
本文来自微信公众号:果壳 (ID:Guokr42),作者:翁垟,编辑:卧虫,头图来自:视觉中国
一边在朋友圈晒年度听歌总结,一边抱怨“华语乐坛不行了”,这“习俗”延续多少年了?
平台收听榜上怎么还是周杰伦?综艺节目里怎么还是张韶涵?KTV 里怎么还是“死了都要爱”?超市里怎么还是“恭喜你发财”?

最简单暴力的回答是:新歌都不行,华语乐坛已经完蛋了!
《青年理工工作者生活研究所》研究员小凡不太信服这套说辞,作为机械设计制造及其自动化出身的一位理工科生,他想,是否能用一种基于计算的、更客观的方式,真实地展现这些年华语音乐的变化,一举终结这场疑问和争吵?
抱着这个想法,他进入了一场意想不到的、为期一整年的漫长搏斗,最终,得出了一个有些超出预期的答案。
答案在声波中飘
理想的方式是设计一套算法,教会机器给歌曲打分。好歌分高,差歌分低,再比较一下分数,一目了然。但好与坏,既抽象又主观,想让机器得出客观量化的评价,就必须先在歌曲之间进行比较计算。
这意味着第一件事就是要将一首歌转换为数字。小凡选择的是分析一首歌的声波。
把一首歌放到剪辑软件里,就会看到它的波形。这个波形不仅能呈现一首歌声音的大小,同时也包含了很多其他信息。人耳仅仅通过听就可以轻松分辨出一首歌的歌手、风格、类型,甚至是现场还是录音。如何让电脑也能听懂呢?通过深度学习。
首先,他把每首歌掐头去尾,随机截取 90 秒音频,分成连续的 1800 个小段,每一段做傅立叶变换。每一个音都是由多个不同的频率振动组合而成,在这里,傅立叶变换的作用就是把每个小段中包含的频率分离出来,以便深度学习模型理解。

计算后,每首歌都变成了一个 1800 列乘 3248 行的数据表格,表明这 90 秒歌曲中都包含了哪些频率。因为数据量太大,他继而进行了两次压缩,将代表每段歌曲的数据缩减到 600 个数字。
这个过程可以理解成一张图片像素不断降低的过程,期间信息发生了大幅的减损。为了保证图片质量降低后你仍然能认出图片内容,保留哪些像素,剔除哪些像素就变得很重要。

小凡希望通过这 600 个数字是能“认出”这首歌的,就像识图的深度学习模型能认出一只狗是狗,一只猫是猫。
为训练这个模型,他收集了 1977 到 2022 年间的 5400 首流行歌曲。
这里的歌曲选择有一个原则,就是标签之间有交叉,“比方说 abc 三个歌手的歌里,都有 m 这个作曲家,那 a 唱的歌里面,还会找找其他人作曲的。网状的交叉越多,就对这个模型的学习就越有好处”。
这是为了避免模型在不同标签之间产生死板的关联,也就是算法偏见。比如周杰伦方文山是一个很常见的搭配,这时就要多找一些方文山给别人写的歌,来制造交叉。
接下来,他需要设置一些“正确答案”,一些能够描述这些歌曲的标签,歌手、作曲之外,还有年份、感情色彩、音乐类型、曲风、拍号、调式等。
学习过程简而言之,就是让神经网络通过层层计算得出 600 个数字,来猜测一首歌的对应信息:是谁唱的?什么调式?猜不准就返回去重新算,直到猜中为止,循环往复 5400 次。
回到打标签,起初,类别没有确定,他需要边听边总结。比如对于音乐类型,他就总结出纯音乐、反叛、恋爱悲伤、恋爱甜蜜、魔幻、生活、耍帅、主题等八种类型。
乍一看,这似乎并不足够细致全面,但实际上这一步并非要给歌曲提供一个十足科学的分类,“最大的目的是体现出歌之间的区分度,只要足够让类型不同的歌被打到不同的标签,之间不混淆就可以了。”
定下类别后,数据标记就成了纯纯的体力活。小凡完全投入其中,花了两三个星期才标注完五六百首歌,不得不对外求援,最终,雇了几位音乐专业的学生加入这项工作,前后花费了快两个月时间才完成。

“平均歌”也有春天
分类和数据标注之后,摆在小凡面前的仍是满满一堆数字——它们代表的意义是什么?又如何将这些数据抽丝剥茧结构起来,以回答开头那个争论不休的问题呢?
研究最开始,小凡想过一个“信息熵”的概念。简单理解就是一首歌信息的复杂程度。可以设计一个程序,检测每首歌之间是否存在重复相似,如果存在,就价值变低。
但这仍太抽象太复杂了,评判标准也不太有说服力。经历了近半年的“乱跑乱采访”,思路不断碰壁,他灵光一闪,一个新的概念浮现出来:平均歌。
平均,意味着普通、不出彩、烂大街,似乎不是一个正面的评价。但在歌曲的范畴里,它却也往往是最符合和体现大众口味的。从计算的角度,平均歌意味着在选定范围里,和这首歌相像的歌是最多的。
既然要计算平均,那就要先选出样本范围和参照系。
通过历年的网友总结和腾讯音乐榜单,他找到了从 1998 年开始,每年最热的 100 首歌的歌单,总共两千多首。
这时候,就可以搬出那个复杂的深度学习模型来进行计算了。利用模型,为每首歌生成能代表它们的 600 个数字——把它们看作 600 维空间中的点,就可以了解数字和数字之间的关系,计算平均点的位置。

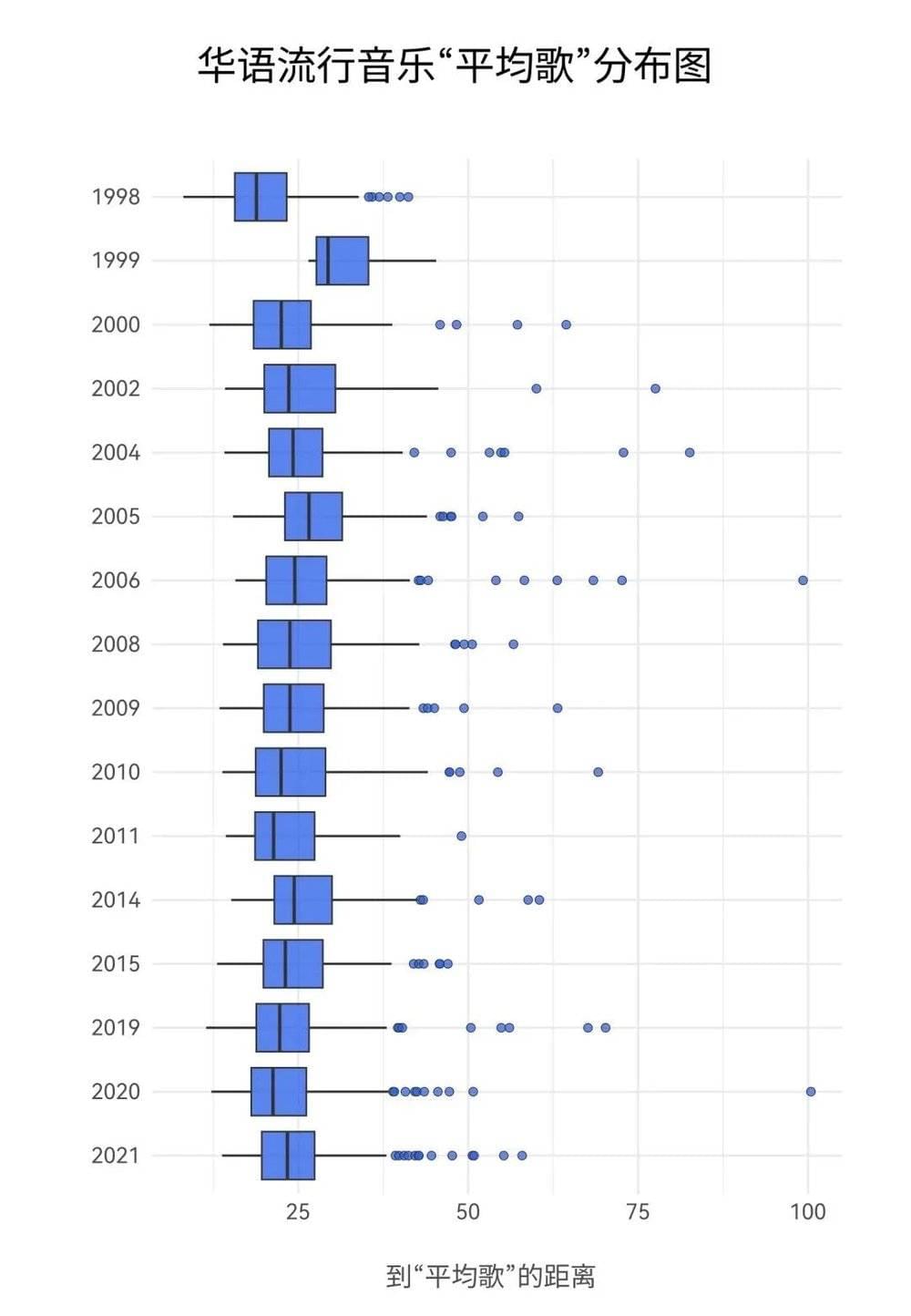
由于平均点上很可能并不存在一首真实的歌,那么平均歌就是最靠近那个点的那首歌。结论是一张长长的、经过排序的歌单,从中能看到每一年的平均歌是什么。

但这并没有如他起初设想的一样,验证那个简单粗暴的结论:华语歌越来越差了。反而,每一年的平均歌听下来并没有显现出那么大的变化。
小凡跑去征求工作室音乐编辑的意见。对方回应感受:⾳乐随着年代的变化中,混⾳的变化很明显, 90 年代很多歌曲以合成器⾳⾊为主导, 00 年代真实乐器的录⾳⽔平提⾼,近两年⾳⾊越来越激烈,可能和嘻哈⾳乐的兴起有关系。
但对于平均歌,共性反而大于不同:整体平均歌都是讲求明确清晰的主旋律,并且很少离调/转调/变换基础的节奏型。
这个结论似乎有点平淡,远不比人们的想象。
想把“离谱歌”唱给你听
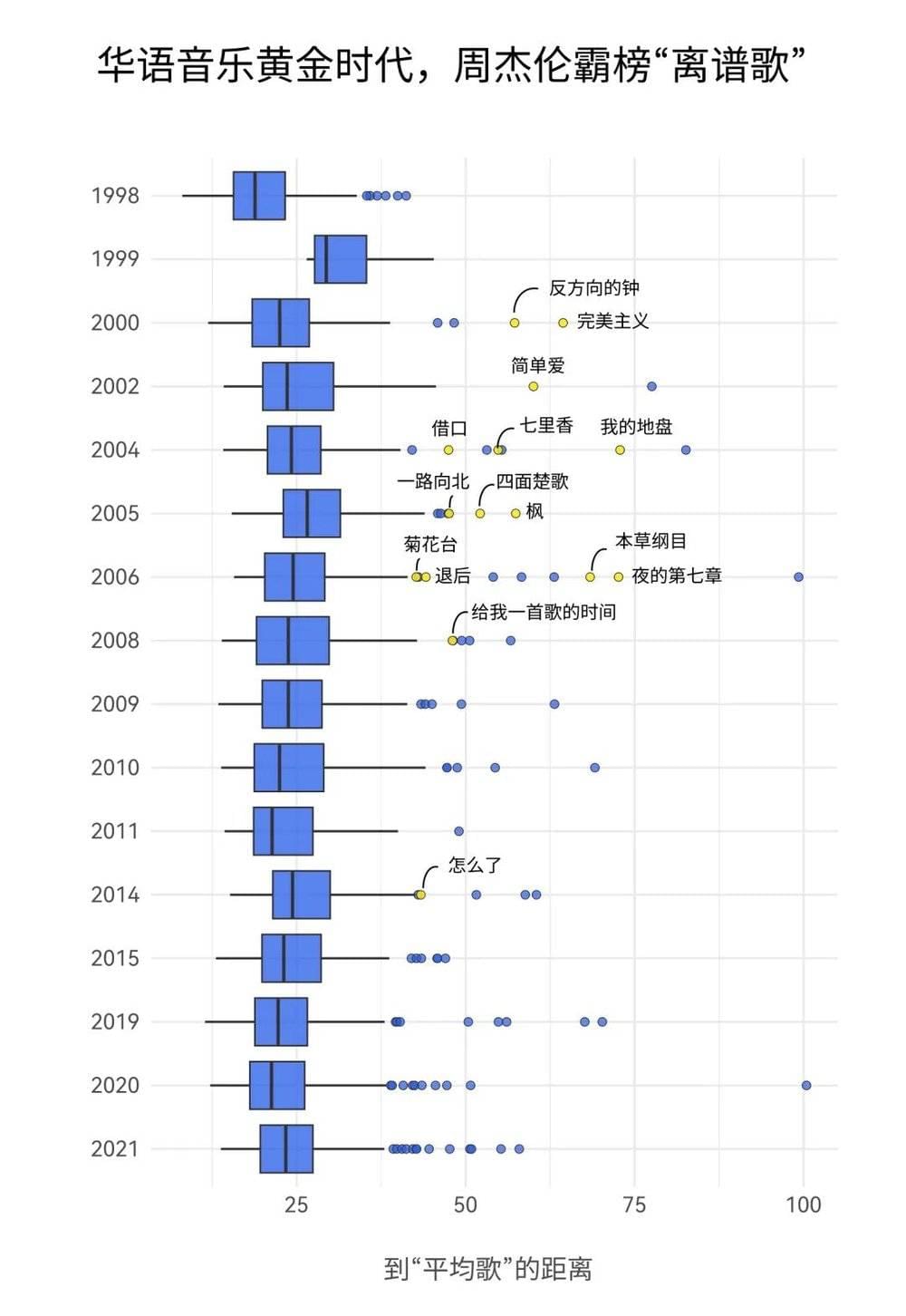
这时,小凡被最远离“平均”的那些数据所吸引了。歌单按照歌曲与平均点之间的距离排序,第一首是距离最近的,那么越往下便是距离越远的歌。这些歌在各自的特定年代都是特立独行,跟谁都不太一样——小凡把称它们为“离谱歌”。
离谱歌反而让人眼前一亮。首先,它们的确显现出相比于时代的“离谱性”,比如 1999 年位于倒数第五的《挫冰进行曲》,2004 年位于倒数第四的《波斯猫》。还有一个男人,在最活跃的十年几乎霸榜离谱歌榜单:周杰伦。
对此,乐评人重轻表示,周杰伦的⾳乐在许多⽅⾯背离传统和主流的⾳乐语⾔。所以他发专辑的年份都是离谱在列,“这是最了不起的,开拓边界的⾳乐⼈。”
整体而言,并非像许多人想象的,如今人的审美变得非常糟糕,才导致“抖音神曲”流行。反而,乐评人叨叨冯评价,“这份榜单体现出大众的主流审美其实变化是缓慢、相对稳定的”,但如果是为了迎合⼤众审美⽽创作,“那么写歌快、容易成为热歌的同时,也容易和以往的歌听起来相似”。
对于小凡来说,近几年的离谱歌他第一感受是“不爱听”,“像是蹦迪的歌,不是你愿意跟着唱的歌”。从数量上看,2010 年前的离谱歌看起来似乎也更离谱一些,离谱值高的歌曲数量更多。
创新性没有以前高,受欢迎的程度也远不比从前,这或许就导致这些原本应当开拓边界的离谱歌,不再像周杰伦的歌曲那样,具备挑战边界、引领大众审美的能力。
若算法回答是个错误,愿你我没有白白受苦
最初启动这个项目的时候,恰逢 2021 年末,一则视频在网络上被疯狂传阅,那是腾讯音乐发布的十大热歌榜单。听完网友几乎意见一致地给出结论:华语乐坛完蛋了。
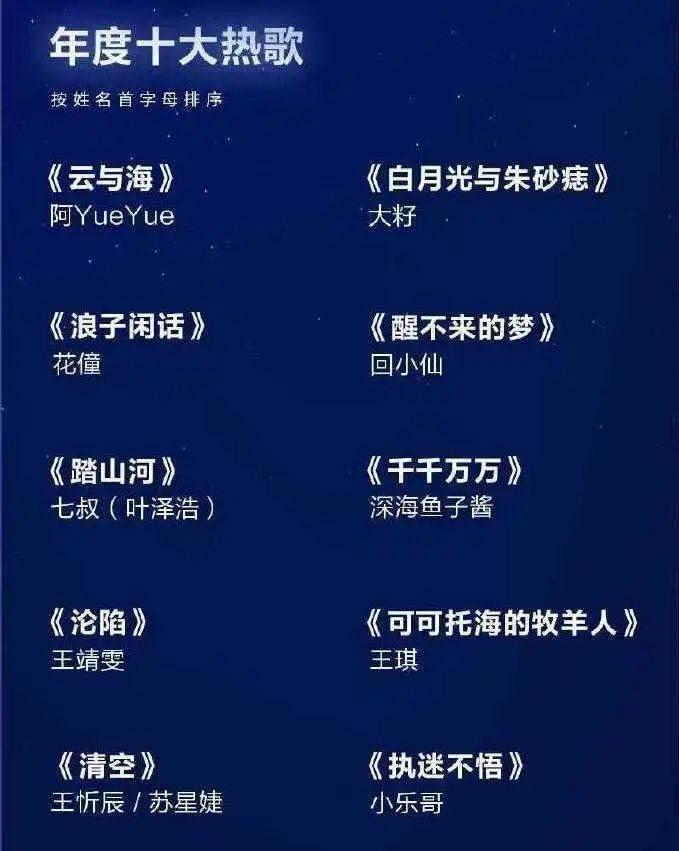
小凡对于这个话题的兴趣,不仅是想要验证它,也是源于对于这个论断的一丝怀疑。“总体上我还是比较相信,中国人也不笨,还是有很多人在写歌,理论上应该有好歌的,但为什么好像我们见不到,听不到?我很好奇。”
对于当前的结论,他多少感到有点遗憾,音乐没有变得更差,但作为艺术去激发我们,带来新奇感的能力似乎确实陷入了停滞。
但也不是所有人都认同这个结论。小凡将研究过程做成视频发到网上,引发网友之间激烈的讨论。有的网友认为,流行音乐并不等于音乐,流行音乐变成商品,变得套路化,但音乐本身仍处于无尽的创新和变化之中,只是在当前的机制下变得更难被人看到了。
也有人建议,可以把过去的“离谱歌”放到几年后对比,看它是否仍然“离谱”。
网友评论之外,这个研究将代表一段歌曲频率的 500 万个数字压缩到 600 个,势必面临过度简化,信息大量丢失的问题。这 600 个数字多大程度上能代表背后的这首歌呢?小凡看来,或许是七成左右。
进一步改进,理论上他也可以打更多的标签,让歌曲之间区分的更明显。目前这样的大分类之下,两首听起来挺不同的两首歌,还是有可能被打上相似的标签——就像人脸识别,将两个人的脸识别成一个人。
另一个遗憾是,在更正规的深度学习项目中还一定会设置交叉验证的过程。从不同的起点,用不同路径去算,看看能不能抵达相同的终点。这个研究中没能设置这样的环节。
那说到底,华语乐坛到底完没完蛋呢?
一番大费周章之后,人们仍没能得到一个可以一劳永逸的结论。这么做的意义或许就在于,为这个似乎无解的争论,拓展了讨论的可能性,在“回忆滤镜”、“奶头乐消费”之类用以互相攻击的词汇之外,提供了一个新的理解视角和一些新的论据。
参考文献
[1] 腾讯视频纪录片《青年理工工作者生活研究所》,第14集,华语乐坛真的要不行了吗?https://v.qq.com/x/cover/mzc00200p29k31e/r0045dm9z5v.html
[2] https://www.bmc.com/blogs/deep-neural-network/
[3] https://www.bilibili.com/video/BV1m8411P7v7/
本文来自微信公众号:果壳 (ID:Guokr42),作者:翁垟,编辑:卧虫