
本文来自微信公众号:量子学派 (ID:quantumschool),作者:十七进制,题图来自:《变形金刚》
ChatGPT红得发紫,强得让人类心悸,但在它的背后,还隐藏着一位真正的大佬。
可以说,与它相比,ChatGPT其实只是它的一个跟班小弟。
或者说,只是它掌控家族中的一个比较靓的仔。
这位大佬自2017年问世以来,隐约已成为AI领域的基石王者。
它的名字叫做——Transformer。
一、Chat不重要,GPT才重要
先拆解一下ChatGPT,它由Chat与GPT两部分组成。
聊天不重要,GPT才重要。
那什么是GPT,它的全英文是Generative Pre-trained Transformer。
翻译过来就是——生成式预训练的变形金刚。
先问ChatGPT——你是谁?
我是谁,它是这样解释的:
GPT是基于Transformer架构的预训练语言模型,可以生成自然语言文本。Transformer是基于自注意力机制的深度学习模型架构,它在自然语言处理领域中得到了广泛的应用,如机器翻译、文本分类和生成模型等。
GPT是基于Transformer模型的改进版本,主要是针对生成任务进行了优化,通过预训练学习自然语言的语义和语法规律,进而生成高质量的文本。
因此,GPT可以看作是Transformer模型在生成任务上的一个应用扩展。
短短的自我介绍中,ChatGPT就四次提到Transformer。
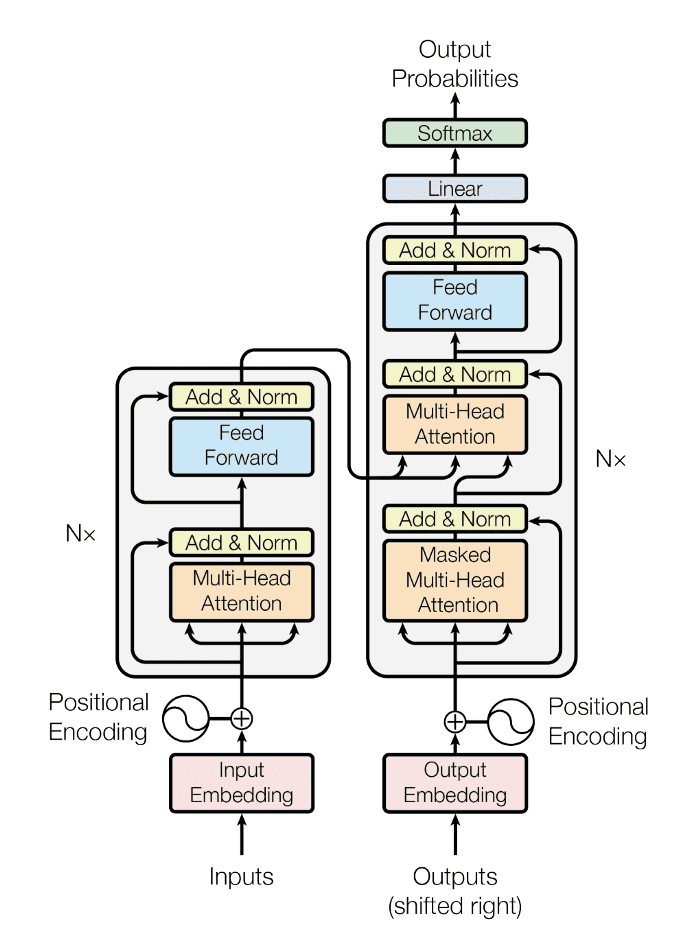
Transformer到底是什么,让ChatGPT如此迷恋?
这只变形金刚,到底是只什么怪兽?
二、强大的变形金刚Transformer
Transformer的定义清晰明了:
是用于自然语言处理(NLP)的神经网络架构。
在Transformer出现之前,人工智能研究领域百家争鸣。
Transformer出现之后,格局开始变了,开始打压如日中天的循环神经网络(RNN)和卷积神经网络(CNN)。
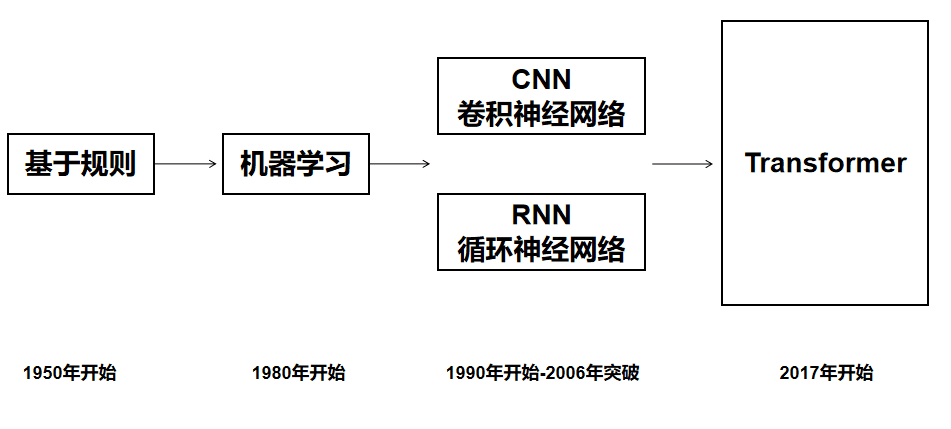
Transformer架构使用了注意力机制,能够处理长序列的依赖关系。
这让它具有以下明显优点:
❶ 并行计算:由于自注意力机制的引入,Transformer可以实现并行计算,加快训练速度。
❷ 长序列处理:相比传统的循环神经网络和卷积神经网络,Transformer可以处理更长的序列,这是由于自注意力机制可以学习到全局的序列信息。
❸ 模块化结构:Transformer由编码器和解码器两部分组成,每部分都包含了多层相同的模块,这种模块化结构使得Transformer更易于扩展和调整。
Transformer在各种任务中的表现,也将不断得到改善和优化,发展日新月益。
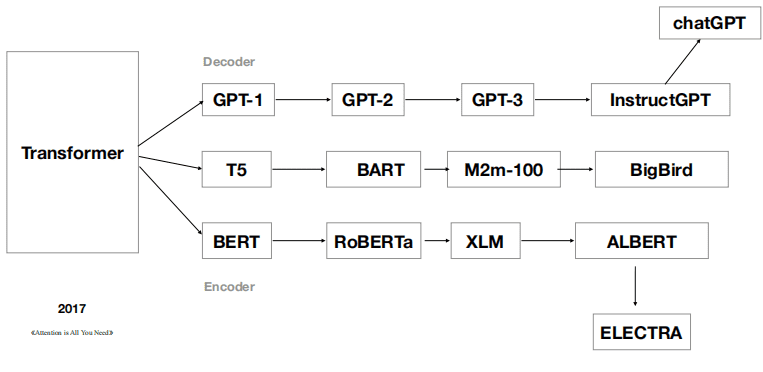
自2017年推出之后, Transformer已经形成了自己的家族体系。
基于GPT架构,ChatGPT就隐藏在GPT-3的后面。
现在你就明白,它为什么叫变形金刚了。
它的确是可以演变成各种不同的角色,而且个个都挺厉害。
三、统一自然语言NLP
人工智能的一大研究方向,首先是自然语言处理NLP领域。
自从Transformers出现后,全球NLP领域的人工智能的工程师们望风景从。
Transformers在该领域的进展所向披靡,不可阻挡,原因如下:
❶ 模型大小和训练数据规模的增加:大规模的Transformers模型,如GPT-3.5、bert、T5等,有些模型参数量达到千亿级别,具有更强表达能力。
❷ 多语言和跨语言应用:由于Transformers模型具有更强泛化能力,因此可以被应用于多语言和跨语言任务,如机器翻译、跨语言文本分类等。
❸ 与其他模型的结合和拓展:与其他模型结合使用,如结合卷积神经网络(CNN)或循环神经网络(RNN)进行多模态学习等。
❹ 解释性和可解释性:随着越来越多的机器学习算法被应用于实际场景,对于模型的解释性和可解释性要求也越来越高。
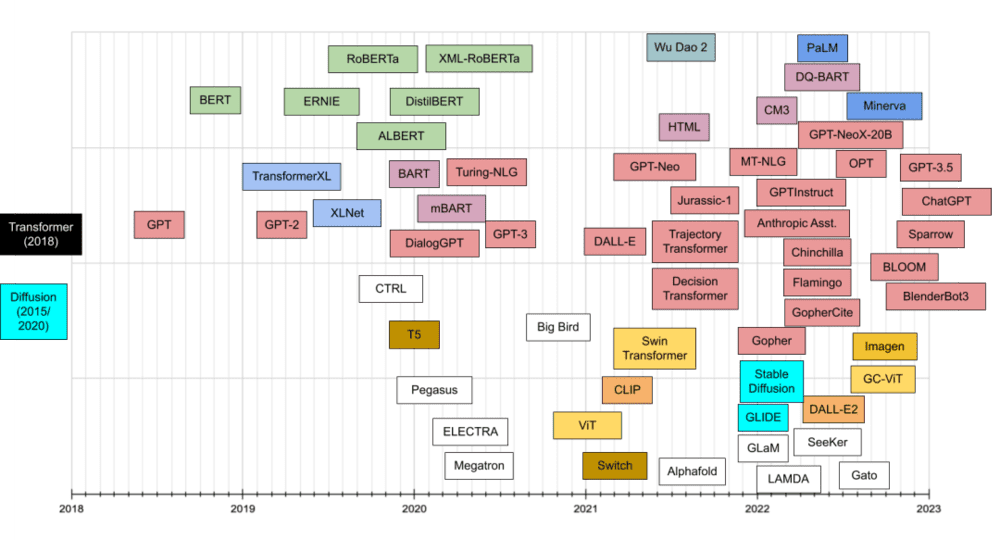
在自然语言处理NLP领域,总体的趋势是:LSTM/CNN→Transformer。
NLP领域分为两大不同类型的任务:
❶ 理解类人工智能
❷ 生成式人工智能
这两个领域的研发,已经收敛到了两个不同的预训练模型框架里:
❶ 自然语言理解,技术体系统一到了以Bert为代表的“双向语言模型预训练+应用Fine-tuning”模式;
❷ 自然语言生成类任务,其技术体系则统一到了以GPT为代表的“自回归语言模型(即从左到右单向语言模型)+Zero /Few Shot Prompt”模式。
而这两大模型都是基于Transformers,而且两者也出现了技术统一趋向。
在自然语言处理NLP这个领域,Transformer基本上已经一统天下。
以至于那些还沉迷于CNN,RNN的工程师被警告:
放弃战斗吧,向Transformer投降!
四、藏不住的野心:统一计算机视觉CV
除了NLP,人工智能的另一分支是计算机视觉CV。
Transformer最开始,只是专注于自然语言的处理。NLP曾经落后于计算机视觉,但是Transformer的出现迅速地改变了现状。
一出生就风华正茂,用来形容Transformer毫不为过。它催生了一大批举世瞩目的模型,达到了令人类不安的程度。
随着Transformer统一了NLP,计算机视觉领域显然受到了启发。
一直沉迷于CNN神经网络中的科学家,开始想知道Transformer是否可以在计算机视觉方面取得类似的效果。
不试不知道,一试吓一跳。
Transformer在计算机视觉领域同样治疗效果明显:
❶ 图像分类
ViT(Vision Transformer)是一种将Transformer应用于图像分类的模型。在ImageNet等基准数据集上取得了与卷积神经网络(CNN)相媲美的结果。
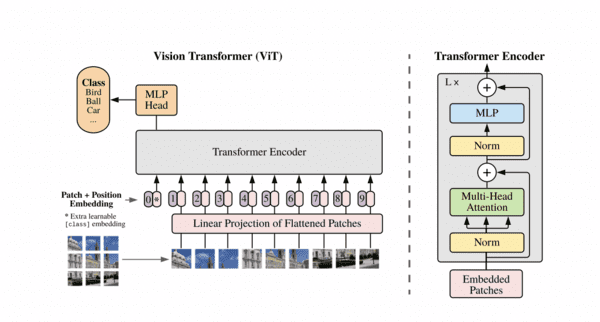
❷ 目标检测
DETR(DEtection TRansformer)是基于Transformer的目标检测模型。DETR在COCO数据集上取得了与 Faster R-CNN 方法相当的结果。
❸ 语义分割
Transformer可以用于语义分割任务,其中每个像素被视为一个token。在Cityscapes、ADE20K和COCO-Stuff等数据集上取得了领先的结果。
以上例子都是Transformer的应用,它在计算机视觉领域也是虎视耽耽。
五、花8分钟时间,拆解Transformer这只变形金刚
Transformer为何如此强大,我们花8分钟来解剖它。
以下内容来自Jay Alammar:
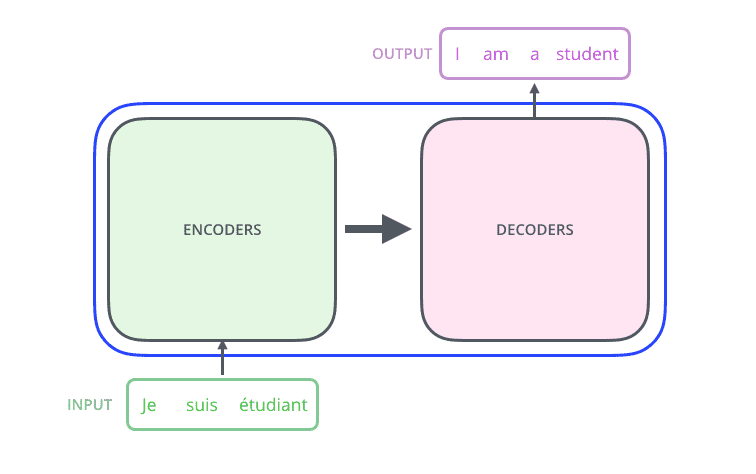
Transformers可以被看做一个黑盒,以文本翻译中的法-英翻译任务为例,这个黑箱接受一句法语作为输入,输出一句相应的英语。

那么在这个黑盒子里面都有什么呢?
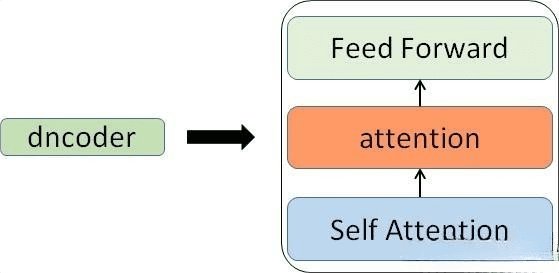
里面主要有两部分组成:Encoder 和 Decoder。
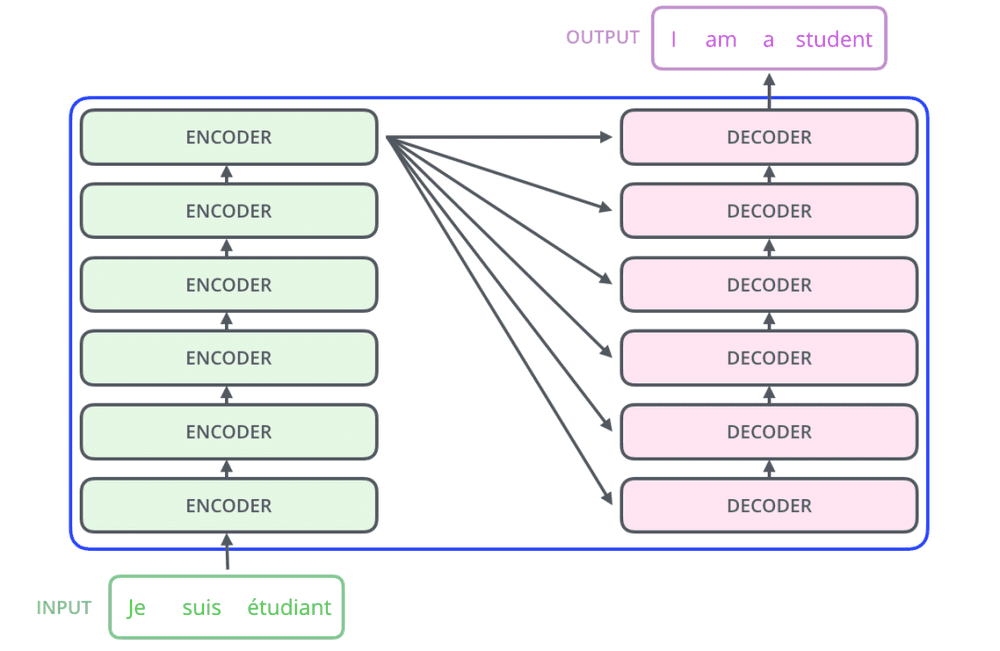
在编码部分,每一个的小编码器的输入,是前一个小编码器的输出。而每一个小解码器的输入,不光是它的前一个解码器的输出,还包括了整个编码部分的输出。
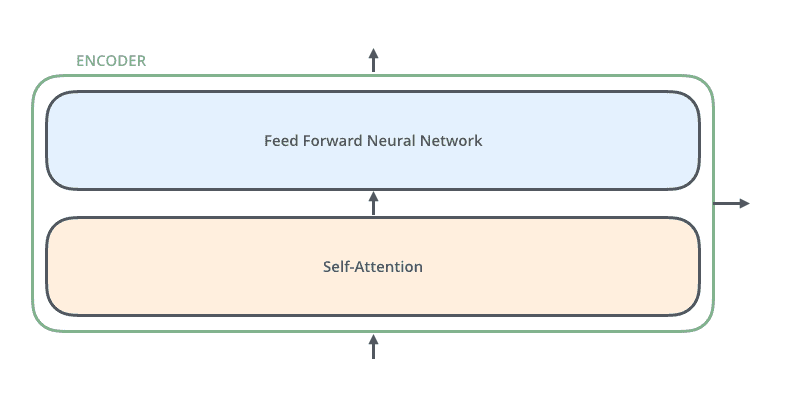
那每一个小编码器里边又是什么呢?
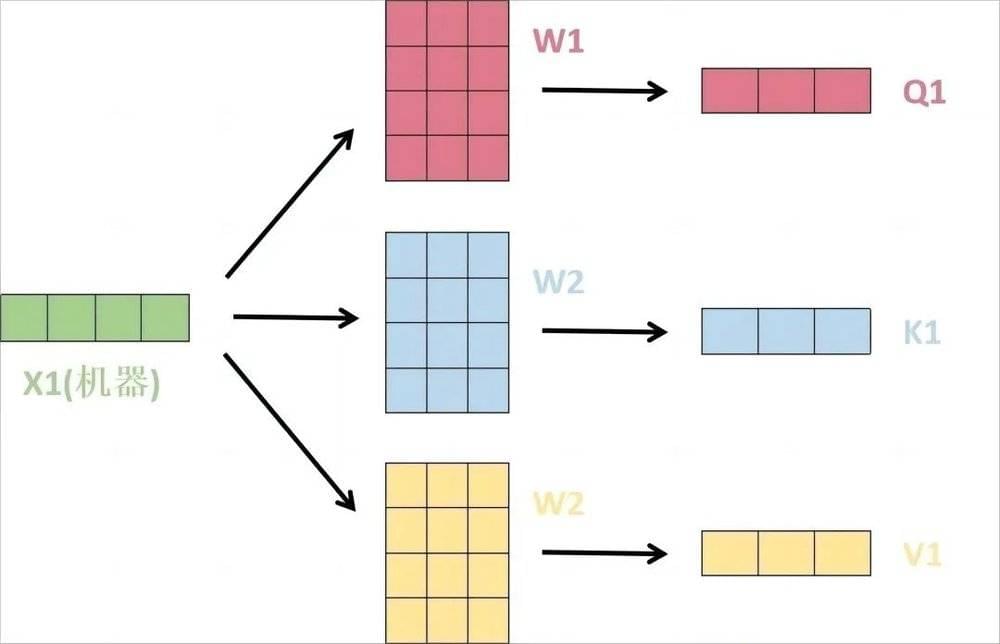
放大一个encoder,发现里边的结构是一个自注意力机制+一个前馈神经网络。
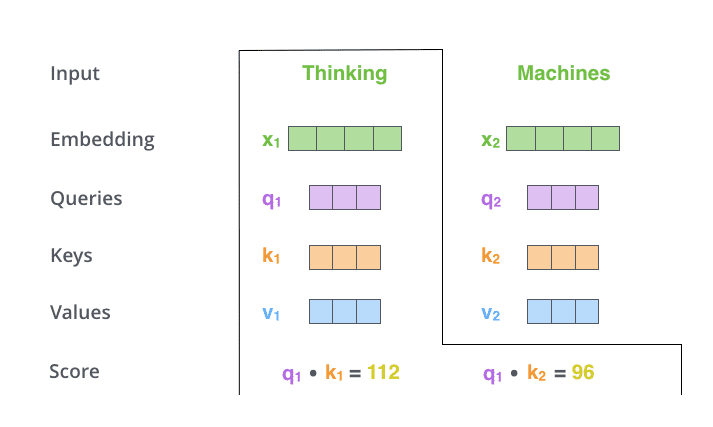
(2) 接下来就要计算注意力得分了,这个得分是通过计算Q与各个单词的K向量的点积得到的。以X1为例,分别将Q1和K1、K2进行点积运算,假设分别得到得分112和96。
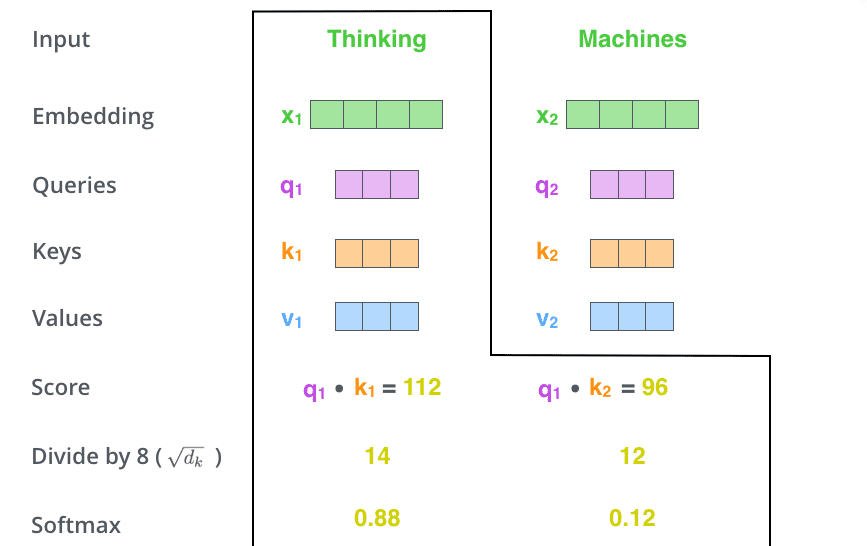
(3) 将得分分别除以一个特定数值8(K向量的维度的平方根,通常K向量的维度是64)这能让梯度更加稳定。
(4) 将上述结果进行softmax运算得到,softmax主要将分数标准化,使他们都是正数并且加起来等于1。
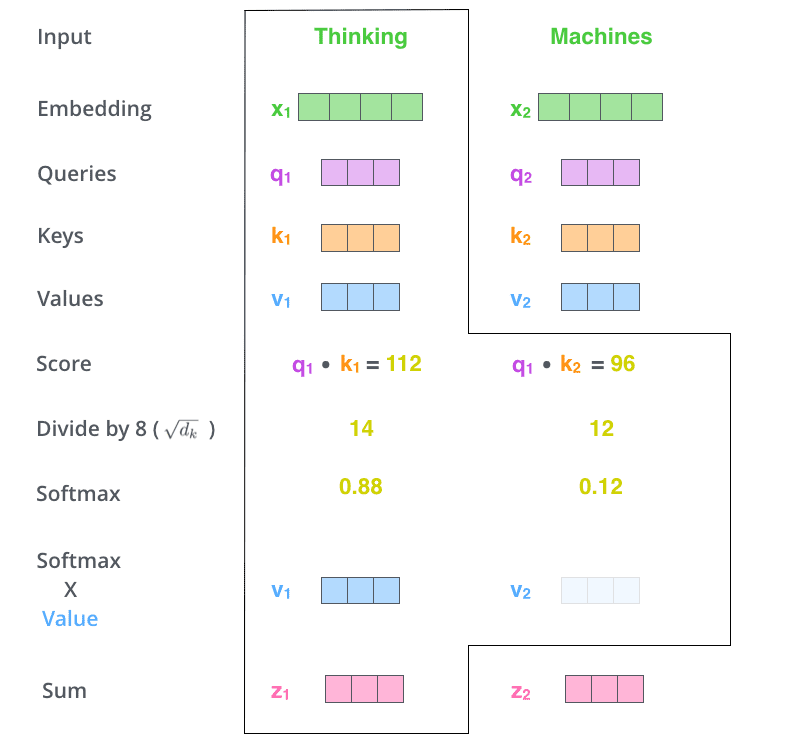
(5) 将V向量乘上softmax的结果,这个思想主要是为了保持我们想要关注的单词的值不变,而掩盖掉那些不相关的单词。
(6) 将带权重的各个V向量加起来,至此,产生在这个位置上(第一个单词)的Self-attention层的输出,其余位置的Self-attention输出也是同样的计算方式。
将上述的过程总结为一个公式就可以用下图表示:
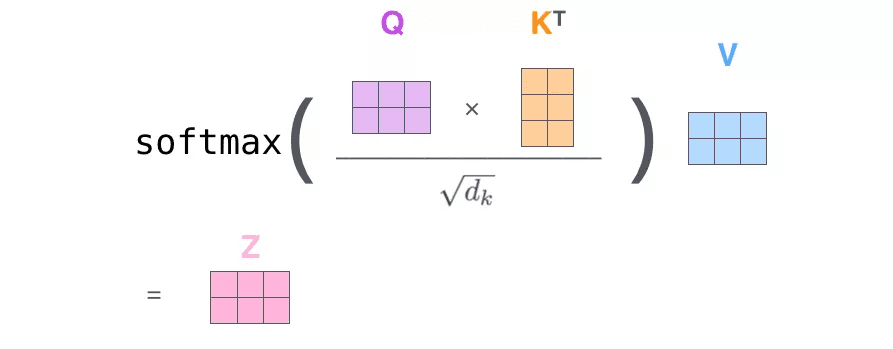
Self-attention层到这里就结束了吗?
还没有,论文为了进一步细化自注意力机制层,增加了“多头注意力机制”的概念,这从两个方面提高了自注意力层的性能。
第一个方面,它扩展了模型关注不同位置的能力,这对翻译一下句子特别有用,因为我们想知道“it”是指代的哪个单词。
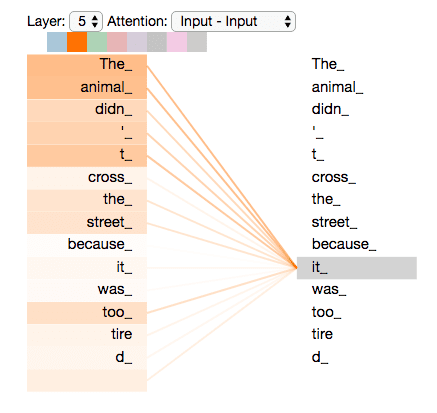

上述我们经过了self-attention层,我们得到了self-attention的输出,self-attention的输出即是前馈神经网络层的输入,然后前馈神经网络的输入只需要一个矩阵就可以了,不需要八个矩阵,所以我们需要把这8个矩阵压缩成一个,我们怎么做呢?只需要把这些矩阵拼接起来然后用一个额外的权重矩阵与之相乘即可。
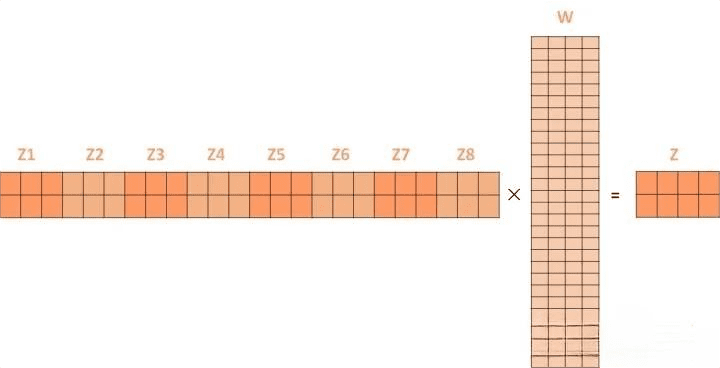
最终的Z就作为前馈神经网络的输入。
接下来就进入了小编码器里边的前馈神经网模块了。
然后在Transformer中使用了6个encoder,为了解决梯度消失的问题,在Encoders和Decoder中都是用了残差神经网络的结构,即每一个前馈神经网络的输入,不光包含上述Self-attention的输出Z,还包含最原始的输入。
上述说到的encoder是对输入(机器学习)进行编码,使用的是自注意力机制+前馈神经网络的结构,同样的,在ecoder中使用的也是同样的结构。
以上,就讲完了Transformer编码和解码两大模块,那么我们回归最初的问题,将“Je suis etudiant”翻译成“I am a student”,解码器输出本来是一个浮点型的向量,怎么转化成“I am a student”这两个词呢?
这个工作是最后的线性层接上一个Softmax,其中线性层是一个简单的全连接神经网络,它将解码器产生的向量投影到一个更高维度的向量(logits)上。
假设我们模型的词汇表是10000个词,那么logits就有10000个维度,每个维度对应一个惟一的词的得分。之后的Softmax层将这些分数转换为概率。选择概率最大的维度,并对应地生成与之关联的单词作为此时间步的输出就是最终的输出啦!
假设词汇表维度是6,那么输出最大概率词汇的过程如下:
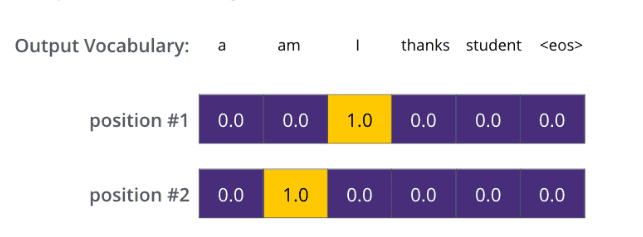
以上就是Transformer的框架了,但是还有最后一个问题,我们都知道RNN中的每个输入是时序的,是又先后顺序的,但是Transformer整个框架下来并没有考虑顺序信息,这就需要提到另一个概念了:“位置编码”。
Transformer中确实没有考虑顺序信息,那怎么办呢,我们可以在输入中做手脚,把输入变得有位置信息不就行了,那怎么把词向量输入变成携带位置信息的输入呢?
我们可以给每个词向量加上一个有顺序特征的向量,发现sin和cos函数能够很好的表达这种特征,所以通常位置向量用以下公式来表示:
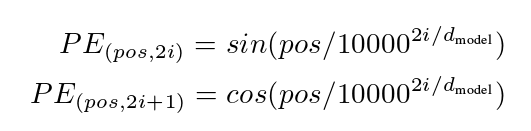
六、Transformer,在AI领域能形成大统一理论吗?
从以上技术可以看出:Transformer是通用深度学习模型。
它的适用性非常强,原因在于它的自注意力机制(self-attention mechanism),可以更好地处理序列数据。
那这里就要谈一个更前沿的技术:跨模态。
也就是人工智能领域,能否创造一个可以处理语言、文字、图片、视频的大统一模型。
如果在物理世界,那就有点像爱因斯坦追求的“大统一理论”。
在跨模态应用中,Transformer模型通常使用图像和文本特征作为输入信息。
❶ 使用自注意力机制来学习两个模态之间的关系。
❷ 使用多模态自注意力机制(multi-modal self-attention)来处理多个模态之间的关系。
Transformer应用于跨模态任务的效果非常好,在跨模态上取得成功的几个例子:
CLIP:CLIP是一种使用Transformer的联合训练框架,同时使用图像和文本来预训练模型。该模型能够将自然语言描述和图像联系起来,在多个视觉推理任务上取得了非常出色的表现。
DALL-E:DALL-E是OpenAI发布的一个模型,该模型通过预训练得到了非常强大的生成能力,在生成包括飞行的大象、色彩斑斓的沙漏等具有挑战性的图像时表现出色。

AI绘画的老玩家一定知道这两个产品。
Transformer在各个方向上齐头并进,形成了庞大的Transformer家族。
那么,Transformer会在AI领域能形成大统一理论吗?
现在得出这样的结论为时过早,AI领域应用非常复杂,需要结合各种技术和算法才能解决,期待单一的模型解决所有问题,有点难。
但人类对于AGI的期待,又是实实在在的。
七、记住那些无名的技术英雄
Transformer如此强大,仍然没有几个人知道。就算是背后站着谷歌这样的巨人,同样被大众忽略。
此时光芒四射的ChatGPT,连太阳的光辉都能够遮盖。可实际上,没有Transformer的开源,就没有ChatGPT。
从技术谱系上来看,ChatGPT只是Transformer家族中的一员。其它谱系的成员,同样表现优秀且杰出。
如果一定要说未来谁能引领人工智能世界,我更相信是Transformer而非ChatGPT。
这里引出来另一个问题,我们不能只看到成功的山姆·阿尔特曼(Sam Altman),还要看到ChatGPT后面更多的技术英雄。例如:
Ashish Vaswani等人:提出自注意力机制Transformer模型;
Bradly C. Stadie等人:提出RLHF这种人类反馈机制;
Ilya Sutskever, Oriol Vinyals等人:提出Seq2Seq模型;
EleutherAI团队:创建GPT-Neo模型的社区项目,是GPT-3的一个分支。
Hugging Face团队:开发了PyTorch和TensorFlow库。
Brown等人:在GPT-3论文中提出了新颖的训练策略。
…...
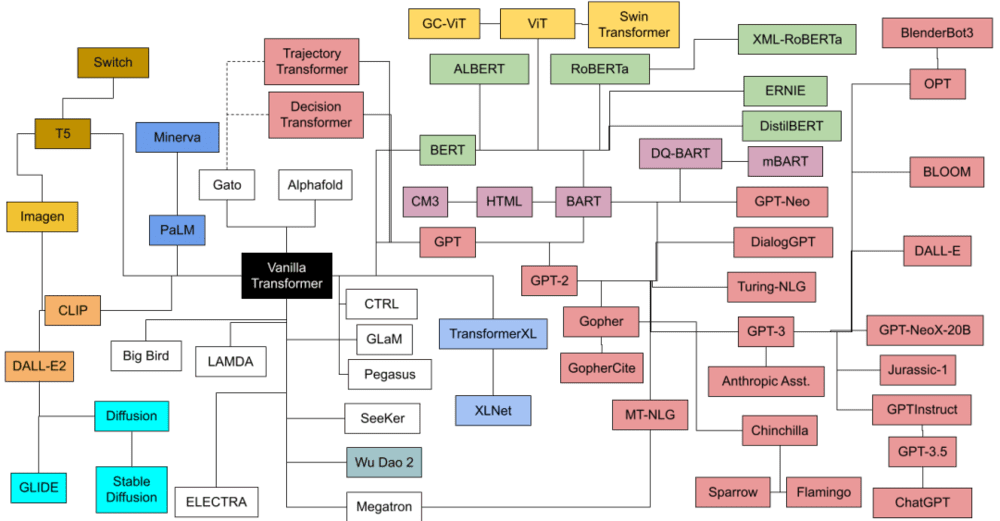
这样的人还有很多,也许他们只是充满着理想主义的科学家、工程师、数学家和程序员,他们在商业上毫无追求,也不是最后的名利收割者。
但是,我们需要记住这些人。
当我看着Transformer那张经典的技术原理图时,莫名会有一种心悸,甚至百感交集,这里面容纳了上千上万智者的心血啊。真的美,又真的让人痛。对知识的追求,千折百回,这是我们人类最值得骄傲的品质吧。
当你看到Transformer的原理图时,你会感动吗?
本文来自微信公众号:量子学派 (ID:quantumschool),作者:十七进制