
本文来自微信公众号:半导体行业观察 (ID:icbank),作者:杜芹DQ,题图来自:视觉中国
虽然摩尔定律已经逐渐走到尽头,但我们却来到了一个更加看点十足的时代,不同于以往每隔18个月靠工艺迭代带来的常规演变,以英特尔、英伟达和AMD为首的芯片巨头之间的竞争变得异常激烈。从英特尔、英伟达、AMD三家的产品布局来看,三家几乎都集齐了CPU、GPU甚至是DPU产品线。如今,他们正在酝酿更大的规划。
随着近日AMD推出CPU和GPU组合的下一代数据中心APU——Instinct MI300,自此,三家的“多PU组合”争斗战已然打响。在此之前,英特尔的Falcon Shores XPU混合搭配CPU + GPU,英伟达的Grace Hopper Superchip是Grace CPU + H100 GPU的组合,都是如出一辙。他们都在做一件伟大的事情:在一个芯片中集成CPU、GPU和AI加速器,最终成为一个类似APU的产品,目标是更广阔的超级计算市场。但是在实现方式上,英伟达落后了?
英特尔的XPU计划之一:Falcon Shores
首先来说下英特尔的XPU计划?XPU是指使用多种计算架构,以最好地满足单个工作负载的执行需求的想法,这是英特尔过去几年来最感兴趣的一个方向。英特尔希望将X86和Xe结合起来用于超级计算/HPC市场。
在英特尔2022年年度投资者会议上,英特尔披露了一个代号为Falcon Shores的处理器新架构,它将x86 CPU和Xe GPU硬件组合到单个Xeon插槽芯片中,利用下一代封装、内存和 I/O 技术,为计算大型数据集和训练巨大AI模型的系统提供巨大的性能和效率改进。不过英特尔的目标似乎不仅仅是将CPU和GPU集成在一起,英特尔正在寻求为拥有绝对海量数据集HPC用户开辟市场——这种数据集无法轻松适应独立GPU相对有限的内存容量。
Falcon Shores的目标是在2024年推出,采用埃米级制程,这意味着它可能会使用Intel 20A或Intel 18A制造工艺制造。英特尔预计Falcon Shores在多个指标上比当前一代产品增长5倍,包括每瓦性能提高5倍,单个 (Xeon) 插槽的计算密度提高5倍,内存容量增加5倍,内存带宽增加5倍。

英特尔表示,Falcon Shores的混合设计是通过使用tile(也称为小芯片)实现的,通过提供X86和Xe内核之间的灵活比例,这将使芯片制造商在设计过程的后期配置芯片方面具有更大的灵活性。
AMD发布Instinct MI300 APU
近日,AMD在CES 2023上披露了其下一代数据中心处理器Instinct MI300,被AMD称之为“下一代数据中心APU”。它采用了13个Chiplet,共有1460亿个晶体管,MI300可以说是AMD迄今为止最大的芯片。
该芯片的计算部分由九个5nm小芯片组成,它们包含CPU或GPU内核,但AMD没有详细说明每个小芯片的使用数量。这九个裸片被3D堆叠在四个6nm基础裸片之上,而且这些裸片是有源的中介层,可以处理 I/O和各种其他功能。从下图中可以清晰看到,Instinct MI300中心芯片侧面的八个HBM3堆栈。

MI300的关键优势除了将CPU内核和GPU内核放在同一设计中的操作简单性之外,还在于它可以让两种处理器类型共享一个高速、低延迟的统一内存空间。这将使在CPU和GPU两个核之间快速且轻松地传递数据,能让每个核处理他们最擅长的计算任务。此外,它还可以通过让两种处理器类型直接访问同一内存池,简化插槽级别的HPC编程。
但是MI300芯片并不是批量产品,因为其价格昂贵且相对稀缺,所以它们不会像EPYC Genoa数据中心CPU那样得到广泛部署。AMD预计将在2023年下半年交付Instinct MI300。但是,这一Chiplet的设计技术将会衍生出更多的变体。
英伟达Grace Hopper Superchip
不同于英特尔和英伟达采用Chiplet架构的做法,英伟达首款GPU+CPU组合——Grace Hopper Superchip还是单芯片的方式,下图是渲染图。

NVIDIA®Grace Hopper架构将NVIDIA Hopper GPU与NVIDIA Grace™ CPU结合在一起,在单个超级芯片中连接高带宽和内存一致的NVIDIA NVLink Chip-2-Chip(C2C)®互连,并支持新的NVIDIA NVLink开关系统。
NVLink C2C是NVIDIA为超级芯片开发的内存相干、高带宽和低延迟互连技术。它是Grace Hopper超级芯片的核心,提供高达900GB/s的总带宽。这比加速系统中常用的x16 PCIe Gen5通道的带宽高7倍。结合NVIDIA NVLink切换系统,所有运行在最多256个NVLink连接的GPU上的GPU线程现在都可以以高带宽访问高达150TB的内存。
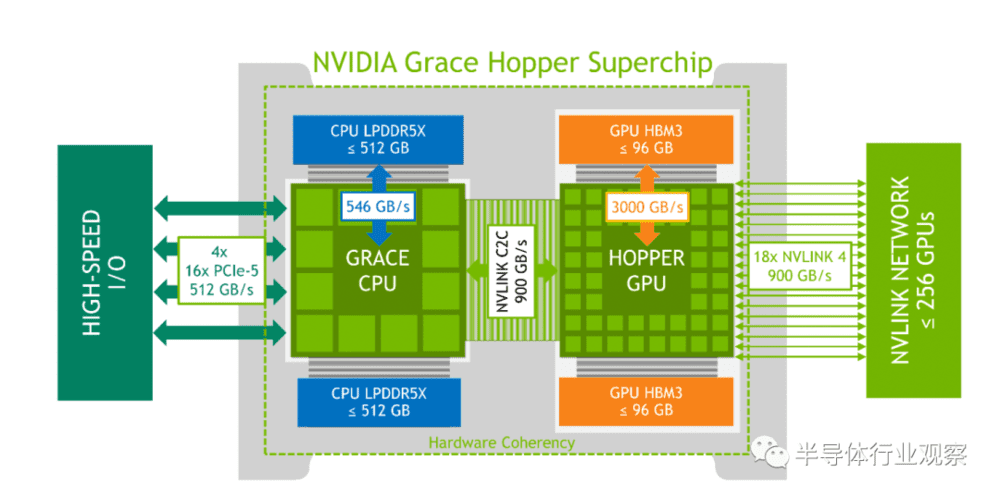
英伟达表示,该超级芯片将为运行TB级数据的应用程序提供高达10倍的性能提升,英伟达已承诺在2023年上半年推出其超级芯片。
可以看出,英特尔、英伟达和AMD都开始在CPU+GPU组合上发力,他们所采用的方式:要么芯片继续平铺做大,要么拼3D堆叠、Chiplet、拼架构,目前从各家的CPU+GPU组合型产品推出的时间点来看,AMD和英伟达都在2023年,而英特尔将在2024年。软件支持方面,英特尔有oneAPI,英伟达有CUDA,AMD似乎还稍逊一些。而在架构方面,英特尔、AMD均已奔向3D Chiplet,但英伟达似乎仍在单芯片上努力。
英伟达何时拥抱Chiplet?
Chiplet用于CPU已经不是新闻了,AMD多年来一直在其Ryzen和Epic等CPU处理器中使用Chiplet设计并取得了巨大成功。英特尔也于2023年1月11日正式发布了基于Chiplet设计的第四代至强CPU-Sapphire Rapids,它通过内置加速器将目标工作负载的平均每瓦性能提升了2.9倍,在优化电源模式下每个CPU节能可高达70瓦,将总体成本降低52%-66%。
但是就目前的情况来看,GPU也已迈入了Chiplet时代。如今英特尔和AMD已经均已发布了3D Chiplet CPU和GPU中的产品。而英伟达无论是GPU还是CPU似乎还在单芯片上努力,英伟达要落后了吗?
2023年1月11日,英特尔发布了其首款Chiplet小芯片封装的GPU,代号Ponte Vecchio,GPU Max系列单个产品整合47个小芯片,集成超过1000亿个晶体管。这是英特尔性能最高、密度最高的通用独立GPU。英特尔这一芯片的具体性能对比情况暂未可知,但是我们暂且可以看看AMD与英伟达的GPU性能对比。
AMD最新一代的GPU Navi 31,是AMD第一款、也可以说是历史上第一个基于Chiplet设计的GPU,AMD的两款最新显卡Radeon RX 7900 XTX和Radeon RX 7900 XT均是基于Navi 31。其中,XTX是旗舰机型,拥有更多的shader处理器,更高的内存带宽,更多的显存,而XT则是有些弱化的版本。
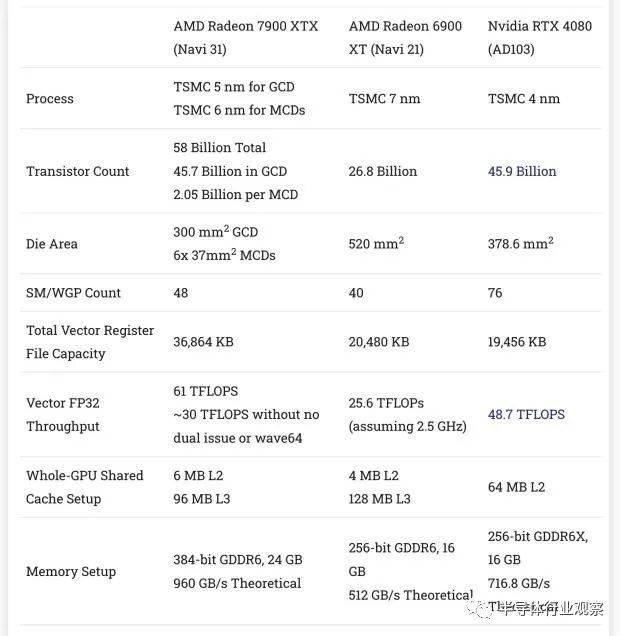
如果我们将AMD的显卡和英伟达的RTX 4080作对比,AMD的GPU的性能非常接近英伟达的RTX 4080。据chipsandcheese的评测对比数据,如下图所示,英伟达的4080采用4nm制程,晶体管密度比AMD的低一些,面积也更大一些,但英伟达4080具有更高的SM数量,这意味着寄存器文件和FMA单元相比AMD要有更多的逻辑控制。英伟达还具有更简单的缓存层次结构的优势,它仍然提供相当大的缓存容量。
英伟达的GPU目前做法还是将所有的晶体管,都放在一个更大的单芯片上,采用尖端工艺4纳米节点。
而AMD的Navi 31基于Chiplet设计和先进的RDNA3架构。其裸片由GCD核(图形计算芯片)和MCD内存小芯片(内存缓存芯片)组成。从下图可以清晰看到,中间部分是5nm制程的GCD核,周围分别是6颗6nm制程的MCD,包含内存控制器和Infinity缓存。这说明,着色器处理器和其他单元比较获益于先进工艺,而对于内存控制器和缓存来说则不必需要使用最先进的工艺。

两种不同工艺的芯片组装在一起,所使用的尺寸更小,与此同时,Chiplet的设计方式使得晶圆的缺陷芯片数量也少得多。从这个意义上来说,Chiplet架构的使用降低了成本。Chiplet的设计还有助于通过在图形芯片上使用更少的区域来实现VRAM连接,从而实现更高带宽的VRAM设置。但是也不是万利的,代价就是AMD必须支付更昂贵的封装解决方案,因为简单的封装走线在处理GPU的高带宽要求方面表现不佳。
此外,AMD Navi 31 GPU很重要的一项创新是Infinity Link总线,为何要说到这个呢?因为Chiplet的设计方式肯定会产生更多的延迟,而GPU是对延迟极其敏感的,所以AMD特意为此开发了全新的Infinity Link总线(即 Infinity Fanout Links 系统)来连接GDC和MCD部件,从而在GCD和MCD小芯片部件之间实现5.3 TB/s的带宽,这种超级先进的互连系统无疑是小芯片GPU设计的关键决定因素。
可以说,AMD的Navi 31为图形处理器世界带来了真正革命性的小芯片GPU设计,如果这一设计取得成功,那么未来GPU就可以不用依赖先进工艺来提升性能,而是通过堆叠更多的GCD来实现。GPU市场或将迎来新的战争。
写在最后
3D IC设计逐渐成为了主流,Chiples也进一步崛起,在芯片大厂的推动下,基于Chiplet的3D IC设计进一步展示了其说服力。Chiplet将彻底改变这个行业。英伟达何时采用Chiplet,备受业界关注,不过估计也快了,毕竟黄仁勋已指出:“摩尔定律已死(Moore's Law is dead)。”
本文来自微信公众号:半导体行业观察 (ID:icbank),作者:杜芹DQ