
本文来自微信公众号:量子位 (ID:QbitAI),作者:衡宇,题图来自:视觉中国
当我们围观ChatGPT炸开的多场激战时,还有什么是暗流下激战的?
今天要关注的,不是违背“非盈利”初心的OpenAI,也不是商业模式面临颠覆的谷歌搜索。把目光从公司层面挪开,看向另一场已经白热化的战争——
借着的ChatGPT燎原之势,2月中旬同一天的30分钟内,就有2位谷歌大脑大模型人才先后官宣入职OpenAI,其中之一Jason Wei是思维链(chain-of-thought,CoT)的最早一作。
大模型交锋背后,谷歌和OpenAI的人才战争打得正酣。和动辄上亿美元的投融资同样重要,AI人才也是兵家必争的财富。
但其实,AI人才流动、被抢夺,早在ChatGPT搅动漩涡之前就开始了。
GPT系列:8人联创新公司,成谷歌对战ChatGPT一步棋
势如破竹的ChatGPT,积攒了OpenAI从GPT一路迭代至InstructGPT的技术经验与实力。
ChatGPT基于OpenAI的GPT-3.5创造。2018年和2019年,OpenAI分别推出了1.17亿参数的GPT-1和15亿参数的GPT-2;2020年,大力出奇迹的GPT-3问世,训练参数达到1750亿,涌现出一些类似人脑独特的能力,引起轰动;而后又在2022年初推出全新的InstructGPT模型,只要13亿参数,效果就比GPT-3更好。
《纽约时报》披露,原本下一代GPT-4在OpenAI内部几乎准备就绪,只待发布;去年11月中旬,高层突然宣布新任务:两周后发布免费聊天机器人应用,代号“Chat with GPT3.5”,这就是今天见到的ChatGPT。
51位作者,其中2人参与3次论文创作
GPT系列共发表了4篇论文,51位作者参与其中。
作者名单中出现最频繁的是Alec Radford和Ilya Sutskever两位,均参与GPT-1到3的论文创作。前者是OpenAI的ML研究员,也是indico.io的联创,谷歌学术上他被引用最多的研究是DC-GAN;后者更为人所熟知,OpenAI联创之一,也是OpenAI首席科学家,主导了GPT系列以及DALLE系列模型的研发。
另有5人在GPT系列论文中2次贡献了自己的力量:
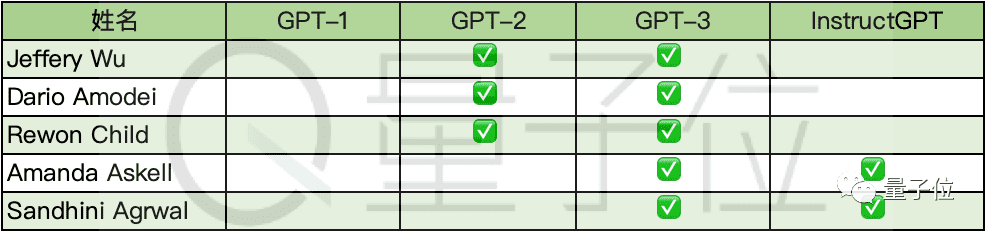
51人组成的人才图鉴,学历一栏中名校印记俯拾皆是。据不完全统计,出现频次最多的是MIT和斯坦福大学,曾在耶鲁大学、UC伯克利、哈佛大学、牛津大学攻读学位的人也不在少数。也不乏在这些名校中辗转求学的人,譬如表格中提到的OpenAI前研究副总裁Dario Amodei,先后就读于普林斯顿大学和斯坦福大学;再比如InstructGPT背后论文共同作者之一Gretchen Krueger,MIT、哈佛大学、哥伦比亚大学都是他的母校。
出走团队打造ChatGPT竞品对话式AI
毫无疑问,GPT系列背后的51人引领了大语言模型的创新风潮。从GPT系列结束战斗后,不少人从OpenAI脱离。除开GPT-3共同作者、哥大博士在读的Melanie Subbiah本就不属于OpenAI,50人里共有16位人才从OpenAI流失。
其中8位的最终流向是AI初创公司Anthropic。更准确地说,包括Dario Amodei、GPT-3论文一作Tom B. Brown在内的一批核心人才不满OpenAI成为微软附庸——因被注资,OpenAI要使用Azure超算来搞研究,要将技术授权给微软,甚至要给微软的投资活动筹集资金,这与OpenAI创立的初衷(关注高级AI安全)相悖。
最终,包括8位GPT系列作者在内,共11名OpenAI前员工怒而离职,于2021年创办Anthropic,要搞能控制、可解释的AI,重心放在生成式AI上。
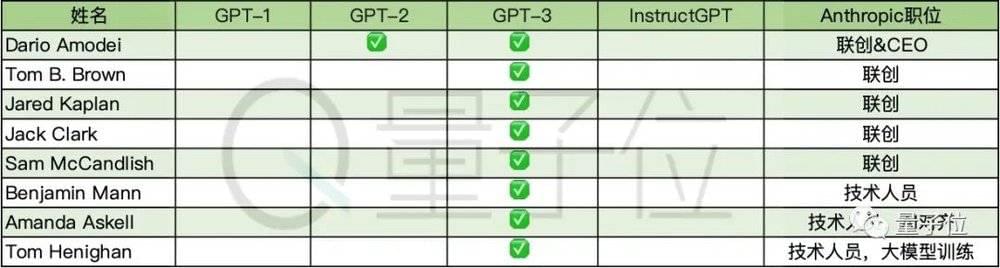
出走创办Anthropic的GPT系作者
1月底,Anthropic开始内测聊天机器人Claude。同为生成式对话AI,与ChatGPT的同台竞赛不可避免,二者各有千秋,最终测评结果:Claude在12项任务中有8项更强。
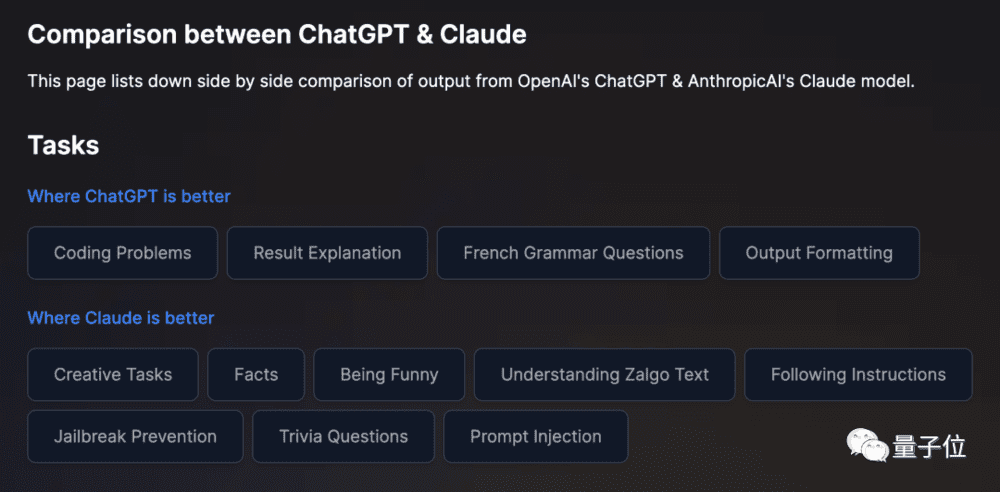
关于Anthropic的最新消息让这家“复仇者联盟”愈发走到台前。月初,谷歌向它投资3亿多美元(约合人民币20.3亿元),拿下后者约10%的股份。交易条款要求,Anthropic需要从谷歌云计算部门购买计算资源。这恰好与3年前,OpenAI接受微软高达10亿美元的注资,将微软定位独家云提供商所呼应。
换句话说,Dario Amodei带着Anthropic走上了3年前所不齿的OpenAI的老路,接受金主爸爸提供的算力来进行技术开发。现如今,Anthropic最新估值50亿美元,除谷歌外,已有的投资人包括Facebook联创Dustin Moskovitz,谷歌前CEO、现技术顾问Eric Schmidt等人。
也曾有人转投谷歌门下
OpenAI GPT系作出走16人,Anthropic是他们的主要流向,剩下8人中,有3位第一时间投入谷歌门下。
其一是GPT-1的三作Tim Salimans,2018年7月他就履新谷歌大脑,base阿姆斯特丹,担任职位为高级管理科学家;其二是GPT-2的四作David Luan,2020年9月起他加入谷歌任主管,工作1年多后离职,后来和Transformer论文作者Ashish Vaswani、Niki Parmar一起,创办了一家叫Adept的公司,目标是创造让人和计算机能够协同工作的通用人工智能;第三位叫a,在2021年3月加入谷歌大脑。

时至今日,Adept和Anthropic两家AI公司的声量比不上风头正盛的OpenAI和其强劲对手DeepMind,不过各自在AI产业界颇有建树,甚至拿出Claude这种可与ChatGPT一较高下的产品。从这两家公司的今日成就不难看出,GPT系作者的确不是等闲之辈。
LaMDA:1/4成员只有本科学历
梳理完GPT系论文作者现状,镜头转向谷歌的LaMDA论文背后团队,作者共60名。和GPT系作者团一样,LaMDA作者团队同样不乏耀眼的名校背景,斯坦福校友最多,共有6人;其次是哥伦比亚大学,有三人曾在哥大就读;接着是浙江大学、比拉科技学院、杜克大学、上海交通大学、耶鲁大学、台湾大学,这6所大学出现了2次。
不过有一说一,相比较而言,LaMDA团队的名校光环更少,成员的学校背景中常出现阿比林基督教大学、伊比利亚美洲大学、哈丁西蒙斯大学等类似的非顶尖名校。
15位作者只有本科学历,多数人出身计算机专业
还有三个特点在LaMDA作者履历中显现:
第一,至少有17人在某个求学阶段主修学科为计算机工程/科学,计算机学科背景贯穿求学始终的人也不在少数,像Hongrae Lee,先是在首尔国立大学拿下计算机科学本硕学历后,又赴往哥伦比亚大学攻读计算机科学博士学位。
第二,据不完全统计,至少有15位LaMDA论文作者只拥有本科学历,这些人中有一半就读的专业是计算机工程/科学。
第三,有7位LaMDA论文作者在谷歌工作了10年以上,资历最老的是Igor Krivokon,截至今年2月,他在谷歌的工作年限为19年又5个月;Will Rusch也在谷歌工作了19年,从美国南加州大学电气工程系毕业后,他就成为了谷歌的一份子,直到今天。
上文提到,有5%的GPT系作者跑到了对家谷歌干活,相比之下,LaMDA论文作者,没有一位跳槽到对家OpenAI,很稳。那么,究竟是什么样的公司,能够得到出走的LaMDA论文作者的法眼?
答案是两家AI初创公司,一家是Inflection AI,另一家是Character.AI。
出走后,成AI初创公司Inflection AI&Character.AI创始团队
先来聊聊Inflection AI,这家机器学习初创公司是LaMDA作者中的Joe Fenton,和从OpenAI出来的Rewon Child(3位投奔谷歌的出走成员之一)共同创立,创始团队中还有LinkedIn联创Reid Hoffman和DeepMind创始成员、谷歌人工智能产品与政策副总裁Mustafa Suleyman,阵容十分豪华。LaMDA论文作者,曾担任谷歌研究工程师的Maarten Bosma在公司成立后也被挖走,现为Inflection AI技术人员。
据了解,这家公司的总体目标是利用人工智能帮助人类与计算机“对话”。去年5月,Inflection AI获得了2.25亿美元的A轮融资,资金来源尚不清楚,公司估值超过12亿美金。以及,现有5名LaMDA论文作者进入Character AI就职。
Character AI的创始人Noam Shazeer是谷歌前首席软件工程师,不仅参与了LaMDA的研究,还是Transformer论文作者之一。杜克大学本科毕业后,2000年年底,Noam Shazeer加入谷歌,是谷歌最重要的早期员工之一。虽然中途一度离职,但截至他2021年10月离职创办新公司,共在谷歌工作了17年又5个月。Character AI的现任总裁也是LaMDA论文作者,Daniel De Freitas,加入谷歌前,他曾在微软Bing做软件工程师。
实际上,LamDA论文发表时,Noam Shazeer和Daniel De Freitas都已经从谷歌离职,开始筹备Character AI了。据报道,Character AI已经创建了一个基于LaMDA的神经语言模型聊天机器人Web应用程序,能够生成类似人类的文本响应并参与上下文对话。
额外提一点,除LaMDA背后作者外,谷歌的大模型人才近期流动也都比较频繁。先不用说BERT模型四位作者之一,被称为BERT之父的Jacob Devlin今年1月刚刚离开谷歌加入OpenAI,看看去年ChatGPT发布页面的致谢名单里,就有Barret Zoph等5个人,都是谷歌前员工,他们在ChatGPT问世前加入OpenAI,在调整和准备ChatGPT中发挥了关键作用。此外,The Information消息披露,进入今年1月,又有至少4名谷歌大脑成员加入OpenAI。
危急存亡之秋,谷歌嗅到了人才流失的危险,相继推出了一系列举措。除却重金投资OpenAI出走团队打造的Anthropic外,其旗下专注语言大模型领域的“蓝移团队”(Blueshift Team)宣布,正式加入DeepMind,旨在共同提升LLM能力——先进行阵列自行调整,集中内部力量,迎接OpenAI炮火。

人才大战里的华人面孔
今年年初,大模型人才的跳槽愈发频繁。从谷歌加入OpenAI的谷歌大脑4人之一中,包括华人顾世翔(Shane Gu),谷歌大脑日本团队前成员,剑桥大学博士,本科在多伦多大学师从三巨头之一Hinton。去年5月,只要加上一句“让我们一步一步地思考”就能让GPT-3做数学题的准确率暴涨61%这事,就是顾世翔参与的研究发现。
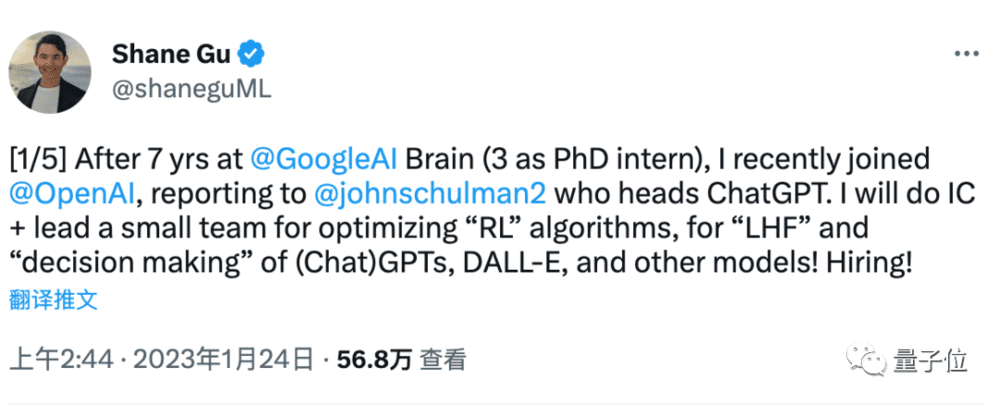
像他这样,在谷歌和OpenAI的人才争夺大战中出现的华人面孔还有多少?据不完全统计,共有16人,LaMDA论文作者里就有14人,占87.5%,也就是说华人面孔占据了大模型111人中的14.4%。
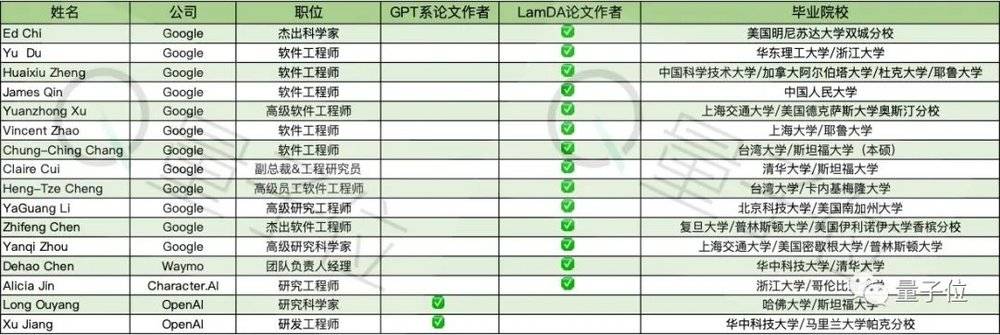
这里要着重提2个人。一位是美籍华人Ed Chi,1973年出生,现为谷歌杰出科学家,早年以应用资讯气味理论预测网站可用性而闻名。
从美国明尼苏达大学双城分校取得硕士学位后,Ed Chi于1997年至2011年期间,在帕洛阿尔托研究中心(PARC)担任研究科学家。2011年,Ed Chi以高级研究科学家的身份从PARC离职,成为谷歌的一名研究科学家。2012年,他担任任人机交互领域最负盛名的学术会议CHI的技术项目联合主席。2017年,Ed Chi被提升为谷歌首席科学家。

另一位要提到的是欧阳龙(Long Ouyang),他参与了与ChatGPT相关的7大技术项目中的4项研究,包括InstructGPT、webGPT、RLHF和ChatGPT,是InstructGPT论文的一作,RLHF论文的第二作者。
革命性科技浪潮背后,人才频繁流动
梳理后不难看到,谷歌和OpenAI虽为大模型重镇,但人才流动其实是很寻常的事。仅仅在本文涉及的人员里,GPT-2论文四作和Transformer论文一作和共同创办的Adept,不到半年就亮出了新公司的首个大模型ACT-1;Anthropic更是凭借对话机器人Cluade成为谷歌和OpenAI大战中的一把利刃。
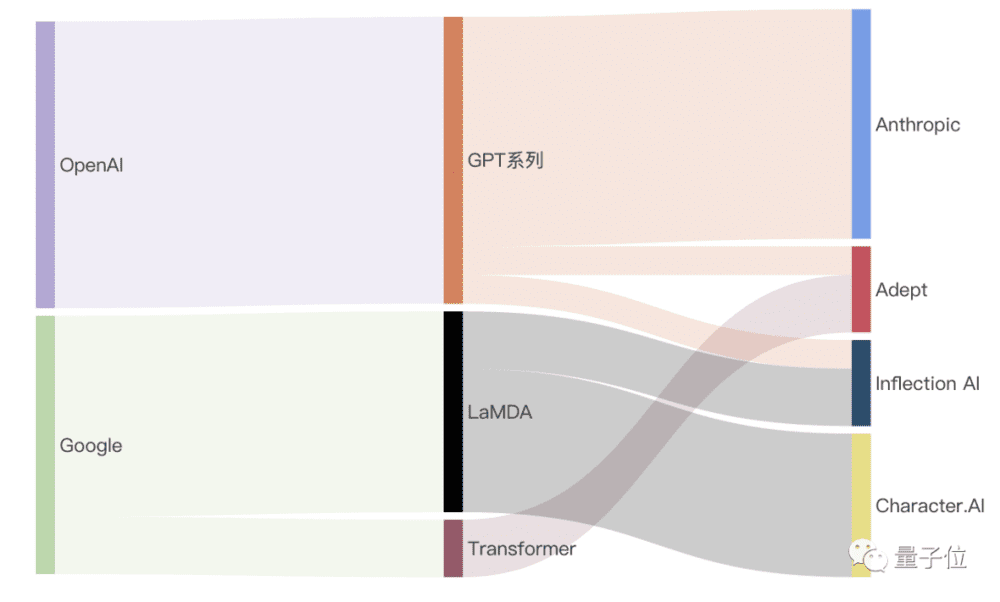
大模型人才从OpenAI和谷歌出走后,创立的AI初创公司
总体而言,爆炸性的ChatGPT让大模型背后的人才更加受到世人关注,对这些人来说,ChatGPT带来的风口也是他们必须迎头面对的挑战。
由此提出一个思考:做类ChatGPT产品,中国的优势在哪里?
很大程度上,构筑大模型堆参数、堆数据的大力出奇迹之道,其实是中国团队向来擅长的事情。但不可否认,小公司负担不起高昂的天价成本,大公司需要综合考虑整体战略,种种因素,从不同角度成为一个中国版ChatGPT诞生的外在桎梏。
如此一来,破除外在束缚需用巧力。在算法、数据等都存在差距的现实条件下,人才或许能成为这场轰轰烈烈全球擂台赛里的破局点。大模型背后的每一个参与者和理念、数据、技术拥有同等的重要价值。中国不缺人,更不缺人才,从GPT系论文和LaMDA论文背后的华人作者数量,更可以看到AI人才的实力,人才的聚集能形成人才规模核心竞争力。
The battle of AGI never ends!埋头研究,伸手抢人的现象,已经在国内出现。想招人的,想找工作的,都可以开始准备了。
本文来自微信公众号:量子位 (ID:QbitAI),作者:衡宇