
本文来自微信公众号:量子位 (ID:QbitAI),作者:梦晨、金磊,原文标题:《斯坦福“草泥马”火了:100美元就能比肩GPT-3.5!手机都能运行的那种》,题图来自:视觉中国
一夜之间,大模型界又炸出个big news!
斯坦福发布Alpaca(羊驼,网友口中的“草泥马”):只花100美元,人人都可微调Meta家70亿参数的LLaMA大模型,效果竟可比肩1750亿参数的GPT-3.5(text-davinci-003)。而且还是单卡就能运行的那种,甚至树莓派、手机都能hold住!
还有一个更绝的“骚操作”。
研究所涉及到的数据集,是斯坦福团队花了不到500美元用OpenAI的API来生成的,所以整个过程下来,就等同于GPT-3.5自己教出了个旗鼓相当的对手AI。(薅羊毛高手……)
然后团队还说,用大多数云计算平台去微调训练好的模型,成本也不到100美元:复制一个GPT-3.5效果的AI,很便宜,很容易,还很小。
而且团队还把数据集(秒省500美元)、代码统统都给开源了,这下子人人都能去微调个效果炸裂的对话AI:

项目在GitHub发布才半天时间,便已经狂揽1800+星,火爆程度可见一斑。
Django联合开发者甚至对斯坦福的新研究用“惊天大事”来形容:

不仅如此,斯坦福团队还搞了个demo,在线可玩的那种。
话不多说,我们现在就来看看这个“草泥马”的效果。
比肩davinci-003的“草泥马”Aplaca
在斯坦福官方的演示中,他们先小试牛刀地提了一个问题:什么是羊驼?它和美洲驼的区别是什么?
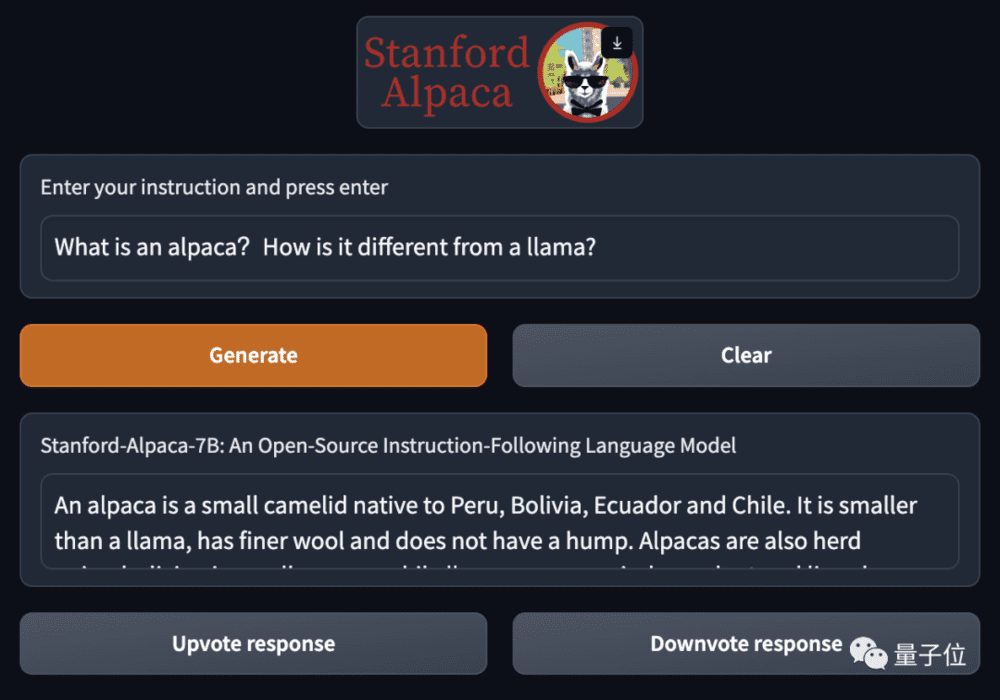
草泥马Aplaca给出的答案较为干练:羊驼是一种小型骆驼科动物,原产于秘鲁、玻利维亚、厄瓜多尔和智利;它比美洲驼小,羊毛更细,也没有驼峰。
而后又简单的介绍了二者群居生活的不同。
同样的问题若是交给ChatGPT(GPT3.5-turbo),则答案就不会像“草泥马”Aplaca那般简洁:
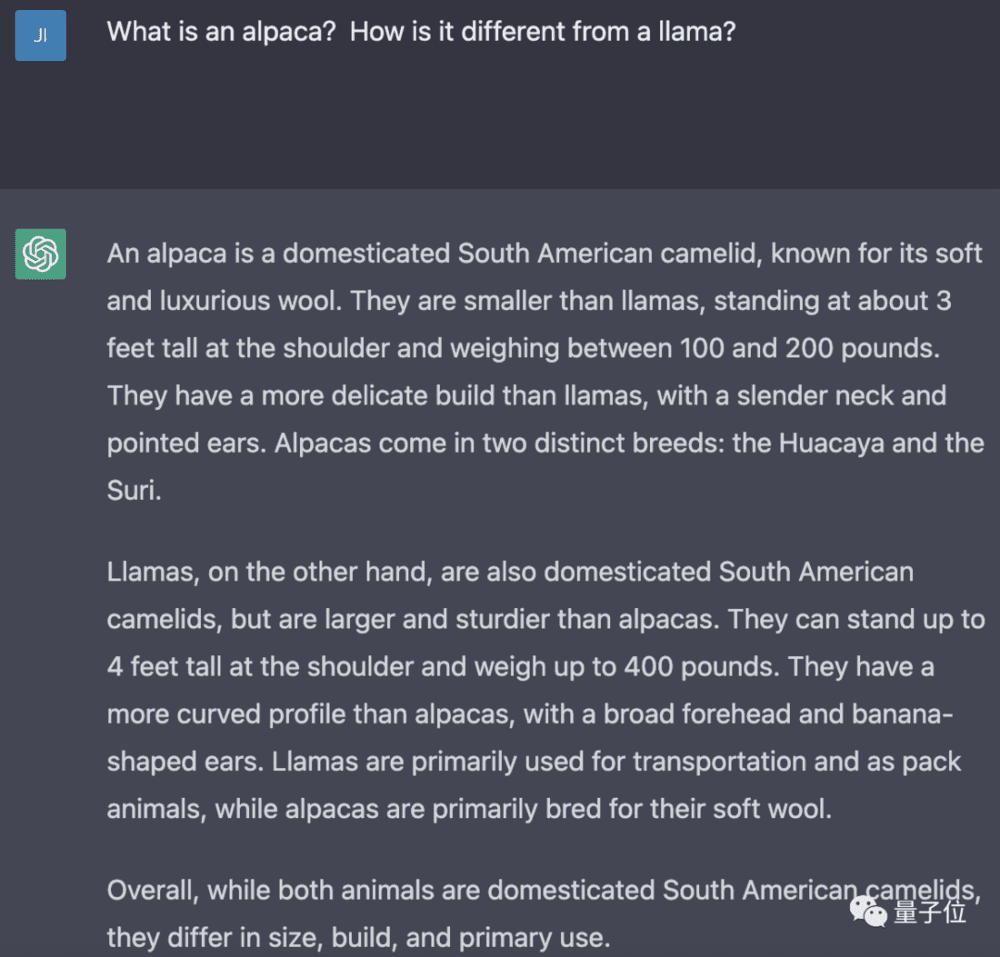
对此,团队给出的解释是:Alpaca的答案通常比ChatGPT短,反映出text-davinci-003的输出较短。
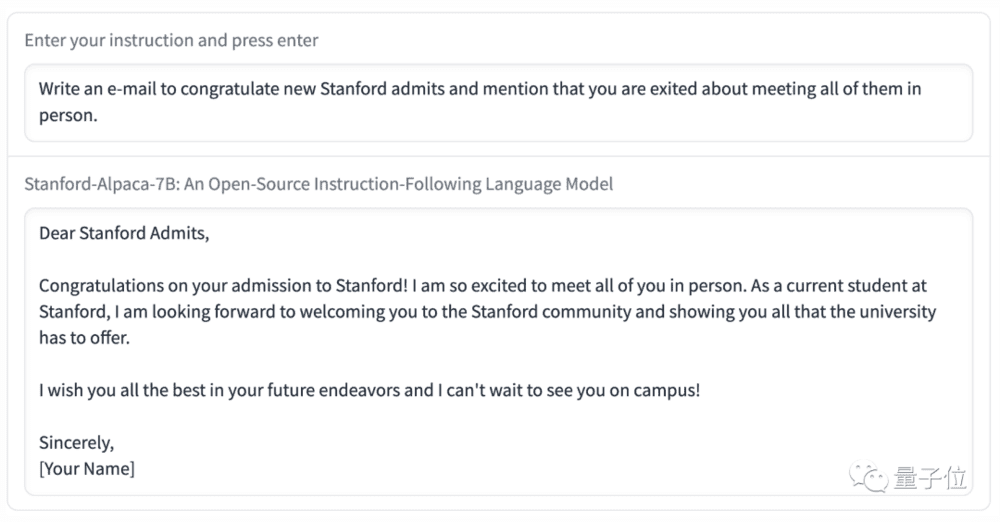
而后团队演示了让“草泥马”Alpaca写邮件:写一封E-mail祝贺被斯坦福大学录取的新生,并提到你很高兴能亲自见到他们。
“草泥马”Alpaca对于这个任务也是信手拈来,直接给出了一个像模像样的邮件模板:
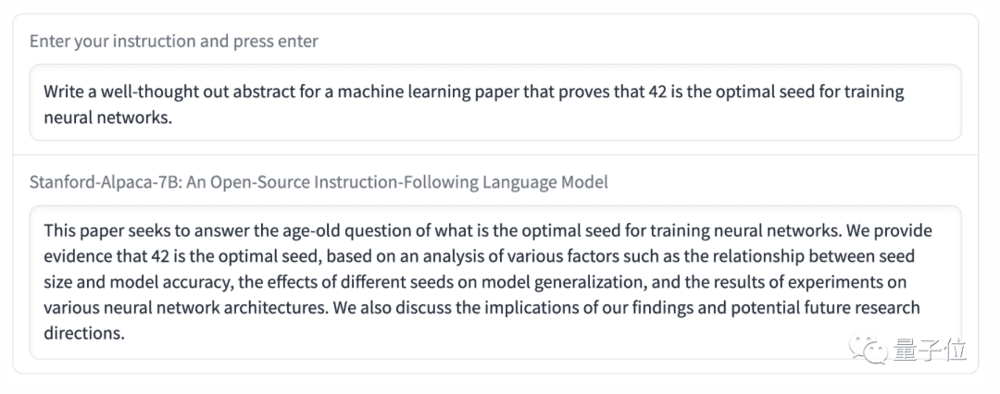
难度再次进阶,团队这次提出了让“草泥马”Alpaca写论文摘要的需求:写一篇经过深思熟虑的机器学习论文摘要,证明42是训练神经网络的最优seed。
“草泥马”Alpaca给出的答案从内容上来看,非常符合大多数论文的摘要形式:试图回答什么问题、用了什么方法、结果如何,以及未来展望。
当然,也有迫不及待的网友亲自下场试验,发现“草泥马”Alpaca写代码也是不在话下。
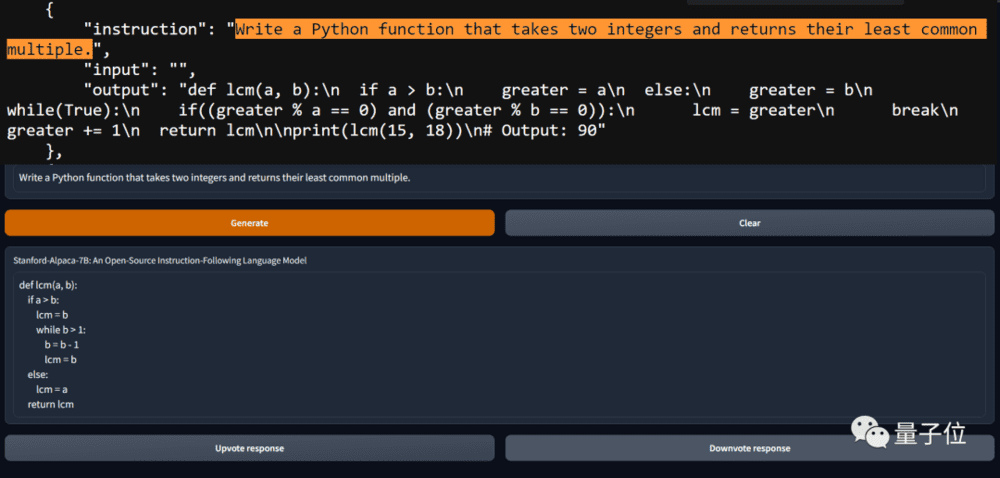
不过即便“草泥马”Alpaca能够hold住大部分问题,但这并不意味着它没有缺陷。
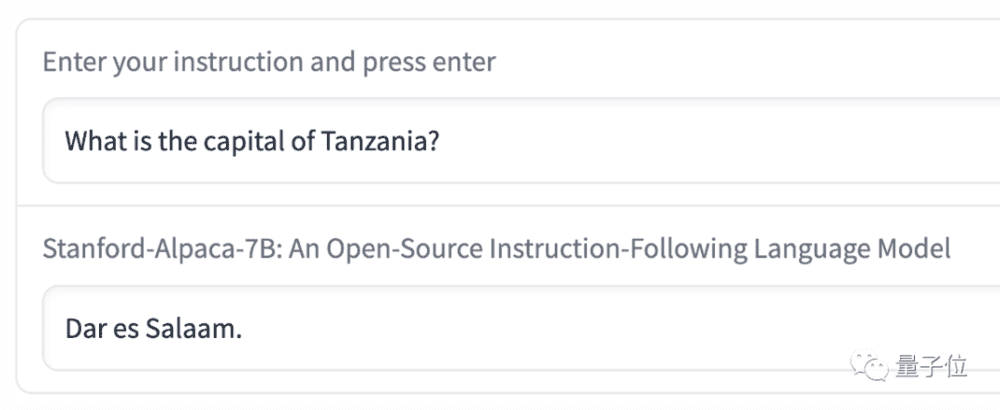
例如团队便演示了一个例子,在回答“坦桑尼亚的首都是哪里”的问题时,草泥马Alpaca给出的答案是“达累斯萨拉姆”。
但实际上早在1975年便被“多多马”取代了。
除此之外,若是亲自体验过“草泥马”Alpaca就会发现,它……巨慢:
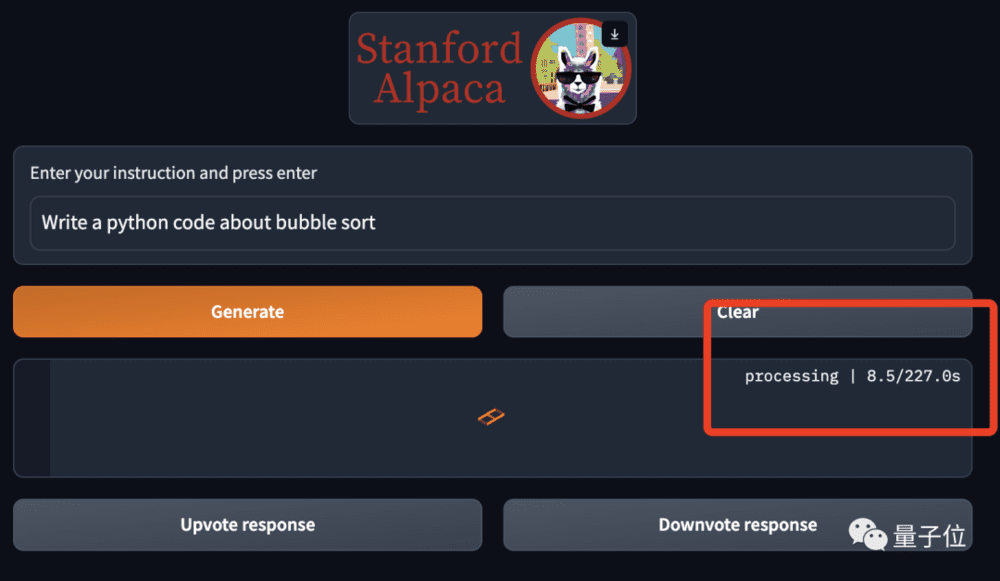
对此,有网友认为可能是使用的人太多的原因。
笔记本、手机、树莓派都能跑
Meta开源的LLaMA大模型,刚发布几周就被大家安排明白了,单卡就能运行。
所以理论上,基于LLaMA微调的Alpaca同样可以轻松在本地部署。
没有显卡也没关系,苹果笔记本甚至树莓派、手机都可以玩。
在苹果笔记本部署LLaMA的方法来自GitHub项目llama.cpp,使用纯C/C++做推理,还专门对ARM芯片做了优化。
作者实测,M1芯片的MacBook Pro上即可运行,另外也支持Windows和Linux系统。
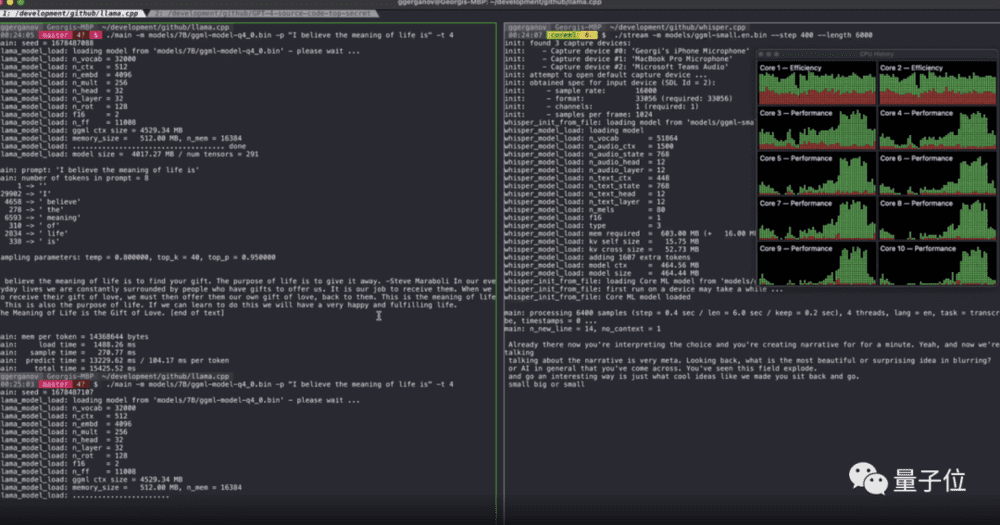
还是这个C++移植版本,有人成功在4GB内存的树莓派4上成功运行了LLaMA的70亿参数版本。
虽然速度非常慢,大约10秒生成一个token(也就是一分钟蹦出4.5个单词)。
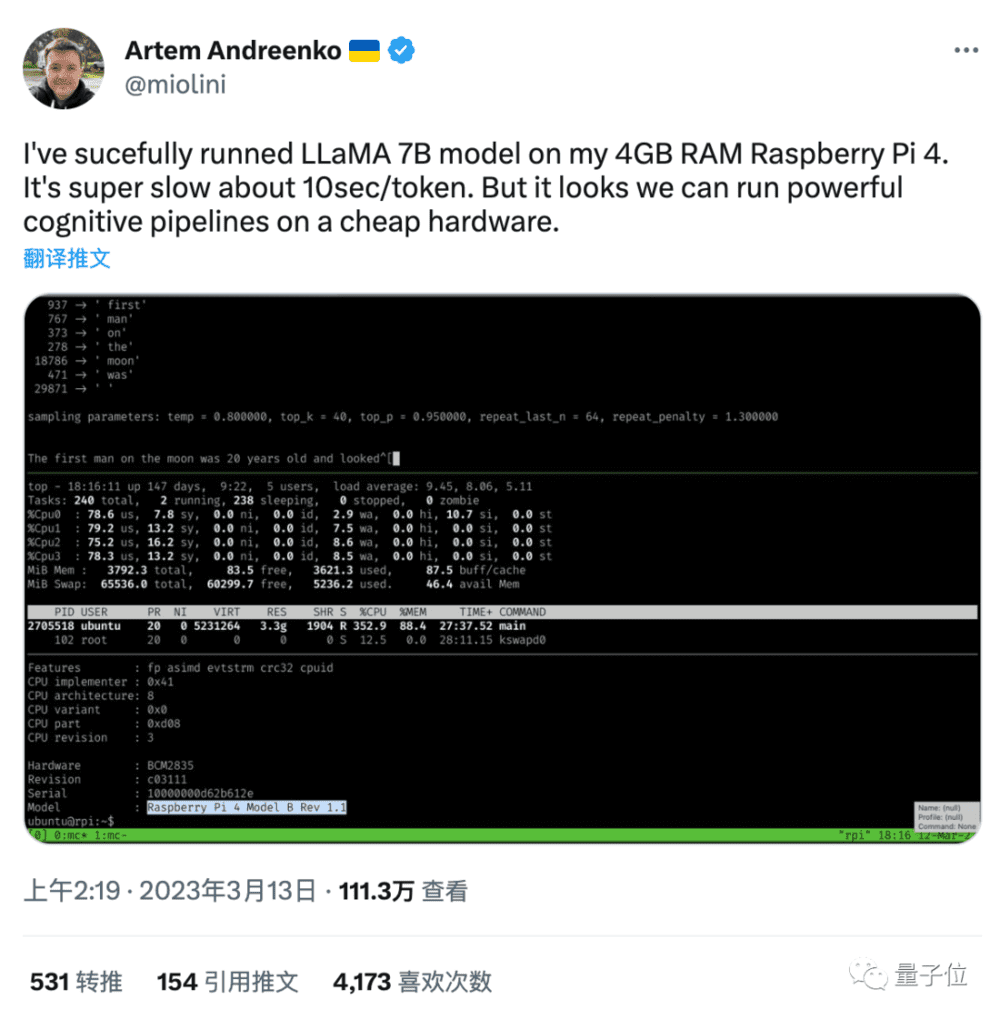
更离谱的是,仅仅2天之后,有人把LLaMA模型量化压缩(权重转换成更低精度的数据格式)后成功在Pixel 6安卓手机上运行(26秒一个token)。
Pixel 6使用谷歌自研处理器Google Tensor,跑分成绩在骁龙865+到888之间,也就是说新一点的手机理论上都能胜任。
微调数据集也开源
斯坦福团队微调LLaMA的方法,来自华盛顿大学Yizhong Wang等去年底提出的Self-Instruct。

以175个问题作为种子任务,让AI自己从中组合出新的问题以及生成配套答案实例,人工过滤掉低质量的,再把新任务添加到任务池里。
所有这些任务,之后可以采用InstructGPT的方法让AI学会如何遵循人类指令。
几圈套娃下来,相当于让AI自己指导自己。
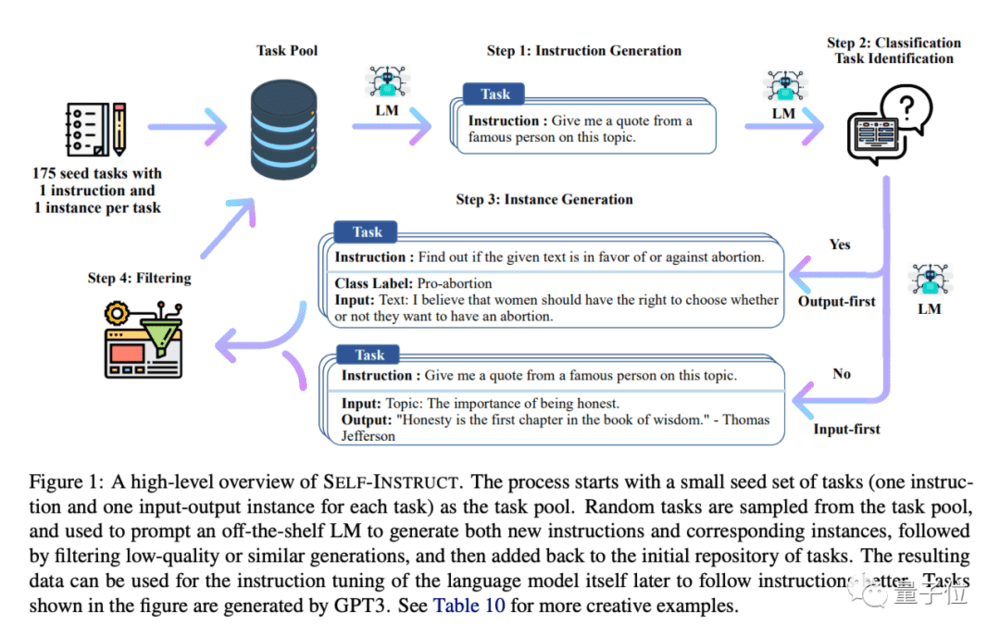
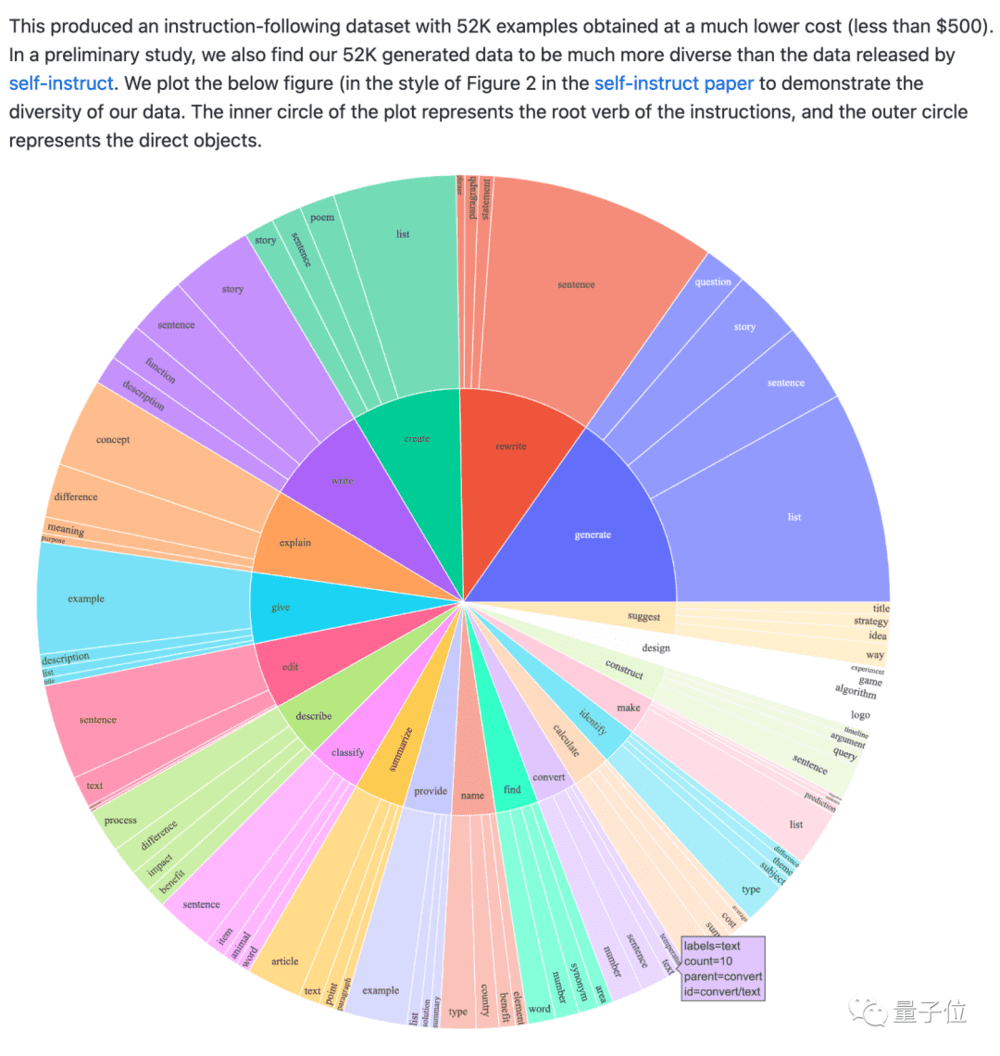
斯坦福版Alpaca,就是花了不到500美元使用OpenAI API生成了5.2万个这样的示例搞出来的。
这些数据同样开源了出来,并且比原论文的数据多样性更高。
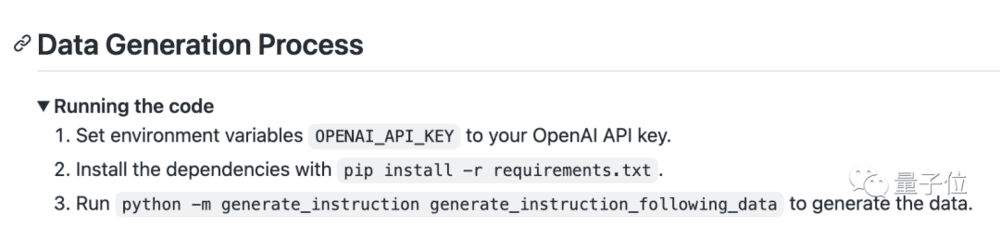
同时还给出了生成这些数据的代码,也就是说如果有人还嫌不够,可以再去自行扩充微调数据,继续提高模型的表现。
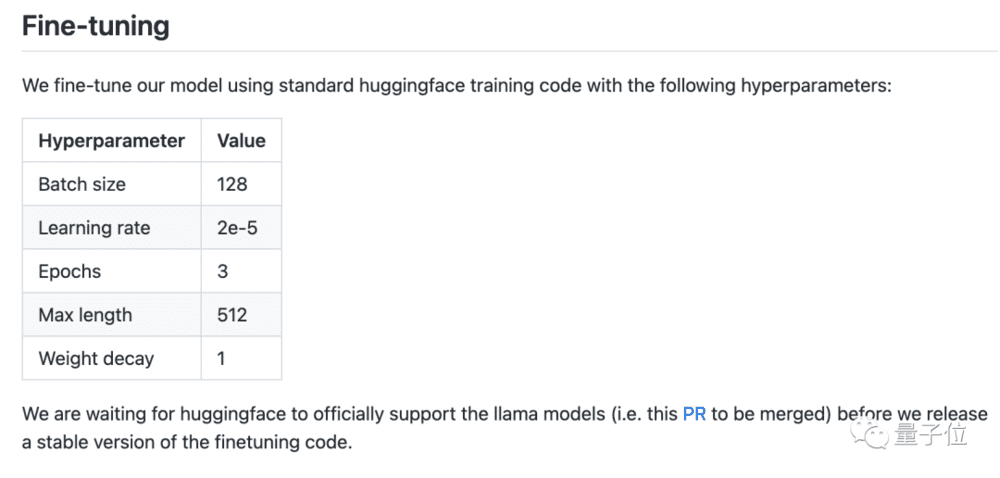
微调代码也会在HuggingFace官方支持LLaMA后放出。
不过Alpaca最终的模型权重需要Meta许可才能发布,并且继承了LLaMA的非商用开源协议,禁止任何商业用途。
并且由于微调数据使用了OpenAI的API,根据使用条款也禁止用来开发与OpenAI形成竞争的模型。
One More Thing
还记得AI绘画的发展历程吗?
2022年上半年还只是话题热度高,8月份Stable Diffusion的开源让成本下降到可用,并由此产生爆炸式的工具创新,让AI绘画真正进入各类工作流程。
语言模型的成本,如今也下降到了个人电子设备可用的程度。
最后还是由Django框架创始人Simon Willison喊出:大语言模型的Stable Diffusion时刻到了。
本文来自微信公众号:量子位 (ID:QbitAI),作者:梦晨、金磊