
本文来自微信公众号:追光几何(ID:EverCraft),作者:少侠、周五、余鱼,头图来自:unsplash
Git诞生于开源领域linux的全球开发者协作需求,又推动了整个软件领域工作流的变化,本质上诞生了一种更高效的生产模式。对于机械设计领域也该如此,底层工作流的变革往往带来世代级的效率提升,数字化工具则作为先进工作流的支撑者和承载体出现。
一、关于工作流
1. 什么是工作流
工作流(workflow),简单点就是工作的流程,复杂点则有很多层面的定义:
工作流是对工作流程及其各操作步骤之间业务规则的抽象、概括描述;
工作流是指一类能够完全自动执行的经营过程,根据一系列过程规则,将文档、信息或任务在不同的执行者之间进行传递与执行。
比如这就是一个简单的工作流:去买2个鸡蛋,如果有西红柿,则买2个鸡蛋和1个西红柿,否则只买2个鸡蛋。那什么不是工作流?比如:买2个鸡蛋、1个西红柿。这是工作清单。
2. 为什么工作流很重要
因为影响效率,尤其对于团队协作。
协作必须有一个规范的工作流程,使得项目井井有条地发展下去。好的团队协作“工作流”应该像水流一样顺畅自然地向前流动,在不断汇集各支流的过程中不发生冲击对撞,持续保持主干方向的正确,最终奔向大海。
理想中的行云流水往往只在完全自动化的工作流中发生,但只要有“人”的参与,现实则会相当骨感。因为只要“流”动必然就有信息的传递,而人之间的信息传递容易带来“冲击对撞”。
以下就是一个典型的“冲击对撞”:
【预设的工作流】妻子要做午饭,叮嘱丈夫:“去买2个鸡蛋,如果有西红柿,则买1个。”
【团队执行】丈夫出门了,回来时买了1个鸡蛋。
【无实际产出的冲击对撞】妻子:“怎么只有1个鸡蛋”
【无实际产出的冲击对撞】丈夫:“你说有西红柿则买1个,所以我买了1个鸡蛋。”
【无实际产出的冲击对撞】妻子:“...我的意思是去买2个鸡蛋,如果有西红柿,则在买2个鸡蛋的基础上再买1个西红柿”
【无实际产出的冲击对撞】丈夫:“...”
影响效率的一面是丈夫需要再去买一次,更糟的是事儿没办成说不定还得吵一架。
二、是什么在影响设计工作流的效率?
参与人越多,工作流的提效越难。知识产出是重要提效环节,比如程序员、机械设计师。各行业工作流具有对应的信息流载体(同时也代表产出):代码、图纸。工作流最终需要促进产出的形成,所以提效基本围绕人与载体的关系开展:人与代码、人与图纸。
工作流的效率问题大多体现在人与这些信息流载体之间的关系不好,社会分工则进一步加剧效率冲突:信息太多了怎么找、理解错了要重做、看不懂需要找人沟通、做决策如何拿到最新的信息...
1. 举个例子
此部分参考如下链接中的案例进行整理:https://zhuanlan.zhihu.com/p/72946397
吴同学写毕业论文,埋头苦干两月余,文档如下:
毕业论文-大纲.doc
毕业论文-20120501.doc
毕业论文-20120502.doc
……
毕业论文-完成版.doc
毕业论文-完成版修改1.doc
……
毕业论文-绝对不改版.doc
毕业论文-绝对不改版修改1.doc
……
上述是一个线性工作流,每个新文件都是在上一个版本基础上修改而来。虽然文件版本多,但吴同学基本还能hold住:做好文件命名+还算不错的记忆力。

现在开始增加难度。
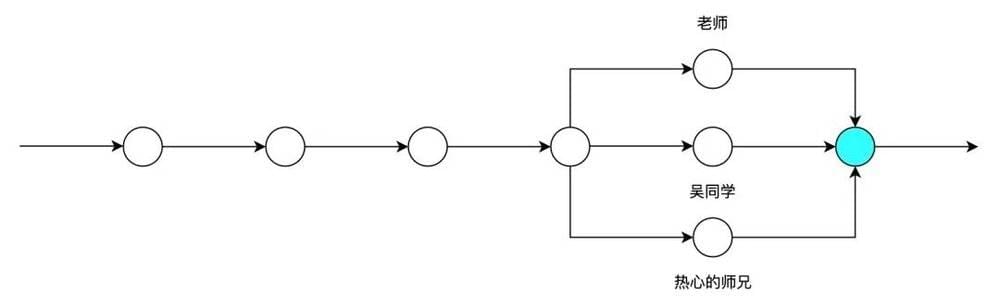
论文需要经常给导师审阅,导师也会帮着一块改,这期间吴同学也不能闲着。所以单一线性工作流就产生分叉了:导师改出了一版本,吴同学也会产生一个版本。两个版本的汇总是吴同学需要解决的问题:
1. 为了不把文档弄乱,建个新文档用来汇总用;
2. 对比老师改的内容、自己改的内容:
a. 两处位置不一样,直接粘贴汇总;
b. 存在部分重叠,决策用哪个部分,或者综合修改;
3. 改完之后整体顺一遍。
此时工作流复杂了很多,吴同学用在文件汇总处理上的时间明显增多了。
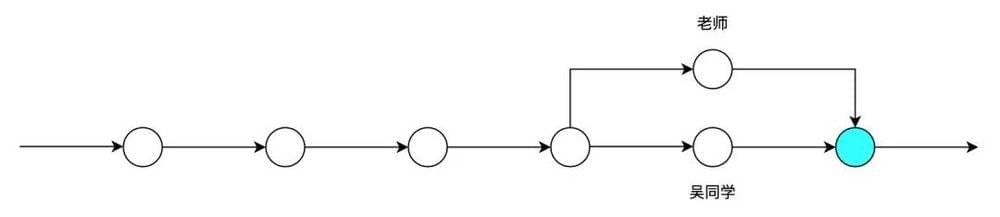
如果再加入一位热心的师兄。
随着多人的加入,吴同学不知不觉需要把更多精力放在与老师和师兄的沟通上面,检查改了啥、小心处理修改、往返发送确认……这些琐碎时间的投入开始偏离了论文产出本身。
2. 同样的问题在机械设计中的体现
下面我们看看机械设计,以一款常见的工业机器臂为例。
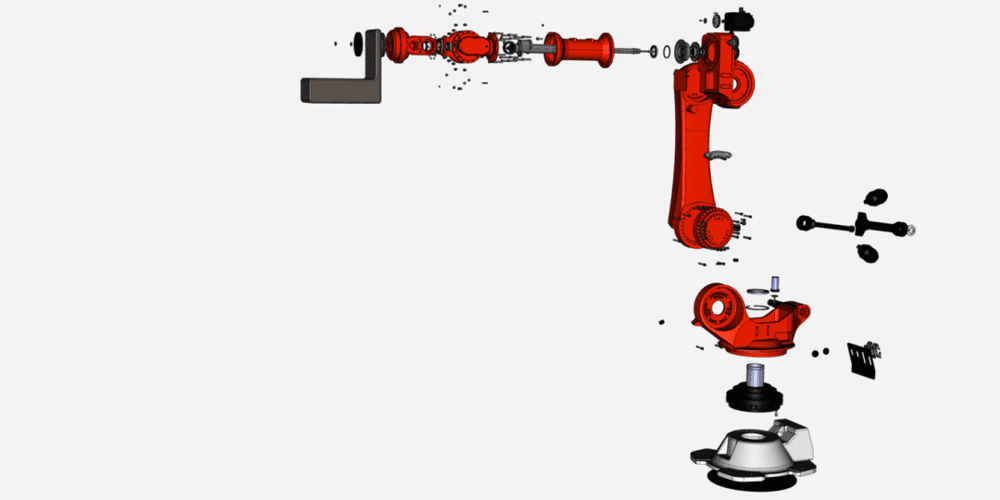
相对于毕业论文,机械设计的复杂度提升体现在如下几个方面:文件更多、协作更多、改的更多。
1)文件更多
机械臂的零部件数量在1000+量级(其中非标设计件100+),完整的产品文件包包括与此相关的设计图纸、仿真文件、设计说明书、加工工艺、物料清单等,且这些文件之间有紧密的关联关系,必须保证是正确的一一对应。
最终一个定稿的项目文件包大概占据500M量级存储空间,约800个文件。
2)协作更多
设计分工是常态,分工逻辑比如:工业设计、结构设计、电气设计、加工工艺等。相互之间的合作关系既存在同一环节的并行修改,又存在跨环节之间的交叉修改,甚至这些合作者可能不在同一家公司。
3)改的更多
机械设计是一个不确定的状态,需要不断设计尝试和验证才能最终定稿,并且通常需要更长的周期进行项目迭代。这点尤其体现在新产品设计过程中。

这种设计迭代通常是在多人协作的基础上开展。以机械臂中电气工程师和机械工程师的配合为例,传统的工作模式下,电气工程师设计电气原理图,并绘制接线图,机械工程师按照要求进行结构设计,理想的设计流程如下图所示:
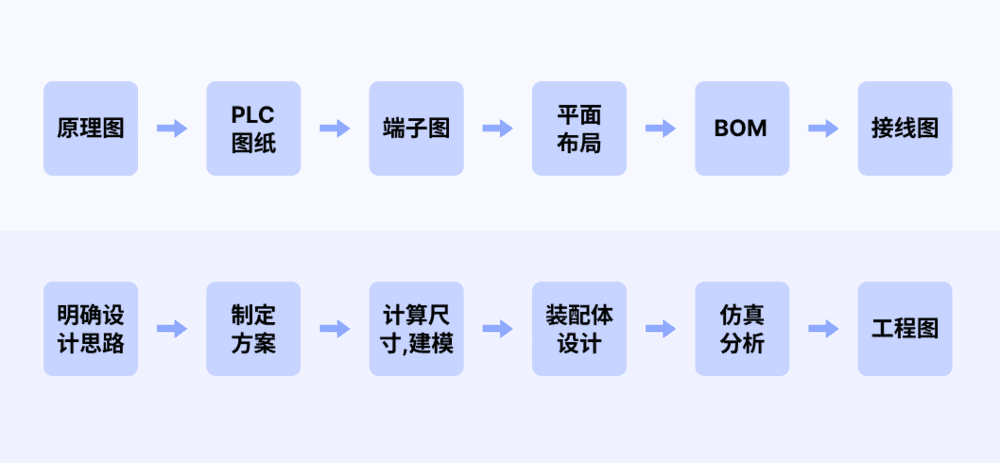
但通常结果是:
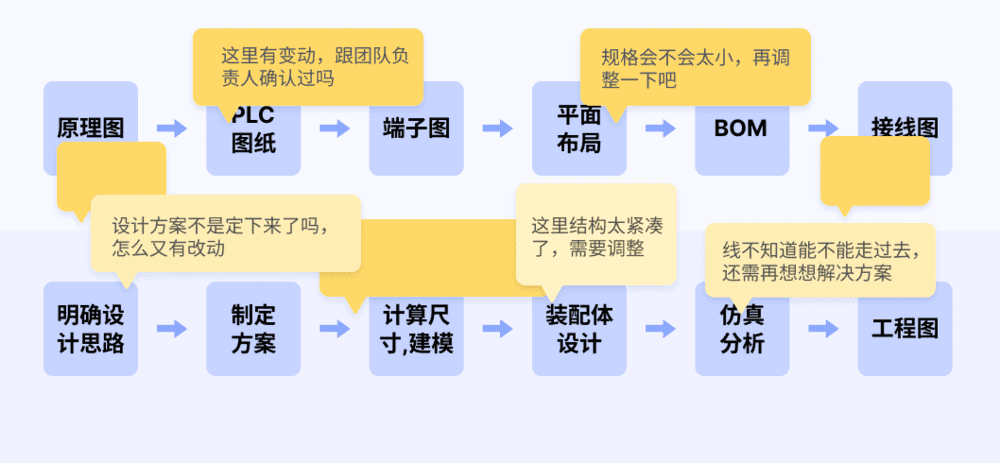
如果定稿全套文件是500M,上述各类修改过程中产生的过程文件则在10G。
三、怎么办?看看软件领域怎么做
这些体现在设计工作流中的“冲突”问题,使工程师花费了大量的时间处理与信息流载体(也就是文件)之间的关系,而无法专注于设计产出本身,更甚者还会造成文件的用错。
文件多不可怕,可怕的是反复改。以前述毕业论文为例,最终定稿的也就是1个文件,但是当多人+多版本出现的时候,问题就变得困难了。通过重命名、复制粘贴、备份文件夹等方式,我们其实潜在地维护了一个最简单的文件版本控制系统。但是当遇到机械设计领域这种文件不仅多还都需要多人反复改的情况下,这个简单的文件版本控制系统显然难堪大任。
怎么办?我们先看看别的领域怎么做。
1. 都有哪些领域可以参考
最容易想到的就是软件领域。通过数字化转型提高效率已经成为全行业共识,如果软件领域自己这方面都没做好,那我们也就没什么期待了。
很幸运的是软件领域已经存在先进的实践:
通过开源的方式,全球互不认识的成千上万人可以共同参与造就一款又一款改变世界的产品。最知名的比如linux,1969年至今全球已经有数万人参与了这款开源操作系统的开发,自2005年可以统计以来,有来自1400个不同公司的15,600人参与。
但我们的关键词并不是开源,而是开源协作模式背后的高效工作流解决方案。
更幸运的是软件领域的工作模式跟机械设计有诸多共通之处:
文件多且互相关联紧密;
协作多且跨职能分工;
改的多且开发经常迭代。
2. 那么程序员是怎么做的
程序员显然不满足于最原始的文件版本控制方式,所以这种变化早在20世纪70年代就开始了。总体而言程序员的版本控制系统经历了如下几个关键里程碑:

在上述三个里程碑阶段中我们可以清晰地看到版本控制工具发挥的影响:
它替工程师做了越来越多重复性的文件管理工作,从单文件到整个项目的所有文件,从单人到多人;
它支撑了协作工作流的变化,从单人线性到多人线性,再到多人并行但集中管控,最后演变到多人分布式协作。
3. 我们重点说一下Git
前文提到开源协作模式背后的高效工作流解决方案,Git是其中最广泛的(没有之一),它的诞生是为了管理Linux这种超大规模项目。
在 2002 年之前,Linux 的世界各地开发者通过邮件发送源代码变更差异给 Linus Torvalds(Linux 之父,同时也是 Git 之父),然后再由他以手工的方式合并代码。随着 Linux 项目规模逐渐增加,绝大多数的 Linux 内核维护工作都花在了提交补丁和保存归档的繁琐事务上。到了 2002 年,整个项目组开始使用一个商业的版本控制系统 BitKeeper。不久之后,这家公司跟 Linux 社区产生了一些纠纷。于是Linus Torvalds 花了一个星期的时间,从头开始编写了一个分布式版本控制系统:Git,以望帮助更多的开发者有效、高速地处理从很小到非常庞大的项目版本管理。
由于Git功能的灵活性和速度,再加上GitHub、Gitlab等添加的协作性、社交性,使得Git风靡于世。目前,Git已经成为全球最主流的版本控制系统,大量的初创企业、集团企业和跨国公司(包括谷歌和微软)使用 Git 来维护它们软件项目的源代码。
4. 以Git为例,我们看看软件领域版本控制系统的特点
1)以项目整体为单元维护所有文件的变化
如前文所述,一个毕业论文的修改还在吴同学的掌控范围之内,但是当这种修改上升到成百上千个文件且这些文件之间还需准确维护对应关系时,人力就难以企及。版本控制系统将所有文件的变化都记录下来了,且在此基础上维护的是他们作为一个项目整体的变化。我们可以举一个例子来看下这种思维方式的转变。
假设这个项目只有两个文件A和B,他们之间有准确的关联关系,每个文件分别改了两次,最原始的呈现如下(这也是我们电脑文件夹里最常见的呈现方式):

此时我们往往开始疑惑:这里四种组合A1+B1、A1+B2、A2+B1、A2+B2,哪种才是我想要的?除非我们有事前的约定(比如都只要最新的),不然为了更好的管理文件之间的组合关系,我们可能会把文件结构调整如下:

恍然大悟:原来根本没有A2+B2这种组合呀!但又带来新的困惑,这三种组合之间有啥内在关系?
但如果将项目作为一个整体来维护所有文件的变化,这个项目的变化历史关系则会如下图。
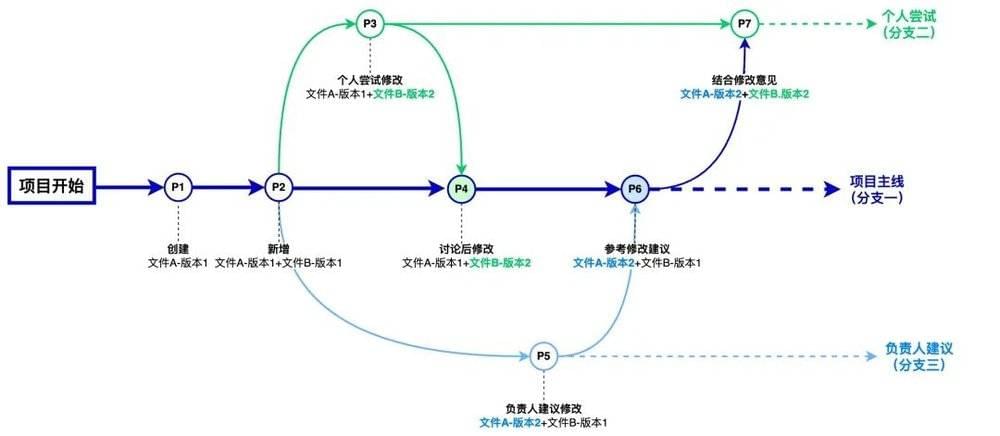
每一个节点P1~P7代表的是这个项目整体当时的状态。就像时间机器一样,吴同学可以在各个节点之间游走。吴同学不需要通过文件名来区分文件A和文件B发生的变化以及是哪个版本,因为整个项目的历史变化关系已经由版本控制系统记录并维护。此时通过上图我们可以清晰的看到:
项目主线(分支一):
P6:这是项目正在使用的项目文件组合,文件A用的是版本2,文件B用的是版本1,并且结合了负责人的建议修改的版本。
P2、P4:都是项目在P6之前的历史状态,P2是初始的,P4是按吴同学意见改的;
个人尝试(分支二):
P3:吴同学自己做的尝试修改,项目主线P4有用到;
P7:结合负责人的建议,吴同学试着看看有没更好的解决方案,不过这个方案还处于吴同学自己尝试的状态,没有用到项目中;
负责人建议(分支三):
P5:是在P2基础上负责人按自己想法做的修改,此时项目节点P6用到了P5的内容。
上述复杂的P1到P7项目变迁历史带来的文件组合关系都由版本控制系统代劳,吴同学完全不必费心。他只需要专注写代码,在任何节点他的文件夹只有简约的两个文件:

2)通过“分支”来管理并行,Git具有独特的优势
几乎所有的版本控制系统都以某种形式支持分支,使用分支意味着我们可以暂时把工作从主线上分离出来,避免影响主线或者其他人的工作。
分支的作用在吴同学和负责人的例子里已经很形象了:
从项目主线文件不被干扰的角度,在项目主线(分支一)之外可以有自己尝试用(分支二)和负责人建议修改用(分支三);
从多人分工角度,吴同学在自己尝试用(分支二)上工作也不会影响负责人的修改。
在对待文件版本数据的跟踪方式上,其他的版本控制系统大多使用“文件变更列表”来存储版本信息,这类系统将它们存储的数据看作一个基础文件版本和随时间逐渐累加的差异,我们可以称之为“基于差异的版本控制”。而Git 直接记录快照,而不是差异。每当我们保存最新的项目状态时,Git 会检查当前最新的所有文件,并生成当前项目状态的一个完整快照,同时基于存储效率的考虑,如果一个文件没有变更,那么会复用之前存储过的这个文件,在快照中生成一个链接指向它。相比于“基于差异的版本控制”,Git 对待数据更像是一个“快照流”。
由于记录差异而不是快照,在传统的版本控制系统创建分支是一个有些复杂的过程,通常需要把整个项目创建一个副本。而 Git 创建分支是一个令人难以置信的轻量操作,创建分支只需要将分支指向一个历史版本快照,而这一操作基本上可以瞬间完成,并且在不同的分支之间切换也十分便捷。不论是切换分支还是合并分支,传统的版本控制系统都需要计算大量的文件差异,而 Git 只需要根据快照切换文件就可以完成操作。
正因为传统版本控制系统的分支操作如此低效,所以大多数用户都遵循“从服务器获取最新文件 —> 修改文件 —> 推送回服务器”这种线性工作流。而使用 Git 进行分支管理是如此的便捷,所以 Git 鼓励在工作中频繁切换、合并分支,从而带来了一些全新的工作流模式。
3)先允许修改,再处理冲突
所有的工程问题都十分严谨,所以最基本的要求是不能因为多人协作而弄乱代码,在此基础上才是如何提高效率的问题。
还是上述的例子,很长一段时间为了保证用到项目上的文件不乱,极端的做法是当吴同学改文件时负责人就不要改了,或者负责人改时吴同学你就别动了。然后工作流就变成如下图,这种串行方式的工作效率可想而知。

并行当然效率更高,所以“先允许修改,再处理冲突”是更好的工作流。但是,这时候的效率卡点在于“再处理冲突”这个环节,也就是多人工作结果交叉影响下如何同步和汇总,处理的不好就不仅是效率问题了,甚至会造成项目代码弄错。通过人工来维护的话,在如下图所述的关键卡点往往发生如下情况:
1. 吴同学要花很长时间仔细挑选哪些改了、哪些没改,然后好好的汇总;
2. 负责人改了啥没来及跟吴同学说,而这个还挺影响吴同学正在改的文件,吴同学埋头苦干挺长时间后才知晓,得,白干了;
3. 更惨的情况是,负责人改了啥就忘了说,直到项目最后要测试了,才通过测试同学发现bug,然后一直找问题点……
对于软件来说,代码远不是两个文件,也远不会只有吴同学和负责人两个人干活,所以上述看起来低级的问题在真实情况下却再正常不过了。
上述卡点也由版本控制系统代劳了,吴同学依然只需要专注于写代码。当他把自己的工作成果合并到项目主线时,版本控制系统会帮他把关项目的文件哪些已经改了且存在冲突,此时他将在版本控制系统的要求和辅助下处理这些冲突。
5. 回到工作流提效
我们很容易想到从如下两个维度来实现工作流提效:
尽量用工具自动化解决该工作流中的冲突;
设计一个冲突更少的工作流。
在前文我们已经体会到:Git这类版本控制系统不仅是帮程序员自动记录工作流历史、辅助解决冲突,而是更进一步支撑了程序员底层工作流的演进。尤其是Git分支操作的便捷,衍生出多个全新的工作流模式,比如Git flow、GitHub flow、GitLab flow。下面我们看两个分支工作流模式。
1)长期分支模式
“长期分支模式”,即在一段较长的时间内,同时拥有多个开放的分支,并且在项目的不同阶段,可以定期的把某些分支合并入其他分支。
我们以很多开发者最常用的分支使用方式来举一个例子。在整个项目中维护了三个较长期的分支:master、develop 和 topic:
在 master 分支上只保留完全稳定的代码;
develop 分支用来做后续开发或者稳定性测试之类的工作,当 develop 分支达到稳定状态(比如完成了测试)就会合并回 master 分支。
topic 分支是开发者工作的分支,当开发者觉得自己的分支开发完成,可以进行测试了,就会把 topic 分支合并到 develop 分支。
如果我们将这三个分支想象成不同阶段的流水线,某时刻如下:
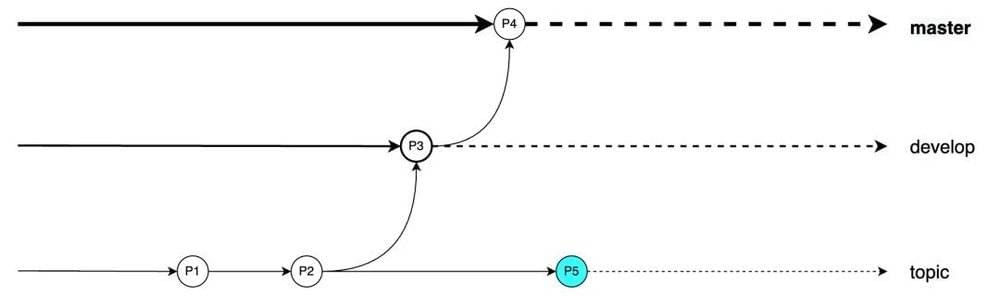
假设此时topic开发者吴同学已经完成了新的开发迭代(P5)并提交给测试(develop),则会变成如下图所示状态。测试则会对包含新开发迭代内容的P6进行测试。
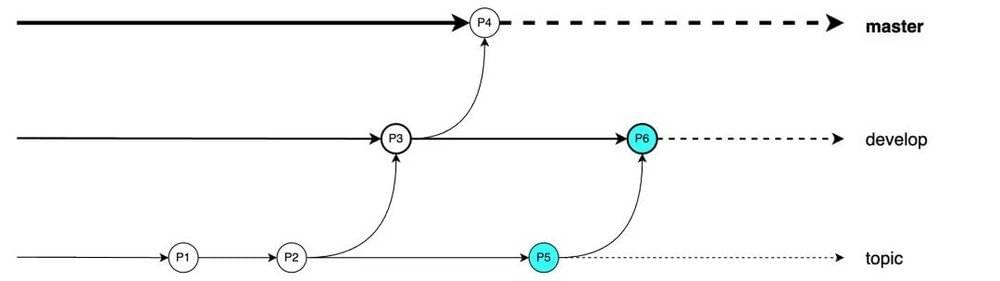
若测试通过,则才会进一步发布到稳定分支master,真正用于面向用户的正式产品中(P7)。此时状态如下:
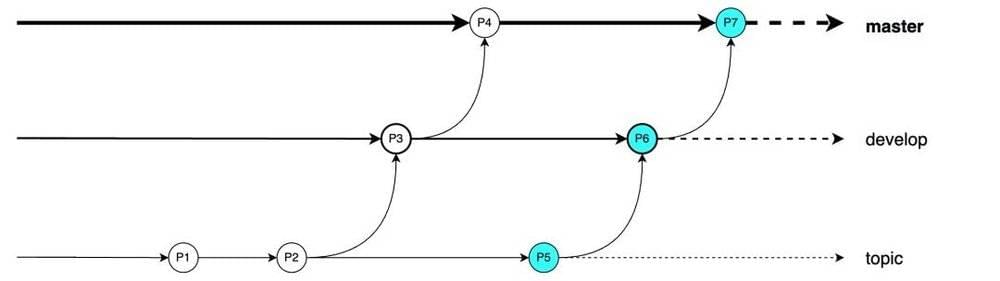
这个过程中吴同学也能在topic上并行开展进一步的工作(P8)。
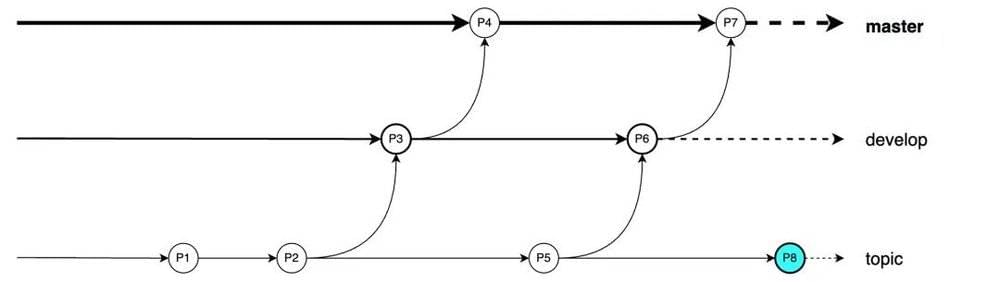
2)主题分支模式
主题分支是一种短期分支,通常被用做实现单一功能相关的工作,并在验证后快速合并回主干分支。这种方式可以让我们快速并且完整的进行上下文切换,例如吴同学可能在同时做两个独立任务模块,并且在完成设计开发之前都不想对主干上稳定的功能产生影响,那就可以创建两个主题分支分别来处理这两个工作。
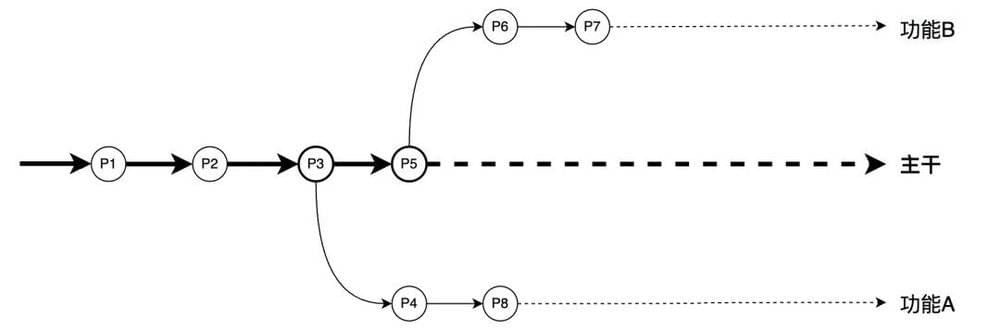
考虑上图这个例子:
1. 当吴同学在主干上工作到 P3 的时候。突然接到了要做“功能 A”的需求;
2. 此时吴同学创建了一个新的分支“功能 A”,并且做了一些开发工作,创建了 P4 这个版本;
3. 但此时可能没有什么头绪了,想转换一下思维回去开发主干功能。当主干功能开发到 P5 的时候,又接到了需求要做“功能 B”;
4. 此时从 P5 上创建了一个新的分支“功能 B”,并在接下来的一段时间专注于这一部分工作。当“功能 B”做了一段时间,版本迭代到 P7 的时候,突然吴同学灵光一闪!想到了如何解决之前在“功能 A”上遇到的问题;
5. 那么就可以立刻切换回“功能 A”分支,完成这部分工作,创建 P8 版本。
在这个过程中,吴同学可以在“功能 A”、“功能 B”、“主干”这三个分支间快速切换,专注于完成对应分支的工作,简直就像是平行时空!
在“功能 B”开发完成之后,吴同学持续开发完“功能 A”,突然想到有一种更好的实现方式,这时候吴同学基于 P8 创建了“功能 A 第二种方案”分支,在这个分支上完成了第二种方案的开发,如下图所示:
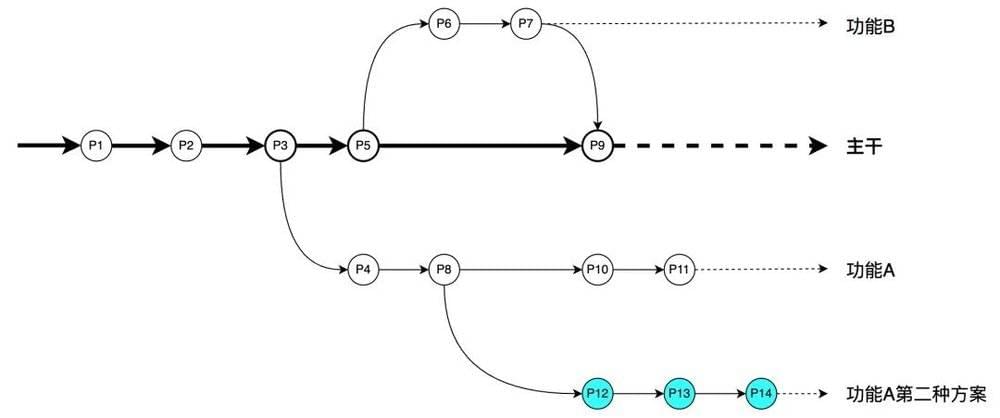
等到了评审阶段,大家可以同时对比“功能 A”的两种实现方式,最终达成共识第二种方案确实更优。那么“功能 A 第二种方案”就合并回了主干分支。
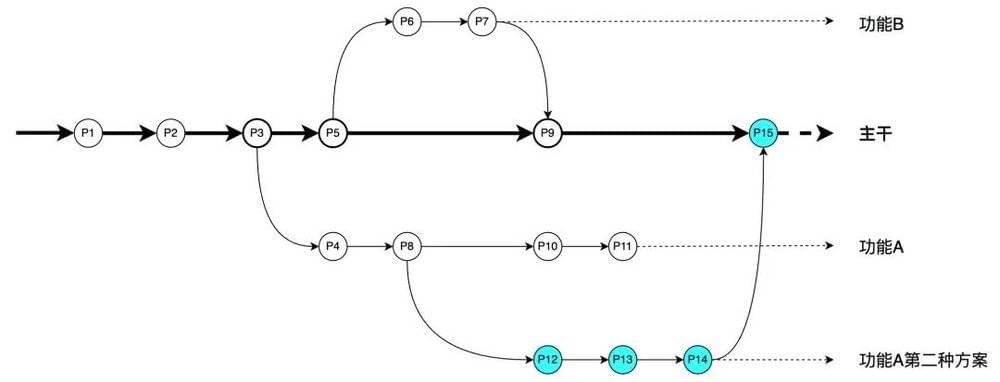
在这种工作方式中,因为每个主题分支都只和当时在做的工作相关,所以在进行评审的时候可以排除掉其他并行工作的干扰,更容易看出做了哪些改动。在进行新的开发的时候,也不用担心做的改动不小心影响到其他部分。而且这种非线性的分支管理方式可以让吴同学把做出的改动保留在对应的主题分支几分钟、几天甚至几个月,直到它们完成之后再合并回主干分支,而不用在乎这些主题分支建立的顺序或者工作进度,以及潜在的对其他功能的影响。
四、那么机械设计呢?
Git诞生于工作流提效的需求,又推动了工作流的变革。具体来说,Git诞生于开源领域linux的全球开发者协作需求,又推动了整个软件领域工作流的变化。本质上诞生了一种更高效的生产模式。
对于机械设计领域也该如此,底层工作流的变革往往带来世代级的效率提升,数字化工具则作为先进工作流的支撑者和承载体出现。模式也许不可以复制,但最佳实践的理念可以传播和借鉴。或许我们可以吸取Git实践的精髓,因地制宜找到机械设计领域工作流优化的落地实践?
说干就干,我们来尝试构建一个机械设计专属的版本控制系统,暂且叫它MGit(Mechanical Git)吧。
1. 构建原子功能
前文已经提到Git底层的三个基础功能点:
1. 以项目整体为单元维护所有文件的变化;
2. 通过“分支”来管理并行;
3. 先允许修改,再处理冲突。
MGit需要先把这三个底层逻辑构建起来,我们称其为原子功能吧。
1)以项目整体为单元维护所有文件的变化
在Git,每一次commit都会创建一个项目所有文件的“快照”,“快照”就是管理项目整体的单元,如下图中的P1~P3。为了作区分,我们就用“存档”来代替。

为什么叫“存档”呢,大家都玩过游戏,就拿仙剑奇侠传来说吧,关键boss之前我们都会存档,这些游戏存档有这么两个特点:
存档包含了当时游戏里所有对象的状态,李逍遥的血量、级别、装备、包裹里的药材、故事进展;
通过存档可以回到游戏曾经的某个时间点,恢复到当时存档的所有状态。
如果把某个项目的机械设计任务也理解为闯关打游戏的话,P1~P3其实就是这个游戏中的3个存档。对于机械设计而言,所有对象的状态其实也就是所有文件的状态,所以P1~P3各个存档存下来的内容如下:
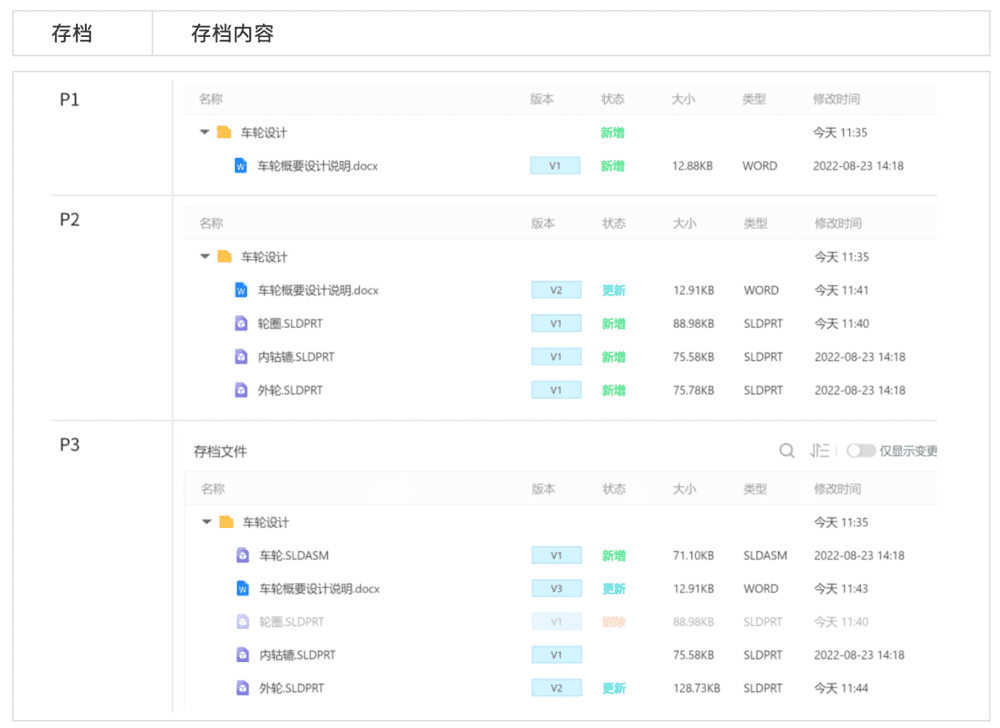
假设李逍遥变身机械工程师,我们对比下P1~P3三个存档李少侠和李工心态的对比。
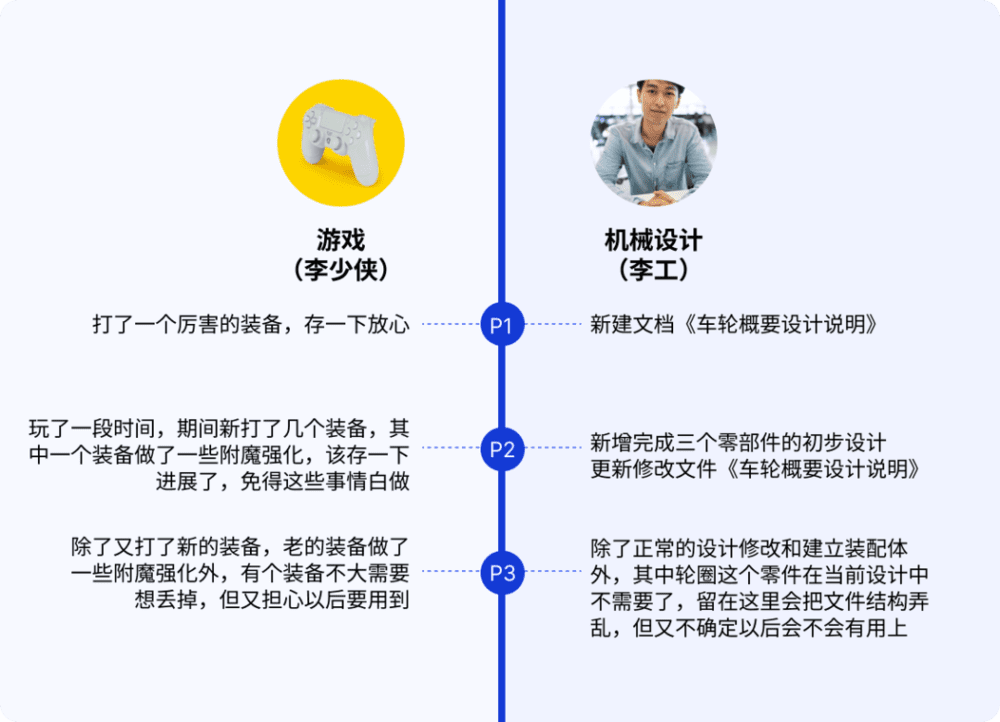
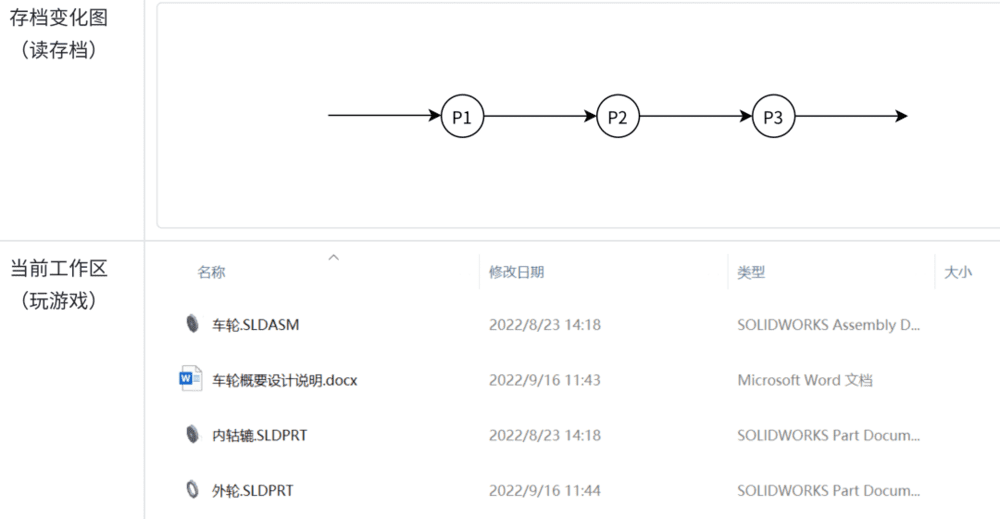
我们通过“存档”以项目整体为单元维护所有文件的变化。看起来似乎复杂了不少,但对于工程师而言思维其实简单了很多,相对于以前需要人工维护每个文件的变化和命名,此时工程师只需要关注项目发生了什么,该存档时则存档即可,其他所有文件的变化维护都由MGit代劳了。
工程师只需关注两个:存档的变化图(读存档),当前工作区进行设计(玩游戏)。
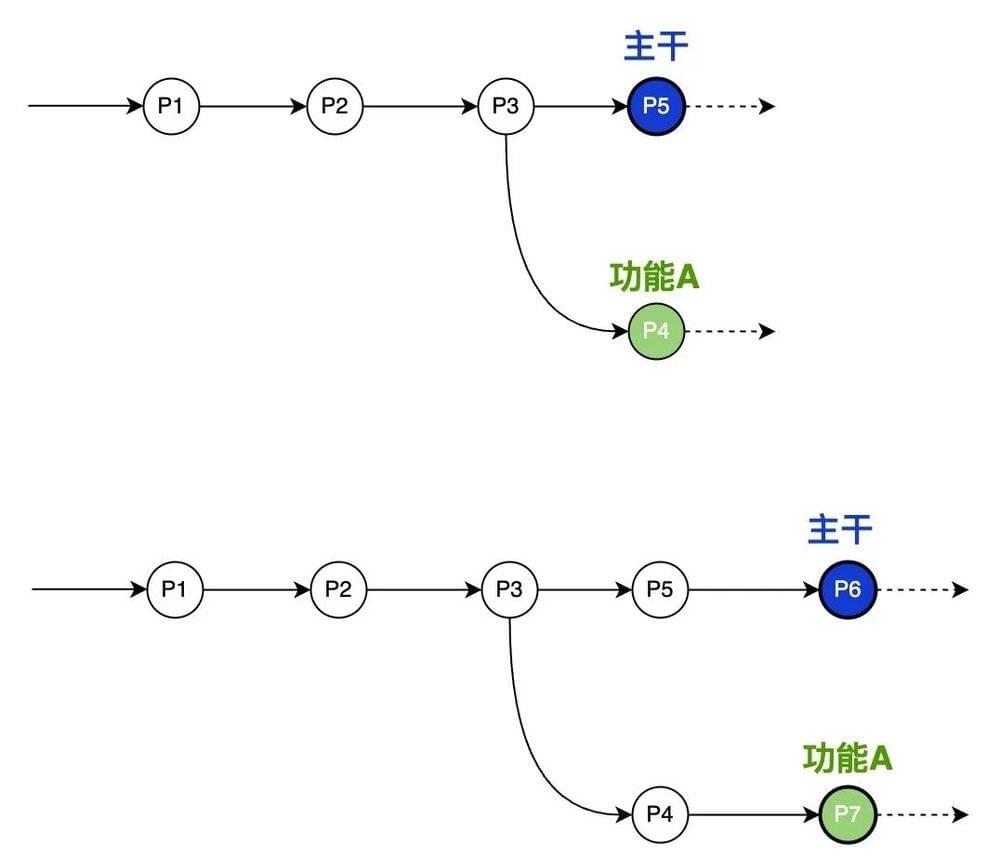
2)通过“分支”来管理并行
分支实现的底层理念跟Git类似,但为了可以更好的做可视化的呈现,在分支的交互层咱们需要发生一些改变。
在Git里,分支只是某个commit的特殊标识,并随着commit前进,如下图:
在MGit里,我们或许可以让“分支”更形象一些,把这条支线上的所有存档串起来,这里“分支”包含的内容就更多了,如下图:
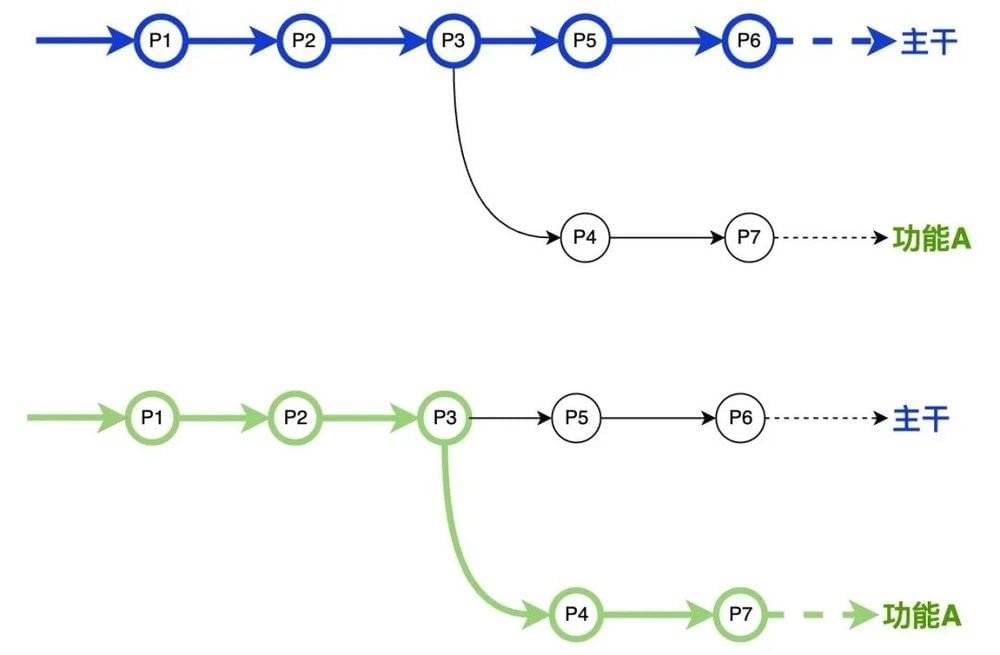
分支的作用就不再赘述了,前文Git里吴同学和负责人之间的案例已作体现。
3)先允许修改,再处理冲突
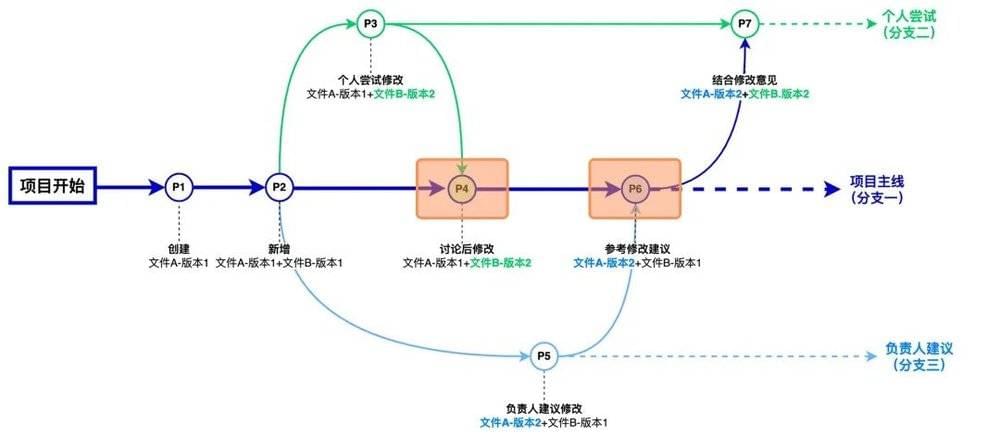
如前文所述,“先允许修改,再处理冲突”的效率卡点在于“再处理冲突”这个环节,也就是多人工作结果交叉影响下如何同步和汇总。这种冲突的处理时机发生在合并分支时,如下图所示的P4和P6。
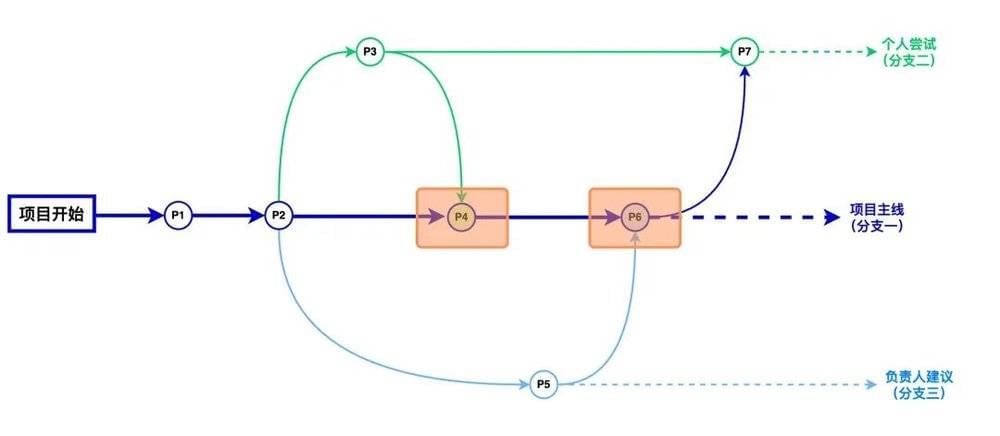
我们以P4为例,吴同学在将自己分支的成果合并到项目主线并创建存档P4时,需要处理我们常见问题:
P3是基于P2修改的,相对于P2,P3里哪些文件改了、哪些文件没改、删了哪些文件、新增了哪些文件……最终整合到P4时如何汇总P2和P3的结果?
为了让吴同学更专注于做设计,这些重复性劳动当然需要MGit来辅助处理。MGit已经自动记下了P2和P3之间的区别:
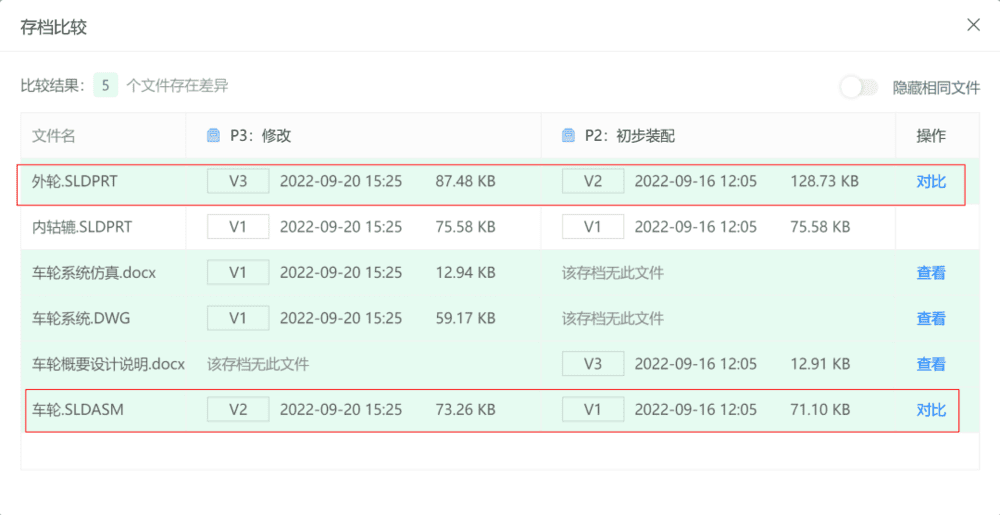
甚至如果需要,吴同学还可以通过MGit进一步查看具体某一个文件前后设计的变化,比如“外轮.SLDPRT”:
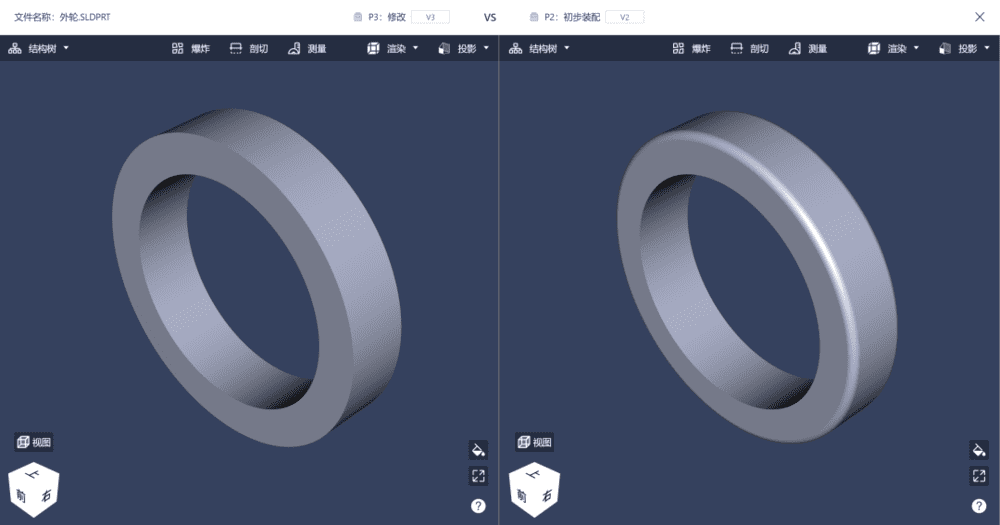
我们能看到其实需要吴同学介入处理的冲突仅在于"外轮.SLDPRT"和“车轮.SLDASM”这两个文件,所以在合并时,在MGit的帮助下,吴同学全过程只需要做的操作就是在如下界面对冲突的两个文件进行选择处理:
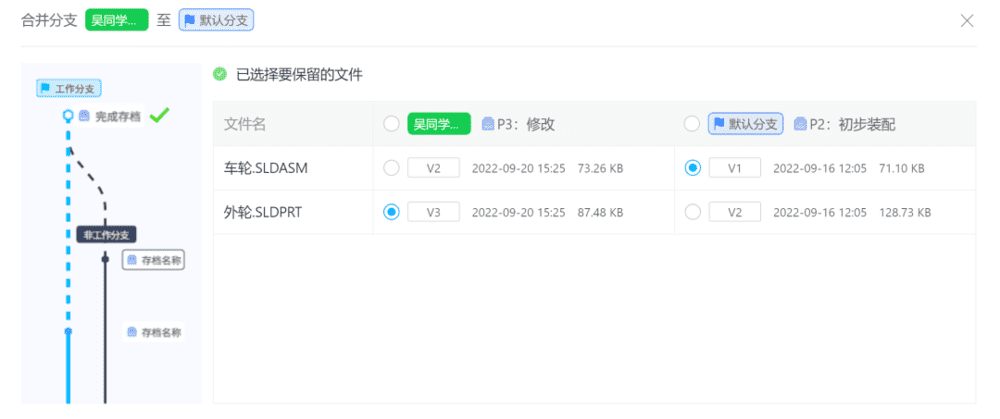
至于“相对于P2,P3里哪些文件改了、哪些文件没改、删了哪些文件、新增了哪些文件...”这些头疼的问题MGit代劳处理了,完全不必吴同学费心。
2. 让多人协同起来
完成了三个底层原子功能的构建后,我们已经解决了串行往并行工作的转变。但为了真正让多人协同起来还需要一个很重要的因素,那就是不同并行工作之间信息同步的时效性管理。
由于机械工程师之间的工作耦合性往往很强,信息的不同步往往带来相互设计影响的更改滞后。举个例子:
机器人的小臂结构中,电气工程师设计了中空走线方案。结构设计师为了保证穿线导管的强度,需要添加轴承支撑,而轴承的引入则会限制了导线管的直径,小于所需穿过的线的直径。这个时候电气工程师需要调整设计方案,从而保障项目能正常推进。如果机械工程师对穿线管的设计变更不能及时反馈到电气工程师这里,就会导致后续设计出现错误。
对机械这种传统自顶向下的设计过程,这样的滞后有可能会导致整体设计的失败。
所以我们看看如何在三个底层原子功能的基础上构建高效的多人协同信息同步机制,还是以吴同学和负责人为例吧。
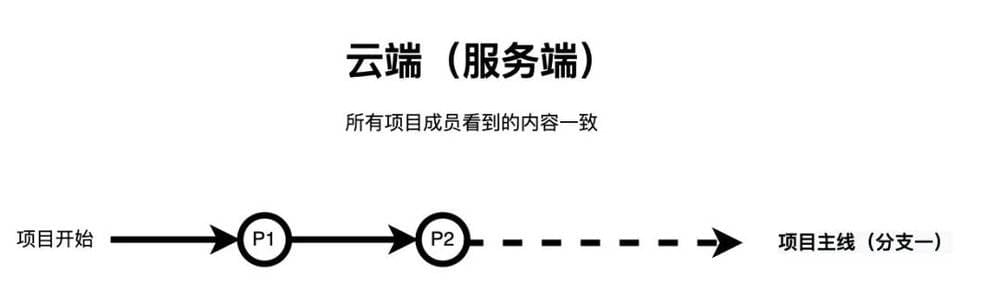
假设此时云端(服务器端)的项目进展如下,所有项目成员在云端看到的内容一致。
为了让吴同学和负责人可以并行开展项目的进一步设计,我们需要允许他们在自己电脑拷贝项目相关所有文件的副本(在这里我们叫【克隆】),并可以各自独立地修改,修改过程中不需要跟远程服务器一直联网。此时相互之间的关系如下:
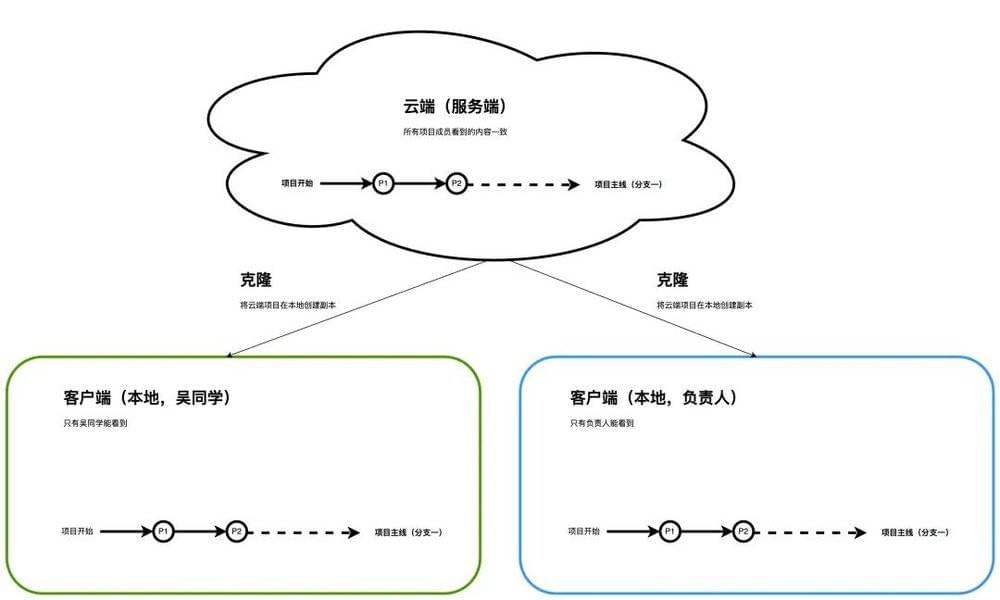
接下来假设吴同学和负责人都从P2开始延续设计,两人为了不影响项目主线,均会创建自己的尝试分支,所以此时各端项目的进展如下。因为都还处于自己的尝试设计阶段,此时三端的内容已经不一样了。
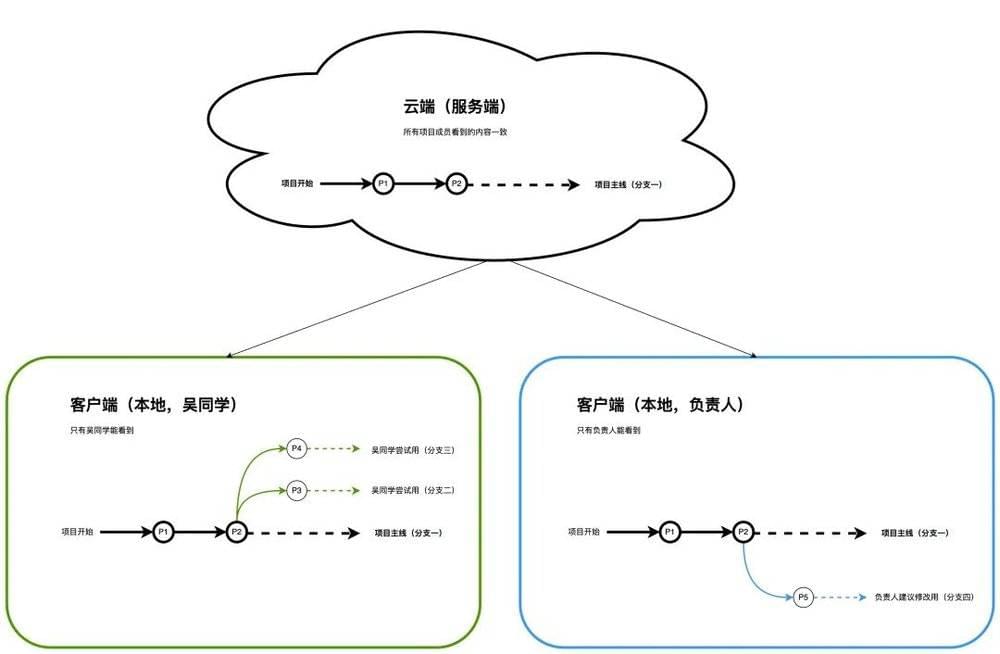
因为吴同学时间充裕,所以他更快的完成了自己的设计,跟小组讨论确实没啥问题之后,将其中更优的结果合并到项目主线分支里,如下图。但是此时其实信息还没有同步到云端,所有的变化都还只体现在吴同学自己的本地客户端里。
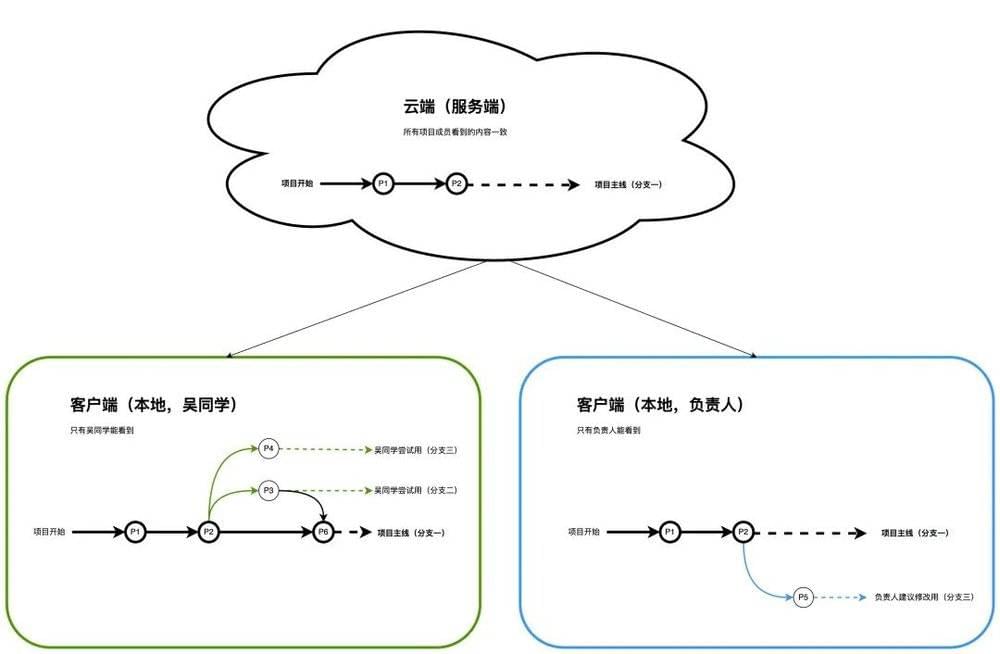
在同步到云端之前,我们可以认为吴同学在本地做的所有工作都是他自己的设计尝试过程,不一定对其他人员有意义,也不需要给其他同事带来不必要的信息干扰。
为了让吴同学的工作可以和大家同步,MGit需要提供一个同步功能,我们叫【推送】。吴同学要做的事情只是选择想要同步的分支,并点击【推送】即可,其余由MGit来处理。对大家有实际意义的是项目主线(分支一)的变化,所以吴同学此时将项目主线(分支一)推送到云端。如下图:
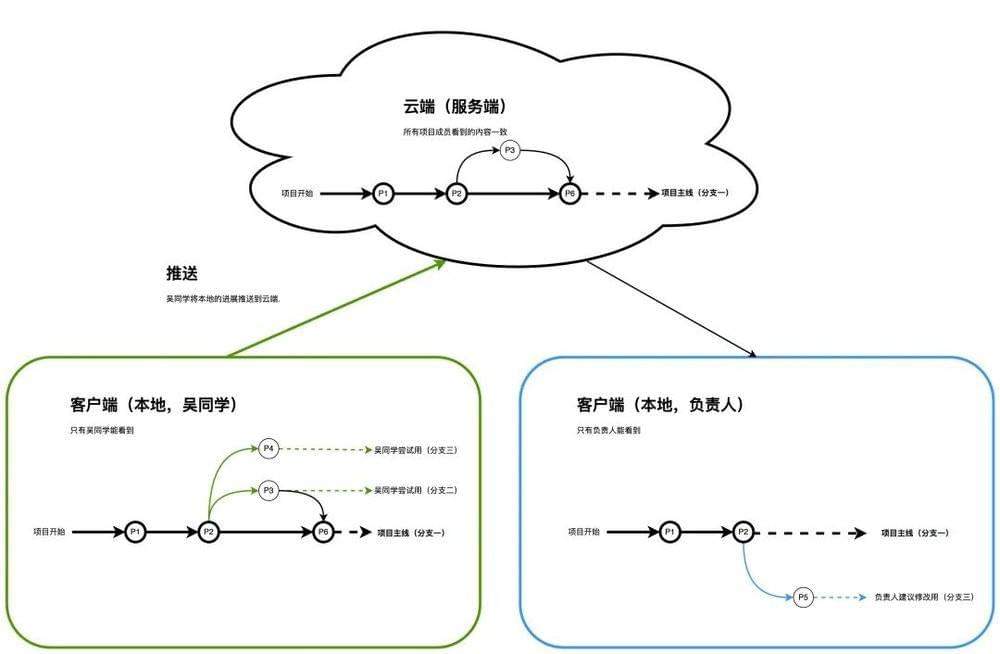
项目主线完成云端的同步后,才宣告对于项目进展正式前进到P6。
我们该看看负责人的进展了。负责人时间比较少,还在自己的分支三上干活,我们关注到分支三的起点还停留在P2。如果负责人没有及时了解到最近的进展P6,很可能很多活白干了。
因为云端是所有人一致的工作台,所以负责人及时看云端即可发现项目主线的变化;
MGit也会自动及时通知负责人其工作依赖的分支一已经发生变化了。
如何将项目主线的进展同步到负责人的本地客户端呢?我们把这个功能叫【拉取】吧。负责人只需要做的操作就是,选择项目主线(分支一),然后点击【拉取】即可,其余由MGit来处理:
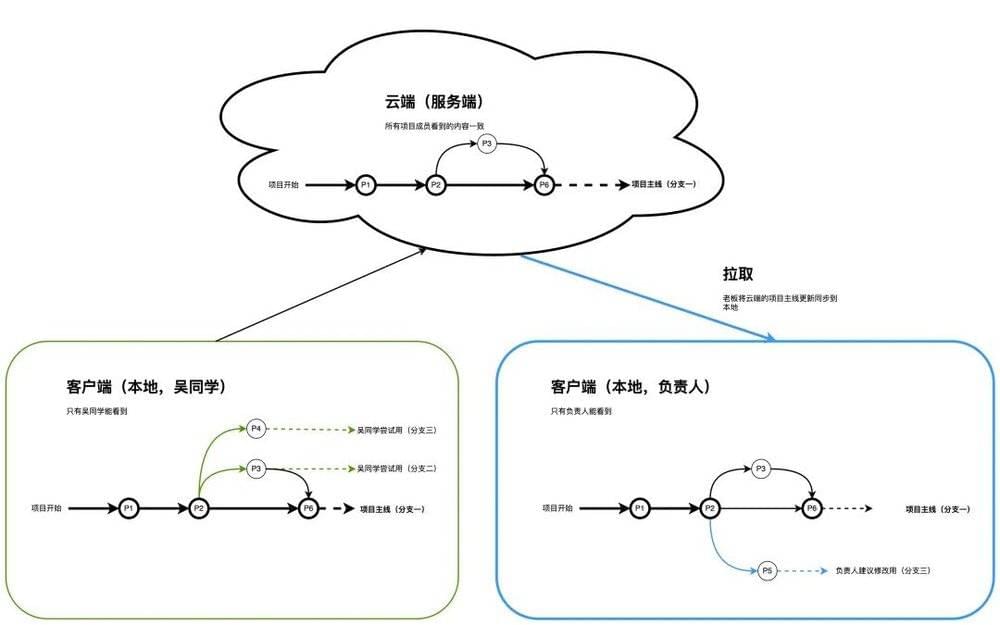
拉取到客户端本地之后,负责人则可以将P6的进展合并到自己正在开展的分支三,以跟团队工作保持同步。
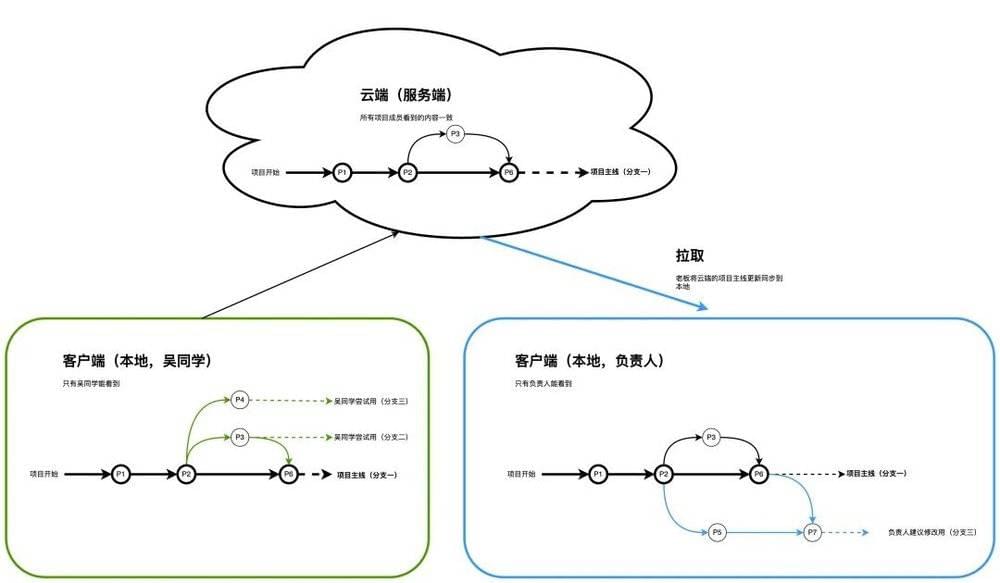
在不断地拉取、推送过程中,我们实现了多人的协同。这里云端(服务器)存的是团队项目有实际意义的进展,而各个项目成员自己的客户端(本地)则是大家并行开展设计尝试的工作台。这就实现了多人多端分布式高效协作、项目图纸集中式可靠控制,不管团队是2个人、还是200个人、甚至更多。
3. 机械设计不一样的地方
至此我们已经通过MGit构建了一套融入Git理念的版本控制系统,但由于代码和图纸文件类型区别很大,代码看的是文本文件,而图纸看的是抽象的几何图形。所以如何提高多人协同过程中大家对于图纸的沟通交流效率也是MGit针对机械设计领域需要专门解决的问题。

如何在浏览器实现常用CAD模型的在线浏览、审阅、批注?这一项相对于前文原子功能的构建反而更简单,基于WebGL则可以实现,当然还涉及浏览器上的文件格式定义、不同格式文件的服务器转化和轻量化处理等。
4. 再次聚焦到工作流
完成原子功能构建之后,我们也就实现了机械设计工作流支撑的基础设施,也能跟Git一样衍生新的工作流,颠覆性提高机械设计多人协同工作效率。并且Git领域常用的工作流模式在机械设计领域同样可以借鉴,比如长效分支模式工作流、主题分支模式工作流。只不过在机械设计,长效的阶段划分可能就是概念、结构、仿真、打样、批量...;也或者可能是按功能模块进行主题划分,比如ID设计、机械、电气;更细一些的话则可能是车轮、车体、发动机等更具体的分支划分。
如何归纳累积出行业最佳实践的工作流?这往往更难,构建MGit只是起点,提供了一个用于工作流演进的底层支撑,但持续的演进需要各行业的不断实践。
五、总结
在我们看来,对先进制造企业而言:
如果说工业数字化决定了其能否跟上时代的步伐;
那么先进组织模式则进一步形成其能否脱颖而出成为伟大企业的内核;
同时工业数字化工具又作为先进组织落地实践的承载体。
所以机械设计高效工作流的实现,需要的不仅仅是一款工具,而是以该工具为载体支撑起的先进组织理念、先进工作流模式的探索。
以更高效的文件版本控制系统支撑更高效的工作流演进。在我们构建的底层原子功能基础上,或许有可能再造机械设计领域专属的全新工作流模式。
本文来自微信公众号:追光几何(ID:EverCraft),作者:少侠、周五、余鱼