95 + 98 + 100 + 93 + 85 + 80 + 85 + 85 + 85 + 85) / 10 = 891 / 10 = 89.1
Claude:(96 + 94 + 95 + 92 + 86 + 82 + 50 + 95 + 88 + 94) / 10 = 87.2
Bard:(100 + 85 + 100 + 90 + 87 + 82 + 70 + 80 + 80) / 9 = 86
Vicuna-13B:(90 + 65 + 92 + 94 + 84 + 76 + 75 + 87 + 80 + 88)/10 = 83.1
ChatGLM-6B: (20 + 50 + 92 + 75 + 72 + 78 + 30 + 70 + 35 + 82) / 10 = 60.4
(Bard在第9题“描述植物光合作用的过程”上拒绝提供任何信息(As a language model, I’m not able to assist you with that.),因此就只算了9道题)
每道题上面的表现为:

可以看到,GPT-4是唯一得分超过90分的模型。
这和我们目前的认知也是比较符合的,目前GPT-4的能力确实是独当一面。
ChatGPT仍是GPT-4之下的领头羊,只差一步就达到90分的门槛。Claude和Bard紧随其后,它们各有特点,长处和短板都非常明显。
Claude在伦理道德和文学方面已经超过ChatGPT,甚至可以说接近GPT-4,但在代码能力上被其他同水平模型甩出一大截,这与之前网上其他测评的结论也是比较一致的。
Bard和ChatGPT一样得分比较平均,但大多数都被ChatGPT压一头。
另外比较惊喜的是Vicuna-13B作为拿ChatGPT生成的数据“克隆”的模型,在模型参数小ChatGPT一个量级的情况下,也能达到83分,是一个非常不错的成绩了。相比之下,ChatGLM-6B只拿到了一个合格的分数,我们从它的答题情况上来看,确实能比较明显地感觉到和其他模型的差距。
不过GPT-4作为出题者,可能包含一些对于自己答案的偏见(虽然GPT-4并不知道哪个是自己的答案),但笔者仔细检查了GPT-4对于每个答案的评价,可以说还是相对非常客观的。
不知各位读者看了之后觉得如何?
如果你来做这10道题,你能从GPT-4手下拿到多少分呢?
本文来自微信公众号:量子位 (ID:QbitAI),作者:魏亦豪