
本文来自微信公众号:Mindverse Research(ID:gh_be9d7092abf7),作者:John K. Tsotsos(约克大学电气工程与计算机科学系特聘教授)、Iuliia Kotseruba(博士生),编译:胡鹏博,原文标题:《AI认知架构四十年:发展与挑战》,题图来自:《机械姬》
认知架构(Cognitive Architecture)是通用人工智能研究的一个子集,始于 1950 年代,其最终目标是对人类思维进行建模,这将使我们更接近构建人类水平的人工智能。此外,认知架构试图提供证据来表明特定机制能够成功地产生智能行为,从而有助于认知科学的研究。本文概述了过去 40 年对认知架构的研究,尽管现有架构的数量接近几百个,但大多数现有的综述都不能反映这种增长,并专注于少数成熟的架构。

在实践中,“认知架构”一词不那么严格,大多数学术论文中将认知架构定义为智能的蓝图,或者更具体地说,是关于实现一系列智能行为的心理表征和计算程序的支撑。 从历史上看,心理学和计算机科学是认知架构的灵感来源,即人类认知过程的理论模型和相应的软件工件,允许演示和评估潜在的心理理论。认知架构通常具有与人类认知能力相对应的功能模块,并解决行动选择、适应性行为、高效数据处理和存储等问题。
在本文中,作者选择了 84 个架构,并借鉴了一组不同的学科来进行分类,涵盖了从心理分析到神经科学的领域。图中的认知架构按综述中的引用总数和每个认知架构的在线来源进行排序,本文涉及的认知架构的标题被标注为红色。虽然主要架构的理论和实际贡献是不可否认的,但它们只代表了该领域的研究的一部分。因此,在这篇综述中,目标是展示过去 40 年开发的广泛、包容性、中立的概述,目的是通过展示已尝试的想法的多样性来启发未来的认知架构研究。
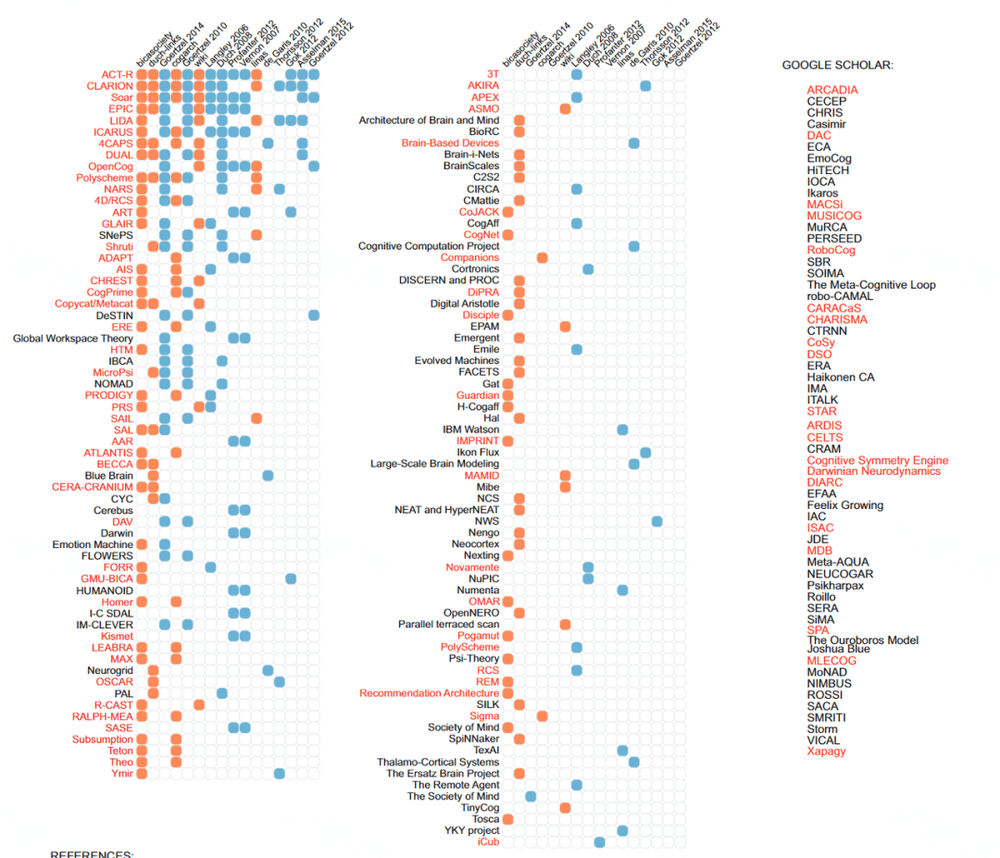
下图中则呈现了 84 种认知架构的时间线。每行对应一个架构。架构按起始日期排序,以便最早的架构绘制在图中的底部。颜色对应于不同类型的架构:符号(绿色)、神经(红色,在生物学上受到启发)和符号-神经混合(蓝色)。
根据这些数据,自 1980 年代中期到 1990 年代初以来,基于符号的架构居多,但是在 2000 年代后,大多数新开发的架构都是混合架构和神经架构,在时间线中分布相当均匀。
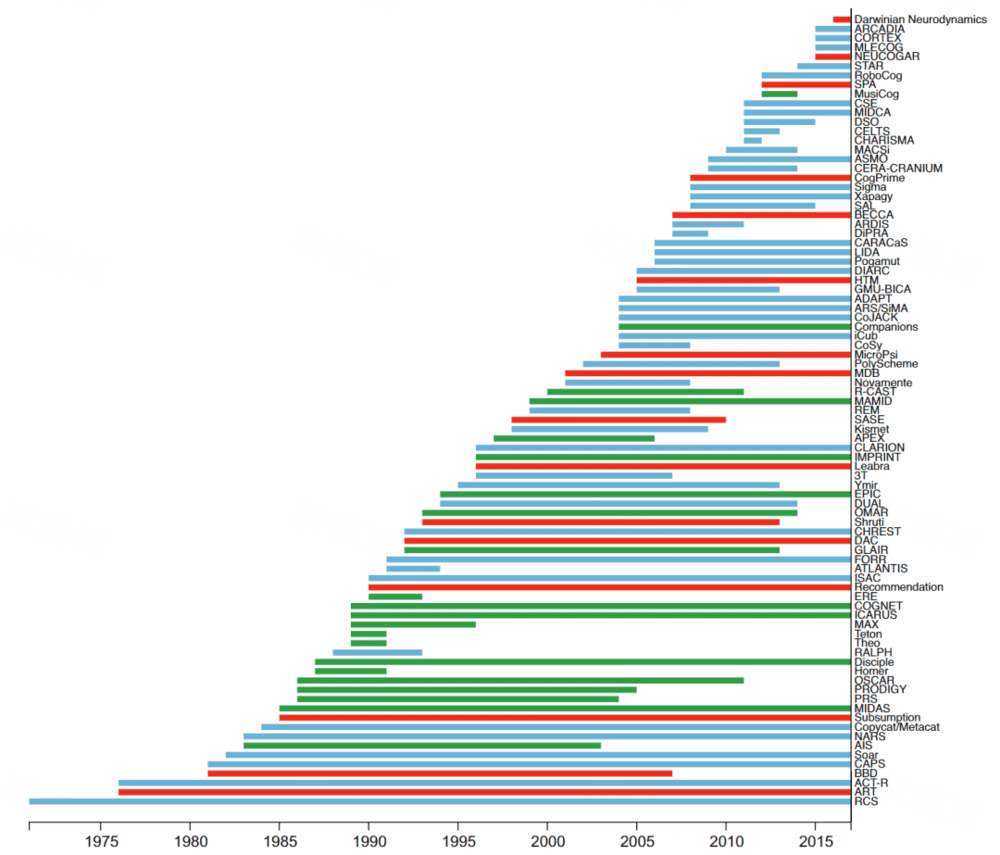
模型分类(Taxonomies of cognitive architectures)
在没有明确的认知定义和一般理论的情况下,每个架构都基于一组不同的前提和假设,使得比较和评估变得困难。Newell 的标准(The Newell Test for a theory of cognition)包括灵活的行为、实时操作、合理性、大型知识库、学习、开发、语言能力、自我意识和大脑实现。
Sun 的定义(Desiderata for cognitive architectures)更广泛,包括生态、认知和生物进化现实主义、适应、模块化、日常性和协同互动。根据 Sun 提出的观点,基于心理的认知架构应该通过不仅对人类行为进行建模以及潜在的认知过程来促进对人类思维的研究。与面向软件工程的“认知”架构不同,此类模型是一般人类认知机制的显式表征,这对于理解大脑至关重要。
模型大概可以分成三类,涌现架构/神经架构(Emergent,受到生物启发的架构,主要是神经流派,因此下文中统一称为神经架构),混合架构(Hybrid,包含了符号和神经流派),符号架构(Symbolic)。其中,混合架构汇总包含子字符号处理的分类,表示其更偏向于符号流派,但是至少用到了一些神经模块。
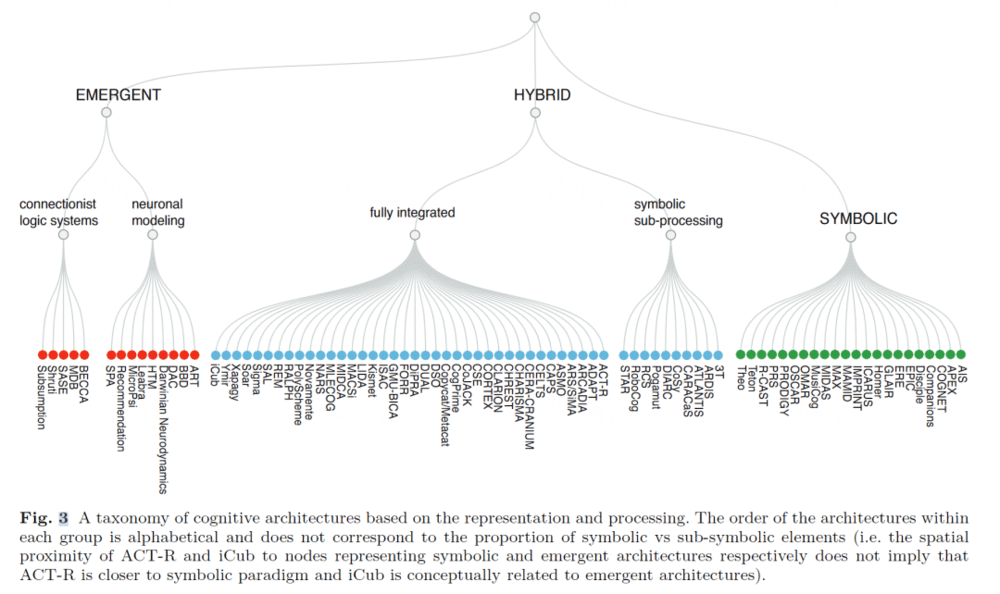
感知(Perception)
无论其设计和目的如何,智能系统都不能孤立地存在,并且需要输入来产生任何行为。虽然历史上主要的认知架构侧重于更高层次的推理,但很明显,感知和动作在人类认知中起着重要作用。感知可以定义为将原始输入转换为系统内部表征以执行认知任务的过程。根据传入数据的来源和属性,区分多种感知模态。例如,五个最常见的是视觉、听觉、嗅觉、触觉和味觉。
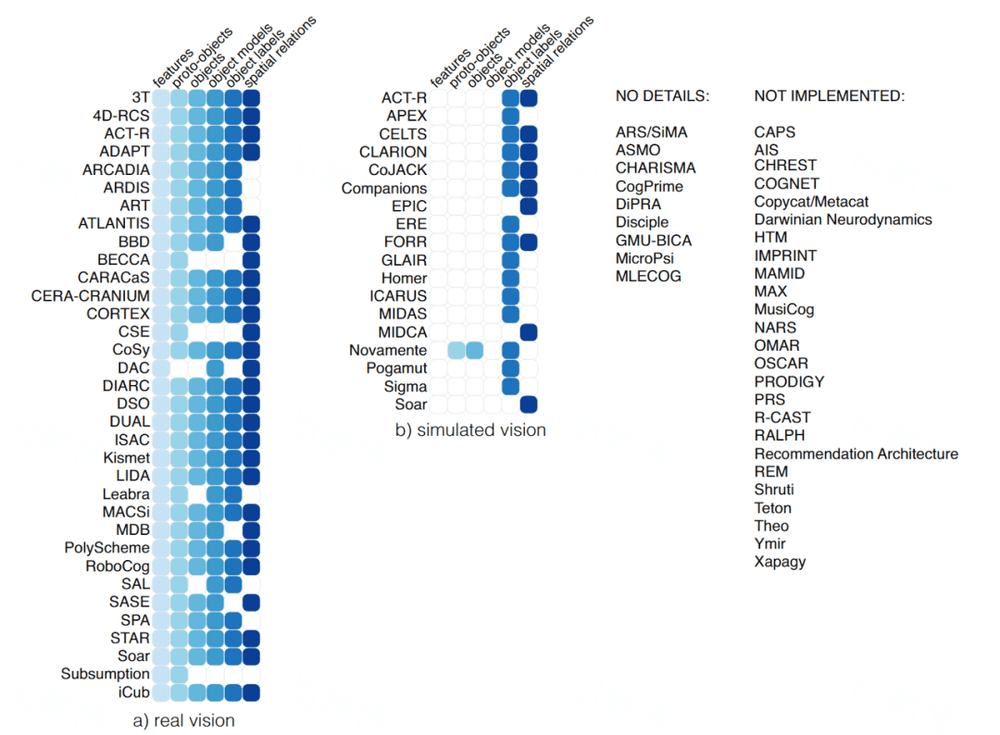
从图 4 的可视化结果中可以得出几个观察结果,其中,字母分别对应——V:视觉(vision),D:符号输入(symbolic input),P:本体感觉(proprioception), O:其他感觉(other sensors),A:听觉(audition),T:触觉(touch),S:嗅觉(smell),M:多模态感觉(multi-modal)。逆时针,越靠后涉及的模态越多。
可以看出,视觉是被最广泛涉及的,但是,超过一半的架构使用模拟进行视觉输入而不是物理相机。某些感觉仍然相对而言没有被充分探索,例如对气味的感觉仅以三种架构(GLAIR 、DAC 和 PRS )出现。
总体而言,设计的符号架构的感知能力有限,倾向于使用直接数据输入作为唯一的信息来源。另一方面,混合架构和神经架构(主要位于图表的右半部分)实现了更广泛的感官模式,包括模拟传感器和物理传感器。然而,无论其来源如何,传入的感官数据通常无法以原始形式使用(除了符号输入),并且需要进一步处理。
视觉的输入,主要包含了 2 种,第一种是物理世界输入,第二种是模拟视觉输入。物理世界输入指的是由真实相机拍摄的图片,或者已有的图片,以像素为主。模拟视觉系统通常省略早期和中间视觉,并以适合视觉处理后期阶段的形式接收输入(例如形状和颜色的符号描述、对象标签、坐标等)。
注意(Attention)
注意在人类认知中起着重要作用,因为它介导了相关信息的选择,并从传入的感官数据中过滤掉不相关的信息。有充分的证据表明,注意是一组影响知觉和认知过程的机制,目前,视觉注意仍然是研究最多的注意形式,因为其他感官模式没有全面的框架。
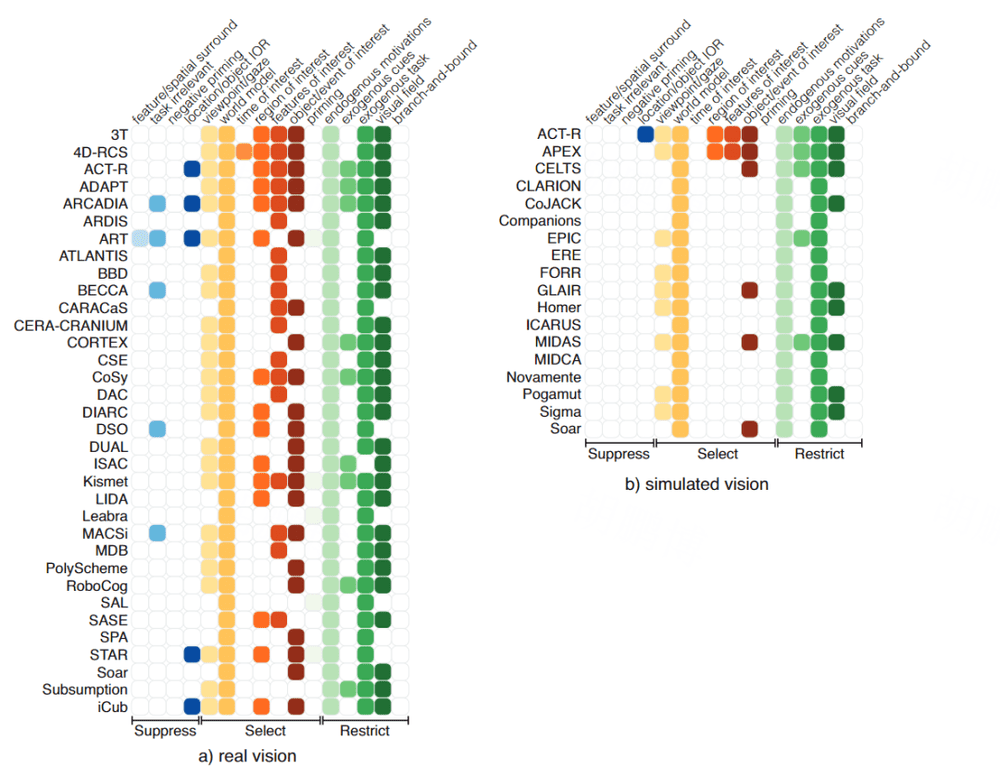
注意的元素分为三类信息缩减机制:选择(selection)、限制(restriction)、和抑制(suppression):
选择机制包括注视和视点选择、世界模型(选择要关注的对象/事件)和感兴趣的时间/区域/特征/对象/事件;
限制机制用于内生动机(领域知识)、外生线索(外部刺激)、外生任务(严格关注与任务相关的对象)和视野(有限的视野)来修剪搜索空间;
抑制机制包括特征/空间环绕抑制(在参与时暂时抑制物体周围的特征)、任务无关的刺激抑制、负启动和位置/对象抑制返回(一种偏向于将注意力返回到先前参与的位置或刺激)。
*参考:A Computational Perspective on Visual Attention
根据上述描述,对模型中使用注意机制涉及到的方向进行汇总(抑制、选择和限制机制分别用蓝色、黄色和绿色阴影表示):
在认知和心理文献中,注意也被用作分配有限资源的广泛术语。例如,在全局工作空间理论(GWT)中,注意机制对于感知、认知和动作至关重要。根据 GWT,神经系统被组织为并行运行的多个专家模块。受 GWT 影响的其他架构包括 ARCADIA 和 CRA-CRANIUM,以及 LIDA。在 CGNET 中实现了类似的想法,DUAL 和Copycat/Metacat,其中多个模块也竞争注意力。
动作选择(Action selection)
动作选择主要是确定“接下来做什么”,其可以分为涉及决策的部分和与运动控制相关的部分。然而,这种区别并不总是在文献中明确做出的,其中动作选择可能指的是目标、任务或命令。例如,在 MIDAS 架构动作选择中,动作选择既涉及下一个目标,又涉及实现它的动作 。类似地,在 MIDCA 中,如果存在,则通常从计划的序列中选择下一个动作。
除此之外,不同的机制还负责采用基于动态确定优先级的新目标,在 COGNET 和 DIARC 中,任务/目标的选择会触发相关程序知识的执行。在 DSO 中,选择器模块在可用的动作或决策之间进行选择,以达到当前的目标和子目标。
在本文中,作者区分了两种主要的动作选择方法:规划(planning)和动态动作选择(dynamic action selection)。
规划是指传统的 AI 算法,用于确定达到某个目标的一系列步骤,或者提前解决问题,目标递归分解为子目标的任务分解是一种非常常见的规划形式(例如 Soar, Teton, PRODIGY)。
与规划对立的是反应性动作(Reactive Action),其会立即执行,暂停任何正在进行的活动并绕过推理,类似于人类的反射动作作为刺激的自动响应。然而,纯反应性系统很少见,反应动作仅在某些条件下使用。例如,它们被用来保护机器人免受碰撞(ATLANTIS, 3T)或自动响应意外刺激。
在动态动作选择中,根据当时可用的知识,在备选方案中选择一个最佳动作,包括有限状态机(CSM),它们经常用于表征运动动作序列(ATLANITIS, CARAACS),甚至对系统的整个行为进行编码(ARDIS, STAR)。概率动作选择也很常见(iCub, CSE, CogPrime, Sigma, Darw.Neurodynamic, ERE, Novelemente)。
动机系统(Motivation System)
动机本质上是对动作选择进行干预和调整,因此,作者将动机系统放入到了动作选择部分汇总,在这里,我们将动机系统独立成为一节。在选择下一个动作时可以考虑几个标准:相关性 relevance、效用 utility 和情感 emotion(包括动机、情感状态、情绪、心境、欲望 等)。
1. 相关性
反映了动作与当前情况的匹配程度。这主要适用于具有符号推理的系统,并在应用规则之前检查规则的前置和/或后置条件(MAX、Disciple、EPIC、GLAI、PRODIGY、MIDAS、R-CAST、Disciple、Companions、Ymir、Pogamut、Soar、ACT-R)。
2. 动作的效用
是其对当前目标的预期贡献的度量(CERACRANIUM 、CHARISMA 、DIARC、MACSi 、MAMID 、NARS 、Novamente)。一些架构还对候选动作执行“干燥运行”(dry run),并观察它们确定其效用的影响(MLECOG 、RoboCog )。
效用还可以考虑过去动作的性能,并通过强化学习(ASMO、BECCA、CLARION、PRODIGY、CSE、CoJACK、DiPRA、Disciple、DSO、FORR、ICARUS、ISAC、MDB、MicroPsi、Soar)来提高未来的行为。其他机器学习技术也用于将目标与过去成功行为联系起来(MIDCA 、SASE 、CogPrime)。
内部因素不直接确定下一个行为,而是 bias 这个选择,为简单起见,这里考虑与人类情绪、驱动和人格特征相对应的短期、长期和终身因素。鉴于这些因素对人类决策和其他认知能力的影响,在认知架构中对情绪和情感进行建模很重要,尤其是在人机交互、社交机器人和虚拟代理领域。毫不奇怪,这是迄今为止花费的大部分努力的地方。
3. 情绪
认知架构中的人工情绪通常被建模为影响认知能力的瞬态状态(与愤怒、恐惧、喜悦等相关)。例如,在 CoJACK 中, 道德和恐惧情绪可以修改计划选择。因此,当道德较高时,面临威胁的计划具有更高的效用,但在恐惧较高时的效用较低。
其他示例包括影响背包策略的快乐/悲伤情绪(CHART)、焦虑状态中的类比推理(DUAL)、唤醒对记忆的影响(ACT-R)、根据目标满意度(DIARC)和 HCI 场景中的情绪学习(CELTS)的正面和负面影响。
4. 驱动(广义动机)
驱动是内部动机的另一个来源。从广义上讲,它们代表了食物和安全等基本生理需求,但也可能包括高级或社交驱动。通常,任何驱动的强度都会随着驱动的满足而减少。由于 agent 总是朝着其目标工作,一些驱动可能会同时影响其行为。
例如,在 ASMO 中,有三个相对简单的驱动:喜欢红色、想要表扬和幸福,通过修改权重来偏置动作选择相应的模块。在 CHARISMA 保存驱动(避免伤害和饥饿)中,结合好奇心和愿望自我改进来指导行为生成。在 MACSi 中,好奇心推动探索代理学习最快区域。同样,在 CERA-CRANIUM 中,好奇心、恐惧和愤怒会影响移动机器人对环境的探索。
社交机器人 Kismet 设置了驱动,结合外部事件有助于机器人的情感状态(或“情绪”),并通过面部手势、立场或声音语气的变化将其表达为愤怒、厌恶、恐惧、喜悦、悲伤和惊讶。尽管其动机机制是硬编码的,但 Kismet 展示了所有认知架构的最广泛情感行为库之一。
5. 人格特征
与具有瞬态性质的情绪不同,人格特征是独特的长期行为模式,在内部动机、情绪、决策等方面表现为一致的偏好。大多数已识别的人格特征可以简化为一小组必要的维度/因素,足以广泛描述人类人格(如五因素模型 FFM 和 Mayers-Briggs 模型)。同样,认知架构中的个性通常由几个因素/维度表征,不一定是基于已知模型。反过来,这些特征与系统可能与经历的情绪和/或驱动有关。
在最简单的情况下,单个参数足以在系统的行为中产生系统偏差。NARS 和 CogPrime 都使用“个性参数”来定义评估逻辑语句的真实性或分别规划下一个动作需要多少证据(LeCun 本质上也用的这种方法)。参数值越大,系统似乎越“保守”。
类似地,在 AIS 特征(例如 厌恶、冷静、害羞、自信、懒惰)中,被分配了一个整数值,它定义了它们所表现出的程度。规则定义了在给定个性的情况下更有可能的行为。在 CLARION 中,人格类型决定了许多预定义驱动的基线强度和初始缺陷(即倾向)。
CLARION 提供了一个认知上合理的框架,该框架能够解决情绪、驱动和个性特征,并将它们与包括决策在内的其他认知过程相关联。情绪的三个方面被建模:反应情绪(或情绪的无意识经验)、协商评估(可能有意识)和应对/行动(遵循评估)。
因此,情绪作为显式和隐式过程之间的交互出现,涉及(并影响)感知、动作和认知。MAMID 是由外部事件、内部解释、目标和个性特征产生的情绪产生和影响的模型。在内部,信念网络将任务和个人特定的标准联系起来,例如目标失败是否会导致特定代理中的焦虑。
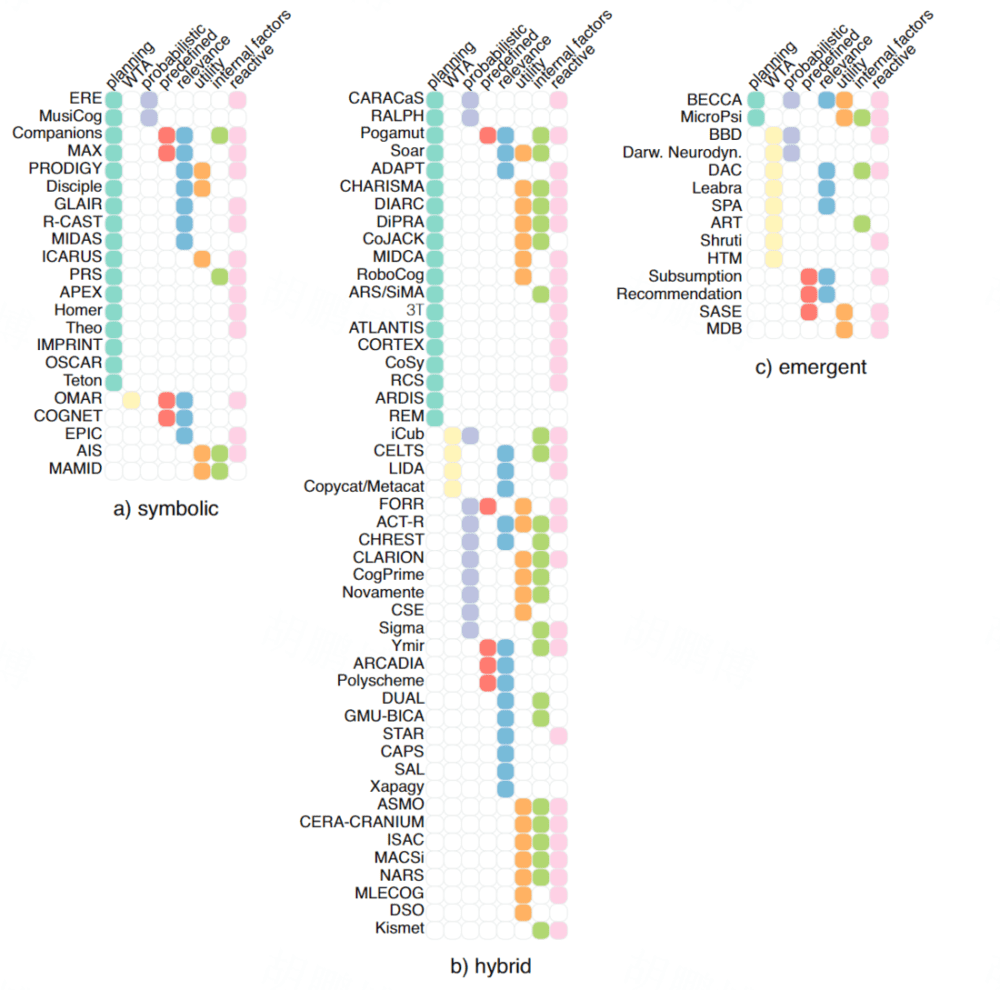
框架涉及到的动作选择方法(Planning,Reactive,WTA,Probabilistic,Predefined),一些指标(relevance,utility)和动机系统(internal factor,包括 emotion,drives,personality)。
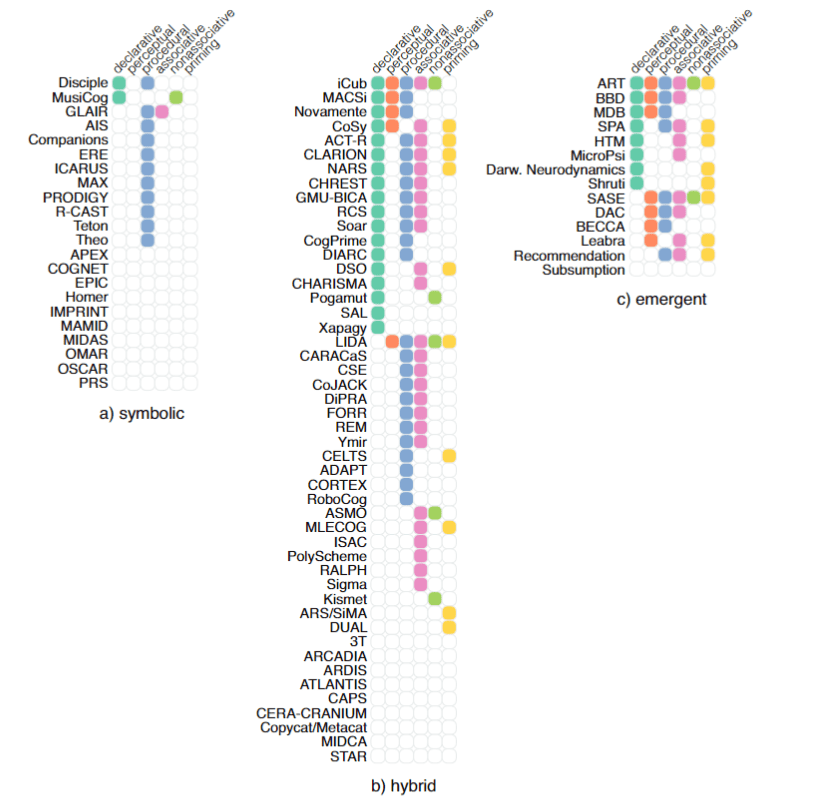
记忆(Memory)
记忆是任何系统级认知模型的重要组成部分,无论模型是否用于研究人类思维或解决工程问题。本文提到的几乎所有架构都具有存储计算中间结果的记忆系统,从而能够学习和适应不断变化的环境。然而,尽管它们的功能相似,但记忆系统的特定实现差异很大,并且取决于研究目标和概念限制,例如生物学合理性和工程因素(例如编程语言、软件架构、框架使用等)。
在认知架构文献中,记忆根据其持续时间(短期和长期)和类型(程序性、陈述性、语义等)来描述,尽管它不一定实现为单独的知识存储。
长期知识通常被称为事实和解决问题规则的知识库,这些规则对应于语义和程序的长期记忆(例如 Disciple、maci、PRS、ARDIS、ATLANTIS、IMPRINT)。一些架构还保存了以前实现的任务并解决的问题,模仿情景记忆(REM,PRODIGY)。短期存储通常由当前世界模型或目标堆栈的内容表征。
下图显示了架构实现的各种类型的记忆的可视化。在这里,遵循区分长期和短期记忆的惯例,长期记忆进一步细分为语义、程序性和情节类型,它们存储事实知识、在特定条件下应该采取什么行动的信息以及系统个人经验中的情节。
短期存储分为感觉记忆和工作记忆。感官或感知记忆是一个非常短期的缓冲区,它存储了几个最近的感知。工作记忆是感知临时存储,它也包含与当前任务相关的其他项目,并且经常与当前的注意力焦点相关联。
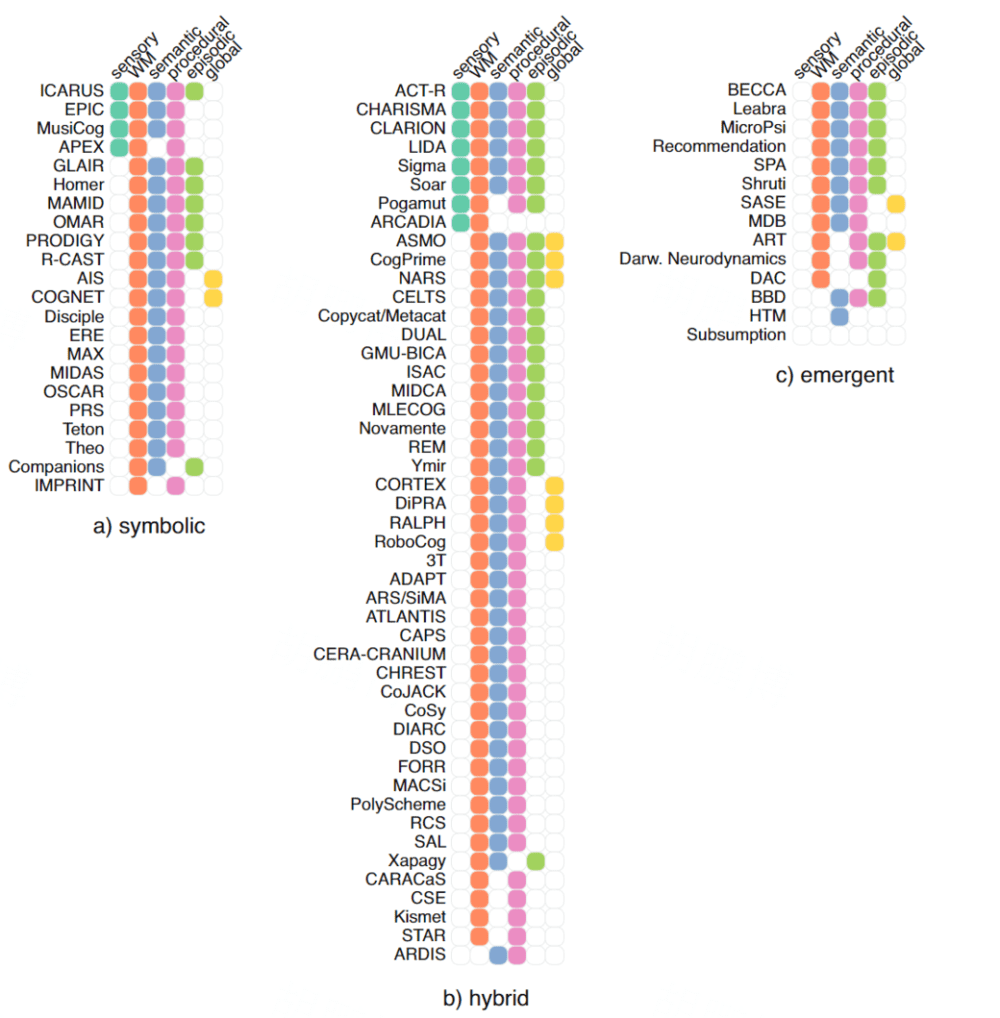
1. 感知记忆
感知记忆的目的是缓存传入的感官数据并在将其转移到其他记忆结构之前对其进行预处理。其有助于解决连续性和维护问题,即识别对象的单独实例相同,并在无人参与时保留对象的印象(ARCADIA)。类似地,回声记忆允许声学刺激长时间持续存在以检测绑定和特征提取,例如音高提取和分组(MusiCog)。
感知记忆中项目的衰减率被认为是视觉数据的数十毫秒(EPC, LIDA),并且对于音频数据更长(MusiCog),尽管并不总是指定时间限制。实现这种记忆类型的其他架构包括 Soar、Sigma、ACT-R 、CHARSMA , CLARION 、ICARUS 和 Pogamut 。
2. 工作记忆
工作记忆可以定义为临时存储与当前任务相关的信息的机制。这对于注意力、推理和学习等认知能力至关重要,本质上,所有认知框架都以某种形式间接地实现了工作记忆。工作记忆的特定实现主要在于存储哪些信息、如何表征、取用和维持。
尽管工作记忆对人类认知很重要,但相对较少的出版物提供了有关其内部组织和与其他模块联系的充分细节。许多工作记忆或等效结构的架构中,工作记忆主要作为当前世界模型的缓存、系统的状态和/或当前目标。尽管工作记忆能力没有明显限制,但新的目标或新的感官数据通常会覆盖现有内容。
关于工作记忆的实现,有以下几种:
工作记忆保存着最相关的知识,这些知识是由上层“归纳偏置”决定的长期记忆检索出来的。这种“归纳偏置”被称为激活,包括每次访问时的基本级激活(可能会减少或增加),也可能包括来自邻近元素的扩散激活。元素的激活越高,它就越有可能进入工作记忆,并直接影响系统的行为,这中情况比较适用于基于图的知识结构(Soar, CAPS , ADAPT, DUAL , Sigma , CELTS, NARS ,Novamente, MAMID)。
激活也可以用于神经网络表征(Shruti , CogPrime,Recommend,SASE,Darwin. Nerualdynamic)。激活机制有助于模拟工作记忆的许多属性,例如有限容量、时间衰减、随着环境变化而快速更新、与其他记忆组件的连接以及决策。
黑板架构,它将记忆表征为目标、问题和部分结果的共享存储库,可以由并行运行的模块访问和修改(AIS、CERA-CRANIUM、CoSy、FORR、Ymir、LIDA、ARCADIA、Copycat/Metacat、CHARISMA、PolyScheme、PRS)。
工作记忆是一种相对较小的临时存储器,从生物现实主义的角度来看,它的容量应该是有限的。然而,对于应该如何做到这一点,人们并没有达成共识。例如,在 GLAIR 中,当代理切换到一个新问题时,工作记忆的内容将被丢弃。
一种更常见的方法是,根据条目在变化上下文中的最近性或相关性,逐渐从记忆中删除它们。CELTS 架构通过为感知分配与感知情境的情绪效用成正比的激活级别来实现这一原则,这个激活级别随着时间的推移而变化,一旦它低于设置的阈值,感知就会被丢弃。Novamente 认知引擎也有类似的机制,只要原子与其他记忆元素建立了联系,并增加了它们的效用,它们就会留在记忆中。
目前还不清楚在这些条件下,工作记忆的大小是否可以在没有任何额外限制的情况下大幅增长。此外,记忆中的组块数量决定了硬限制,例如,ARCADIA 中有 3~6 个对象,CHREST 中有 4 个组块,MDB 中最多有 20 个项。然后,当新信息到达时,旧的或最不相关的项目将被删除,以避免溢出。
3. 长时记忆
长时记忆(LTM)在很长一段时间内保存大量的信息。通常,它分为包含内隐知识(如运动技能和日常习惯)的程序性记忆和包含(外显)知识的陈述性记忆。陈述性记忆又进一步细分为语义记忆(事实记忆)和情景记忆。
在认知框架中,长时记忆是对于知识的长期存储,使系统能够运行,因此几乎所有的架构都实现了程序性或语义性记忆,程序性记忆包含了在任务域中如何完成任务的知识。在符号生产系统中,程序知识由一组针对特定领域预编程或学习的 if-then 规则表征(3T, 4CAPS, ACT-R, ARDIS, EPIC , SAL, Soar , APEX)。
语义记忆存储关于对象的事实和它们之间的关系。在支持符号推理的体系结构中,语义知识通常被实现为图结构的形式,其中节点对应概念,链接表征它们之间的关系(Disciple, MIDAS, Soar, CHREST)。在神经架构中,事实知识被表征为神经网络中的激活模式(BBD, SHRUTI , HTM , ART)。
4. 全局记忆(Global Memory)
尽管存在不同的记忆系统,但一些架构对不同类型的知识或短时记忆和长时记忆没有单独的表征,而是使用统一的结构来存储系统中的所有信息。例如,CORTEX 和 RoboCog 使用了一个集成的动态多图对象,它可以表征感官数据和描述机器人和环境状态的高级符号。
同样,AIS 实现了一个全局记忆,它结合了知识库、中间推理结果和系统的认知状态。DiPRA 使用模糊认知地图来表征目标和计划。NARS 在 Narcese 中以形式句的形式表现了所有的经验知识,无论它是陈述性的、情景性的还是程序性的。类似地,在一些神经架构中,如 SASE 和 ART,神经元作为工作记忆或长期记忆的作用是动态的,取决于神经元是否被激发。
总的来说,认知架构中的记忆研究主要涉及记忆的结构、表征和提取。相对来说,很少有人关注与维护大规模记忆存储相关的挑战,因为智能代理的域和时间跨度通常是有限的。相比之下,人类的记忆容量非常大。
因此,可供选择的解决方案包括利用现有的大规模数据管理方法和改进检索算法。例如 Soar 和 ACT-R 使用 PostgreSQL 关系数据库从 WordNet 加载概念和关系。另外,SPA 支持一种生物学上合理的联想记忆模型,能够使用 spike 神经元网络在 WordNet 中表征超过 100K 个概念。
学习(Learning)
学习是系统随着时间的推移提高其性能的能力。归根结底,任何形式的学习都是基于经验的。例如,系统可能能够从观察到的事件或从其自身操作的结果推断事实和行为。下图显示了所有认知架构的关于学习类型的可视化。
1. 感知学习
感知学习适用于主动改变感官信息加工方式或在线学习模式的架构。这种学习通常用于获得关于环境的内隐知识,例如空间地图(RCS, AIS, MicroPsi),聚类视觉特征(HTM , BECCA , Leabra)或发现感知之间的关联。许多系统使用预学习组件来处理感知数据,例如物体和面部检测器或分类器。
2. 陈述性学习
陈述性知识是关于世界的事实以及它们之间定义的各种关系的集合。在许多生产系统中,如 ACT-R 等,它们实现了分块机制,当一个新的块被添加到声明性存储器中时(例如,当一个目标完成时),新的声明性知识就会被学习。
类似的知识获取也在具有分布式表征的系统中得到了证明。例如,在 DSO 中,知识可以由人类专家直接输入,也可以作为从标记的训练数据中提取的上下文信息学习。
新的符号知识也可以通过对已知事实应用逻辑推理规则来获得(GMU-BICA,NARS)。
3. 程序性学习
程序性学习指的是学习技能,通过重复逐渐发生,直到技能成为自动的。最简单的方法是积累成功解决问题的例子,以供以后重用(例如AIS , R-CAST, RoboCog)。例如,在导航任务中,可以保存经过的路径,并在以后再次用于在相同位置之间穿行(AIS)。显然,这种类型的学习是非常有限的,需要进一步处理积累的经验,以提高效率和灵活性。
基于解释的学习(EBL)是一种常见的技术,用于从许多具有符号表征的程序知识的架构中学习经验(PRODIGY, Teton, Theo, Disciple, MAX, Soar, Companions, ADAPT, ERE, REM, CELTS, RCS)。简而言之,它允许将单个观察到的实例的解释概括为一般规则。
然而,EBL 并没有扩展问题域,而是在类似的情况下使解决问题更有效。这种技术的一个已知缺点是,它可能导致规则太多(也称为“效用问题”),这可能会减慢推断。为了避免模型知识的爆炸,可以应用各种启发式方法,例如在规则可以包含的事件上添加约束(CELTS)或消除低使用块(Soar)。尽管 EBL 并非生物学启发,但已有研究表明,在某些情况下,人类学习可能会表现出类似 EBL 的行为。
符号程序性知识也可以通过归纳推理(Theo, NARS)、类比学习(Disciple, NARS)、行为调试(MAX)、概率推理(CARACaS)、关联和外展(RCS)和显式规则提取(CLARION)来获得。
4. 联想学习
联想学习是一个广义的术语,指受奖惩影响的决策过程。在行为心理学中,它被研究在两个主要的范式:经典条件反射和操作条件反射。主要形式为强化学习(RL)及其变体,如 temporal difference learning、Q-learning、Hebbian learning 等,常用于联想学习的计算模型中。
有大量证据表明,基于错误的学习是决策和运动技能习得的基础。强化学习的简单性和效率使其成为最常见的技术之一,近一半的认知架构使用它来实现联想学习。
RL 的优点是它不依赖于表征,可以用于符号、神经或混合架构,这种技术的主要用途之一是发展适应性行为。在具有符号组件的系统中,它可以通过根据成功/失败来改变动作和信念的重要性来实现(例如 RCS, NARS, REM, RALPH, CHREST, FORR, ACT-R, CoJACK)。在混合和神经系统中,强化学习可以在状态和行为之间建立联系。联想学习可以应用于难以获得分析解的情况下,如软臂控制(ISAC)。
5. 非联想学习
非联想学习不需要把刺激和反应联系在一起。习惯化和敏感化通常被认为是非联想学习的两种类型。习惯化是指对重复刺激的反应强度逐渐降低。相反的过程发生在致敏过程中,即反复暴露于刺激会导致反应增加。由于它们的简单性,这些类型的学习被认为是其他形式的学习的先决条件。
例如,习惯化会过滤掉不相关的刺激,帮助人们关注重要的刺激,尤其是在没有正面或负面奖励的情况下。迄今为止,这一领域的大部分工作都致力于社会机器人和人机交互环境下的习惯化,以实现自适应和现实的行为。例如,ASMO 架构使机器人能够忽略不相关的(但显著的)刺激。
在跟踪任务中,机器人很容易被背景中的快速运动分散注意力。习惯化学习(作为附加到运动模块上的增强值实现)使其能够专注于与任务相关的刺激。在ASMO中,除了习惯化外,敏感化学习还允许社交机器人专注于被跟踪对象附近的运动,即使该运动可能很慢且不显著。
6. 启动(Priming)
启动(Priming)发生在先前暴露于刺激影响其后续识别和分类的情况下。大量实验证明了启动效应对各种刺激的存在,包括知觉、语义、听觉等,以及行为启动。
启动在心理学和神经科学中得到了很好的研究,在认知架构中发现了启动建模的两个主要理论框架:扩散激活(ACT-R、Recommend、Shruti、CELTS、LIDA、ARS/SiMA、DUAL、NARS)和吸引子网(CLARION、Dawin.NeuralDynamic)。目前研究社区的共识是,扩散激活具有更强的解释能力,但吸引子网络被认为在生物学上更合理。在这种情况下,似乎特定范式的选择也可能受到表征的影响。
例如,在局部架构中发现了扩散激活,其中单位对应于概念。当一个概念被调用时,相应的单元被激活,该激活被传播到相邻的相关单元,从而便于它们的进一步使用。或者,在吸引子网络中,一个概念由包含多个单元的模式表征,根据模式之间的相关性(相关性),激活一种模式会导致其他模式的激活增加。
推理(Reasoning)
推理是心理学和认知科学的焦点之一,作为一种逻辑和系统加工知识的能力,推理几乎可以影响或组织任何形式的人类活动。因此,除了经典的三种逻辑推理(演绎、归纳和外推)之外,其他类型的推理现在正在被考虑,如启发式、可消除推理、类比推理、叙事推理、道德推理等。
可以预见的是,所有认知架构都与实践推理有关,其最终目标是找到下一个最佳行动并执行它。在认知架构的背景下,推理主要涉及规划、决策和学习,以及感知、语言理解和问题解决。
人类以及任何具有人类智力水平的人经常面临的主要挑战之一是在知识不足的基础上采取行动,或者说“在普遍无知的背景下做出理性决定”。除了稀疏的领域知识外,可用的内部资源(如信息加工能力)也有局限性。
迄今为止,最集中的努力是用于克服在不断变化的环境中知识和(或)资源不足的问题。事实上,这是通用推理系统的目标,例如过程推理系统(PRS)、非公理推理系统(NARS)、OSCAR 和具有有限性能硬件的 Rational 代理(RALPH)。
PRS 是 BDI (信念-预期-意图)模型最早的例子之一,在每个推理周期中,它选择一个与当前信念匹配的计划,将其添加到意图堆栈中并执行它。如果在执行过程中产生了新的目标,就会产生新的意图。NARS 通过迭代地重新评估现有证据并相应地调整其解决方案来解决知识和资源不足的问题。这在非公理逻辑(Non-Axiomatic Logic)中是可能的,它将真值与每个语句关联起来,从而允许智能体表达他们对信念的信心。
RALPH 利用决策理论的方法解决复杂领域中复杂的目标驱动行为,因此,计算等同于行动,效用值(基于其预期效果)最高的行动总是被选择。OSCAR 架构探索了可消除的推理,即理性上令人信服但不演绎有效的推理,这是对日常推理的一种更准确的表征,在这种情况下,知识很少,任务复杂,没有衡量成功的特定标准。
上面提到的所有架构都旨在创建具有人类智能水平的理性系统,但它们不一定试图模拟人类的推理过程。而 ACT-R、Soar、DUAL 和 CLARION 等架构的目标,则试图模拟人类推理过程。特别是,在 ACT-R 中实现的人类推理模块是在假设人类推理是概率性和归纳性的前提下工作的。这是通过将基于规则的确定性推理机制与具有类似人类记忆属性的长期陈述性记忆(即不完整和不一致的知识)相结合来证明的。知识和产生式规则中固有的不确定性共同促成了类似人类的推理行为。
人类高级认知是否具有固有的符号化仍然没有解决。到目前为止所考虑的符号和混合架构,主要将推理视为一种符号操作。许多新兴的基于神经的体系结构,例如ART、HTM、DAC、BBD、BECCA,似乎根本不加工推理,尽管它们确实表现出复杂的智能行为。
迄今为止,神经架构中符号推理(以及其他低级和高级认知现象)最成功的实现之一是由 SPA 表征的。像这样的架构也提出了有趣的问题,尝试将认知的符号部分与子符号部分分开是否有意义。由于大多数现有的认知架构代表了从纯符号到连接主义的连续统一体,人类认知可能也是如此。
元认知(Metacognition)
元认知,直观地定义为“对思考的思考”,是一组内省地监控内部过程并对其进行推理的能力。由于元认知在人类经验中的重要作用,以及识别、解释和纠正错误决策的实际必要性,人们对开发人工智能体的元认知越来越感兴趣。本文中大约三分之一的架构,主要是具有重要符号组件的符号架构或混合架构,支持与决策和学习有关的元认知。
元认知机制包括自我观察、自我分析和自我调节。其需要收集有关系统内部操作和状态的数据数据,这些数据通常包括内部资源的可用性/需求(AIS, COGNET , Soar)和当前任务知识(CLARION, CoJACK , Companions, Soar)。
此外,一些架构支持当前和/或过去解决方案的时间表征(跟踪)(Companions, Metacat, MIDCA)。收集数据的数量和粒度取决于进一步的分析和应用,在决策应用中,在确定了可用资源的数量、冲突的资源请求、条件的差异等之后,系统可能会改变不同任务/计划的优先级(AIS、CLARION、COGNET、CoJACK、MAMID、PRODIGY、RALPH)。
对过去问题的执行和/或记录解决方案的跟踪可以促进学习。例如,可以利用过去解决方案中发现的重复模式来减少未来类似问题的计算(Metacat, FORR, GLAIR, Soar)。
尽管理论上许多体系结构都支持元认知,但它的实用性只在有限的领域得到了证明。例如,Metacat 将元认知应用于微观领域的类比推理字符串(例如 ABC→abd; MRRJJJ→?)。元认知允许系统记住过去的解决方案,比较不同的答案并证明其决策是正确的。
在 PRS 中,元认知能够在玩《奥赛罗》等游戏时有效地解决问题,更好地控制模拟车辆以及对不断变化的环境的实时适应。元认知可以进行内部错误监控,即实际和预期感知输入之间的比较,使系统能够确定其操作在简单任务中的成功或失败,例如堆叠块,并在未来学习更好的操作。
元认知是社会认知所必需的,尤其是心理学文献中所说的心理理论(Theory of mind, ToM)。ToM 指的是能够承认和理解他人的心理状态,利用对他人心理状态的判断来预测他们的行为,并为自己的决策提供信息。
很少有体系结构支持这种能力。例如,最近,Sigma 演示了 ToM 的两种不同机制,并将其作为几个单阶段同时移动游戏的例子,例如著名的囚徒困境。第一种机制是自动的,因为它涉及到网格图的概率推理,第二种机制是跨问题空间的组合搜索。
PolyScheme 将 ToM 应用于人机交互场景中的视角获取,在这个场景中,机器人和人类一起在一个有两个交通锥和多个遮挡元素的房间里。这个人发出一个命令,向一个圆锥移动,但没有指明是哪个圆锥。如果人类只能看到一个锥体,机器人可以从人类的视角建模场景,并使用该信息消除命令的歧义。
另一个例子是在错误信念任务中对信念进行推理。在这个场景中,两个代理 A 和 B 观察到一个放在罐子里的饼干。B 离开后,饼干被移到另一个罐子里。当 B 回来时,A 可以推断 B 仍然相信饼干仍然在第一个罐子里。
问题与挑战(Problems and challenges)
1. 感知问题
在嘈杂的非结构化环境中运行的机器人架构中,感知问题最为严重。经常提到的问题包括缺乏主动视觉、精确的定位和跟踪、噪声和不确定性下的稳健性能以及利用上下文信息来改进检测和定位。
最近,深度学习被认为是自下而上感知的可行选择,总的来说,与更高层次的认知能力相比,对感知的加工,特别是对视觉的处理,无论是在捕捉潜在的过程还是实际应用方面,都是相当肤浅的。其他感觉方式,如听觉、本体感觉和触觉,通常依赖于现成的软件解决方案,或者通过物理传感器/模拟来实现。支持它的架构中的多模态感知是机械地处理的,是为特定的应用程序量身定制的。最后,知觉与高层次认知之间自下而上和自上而下的相互作用在理论和实践中都被忽视了。
2. 学习问题
尽管各种类型的学习在认知架构中都有体现,但仍然需要开发更健壮和灵活的学习机制、知识迁移,以及在不影响先前学习的情况下积累新知识。学习对于认知建模的发展方法尤其重要,特别是运动技能和陈述性知识。自然的沟通,言语交流是人工智能体与人类之间最常见的互动方式,基于这个方式的学习通常缺乏稳健性。
3. 记忆问题
尽管记忆是任何计算模型的必要组成部分,在认知架构领域得到了很好的表现和研究,但相对而言,情景记忆还没有得到充分的研究。这种记忆结构的存在早在几十年前就已经为人所知,它对学习、交流和自我反思的重要性也得到了广泛的认可,然而,在认知的计算模型中,情景记忆仍然相对被忽视。对于人类思维的一般模型,如 Soar 和 ICARUS,也是如此,最近才纳入它。
目前,大多数架构将事件保存为带有时间戳的系统状态快照。这种方法适用于生命周期短、表征细节有限的智能体,但终身学习和管理大规模内存存储需要更精细的解决方案。
4. 计算性能
由于显而易见的原因,计算效率问题在机器人架构和交互式应用中更加紧迫。时间和空间的复杂性在文献中被掩盖了,经常用定性的术语来描述(例如“实时的”,没有具体细节)或完全从讨论中省略。一个相关的问题是规模问题。事实证明,将现有算法扩展到更大量的数据会带来额外的挑战,例如需要更有效的数据处理和存储。这些问题目前只有少数架构可以解决,尽管解决这些问题对于进一步发展理论和应用人工智能至关重要。
5. 评估系统
认知架构的比较评价,共同承认的问题的解决取决于制定客观和广泛的评价程序。我们已经提到的问题之一是,单个体系结构是使用一组脱节和稀疏的实验来验证的,这不能支持关于系统能力的声明,也不能充分评估其表征能力。然而,在架构之间进行比较和测量该领域的总体进展需要额外的挑战。
构建一个认知架构是一个重大的课题,甚至需要数年的开发来将基本的组件放在一起(在我们的样本中,项目的平均年龄约为 15 年),随着时间的推移,任何重大更改都变得更加困难。因此,评价对于确定更有前景的方法和剔除次优勘探路径至关重要。
在某种程度上,通过理论考虑和多年来积累的集体经验,它已经有机地发生了。例如,曾经占主导地位的符号表征正在被更灵活的神经表征方法所取代,或者被子符号元素所增强(例如Soar,REM)。显然,需要更一致和更有针对性的努力,以使这一进程更快和更有效。
理想情况下,适当的评估应该针对认知架构的每个方面,使用理论分析、软件测试技术、基准测试、主观评估和挑战的组合。所有这些已经被少量地应用到单个体系结构中。例如,最近对主要认知架构中使用的知识表征的理论检查揭示了它们的局限性,并提出了修正它们的方法。
通过一系列任务探测多种能力的测试被建议用于评估认知架构和通用 AI 系统。一些例子包括,“认知十项全能”和 I-Athlon,它们都受到图灵测试的启发,以及检查智力因素的卡特尔-霍恩-卡罗尔模型或 Samsonovich 等人提出的用于评估不同认知维度的一系列测试。然而,这一领域的大部分工作仍停留在理论上,尚未产生可执行的具体建议或完整的框架。
本文来自微信公众号:Mindverse Research(ID:gh_be9d7092abf7),作者:John K. Tsotsos(约克大学电气工程与计算机科学系特聘教授)、Iuliia Kotseruba(博士生),编译:胡鹏博