
本文来自微信公众号:半导体行业观察 (ID:icbank),作者:李飞,头图来自:视觉中国
我们正在目睹GPU市场的重要转折。
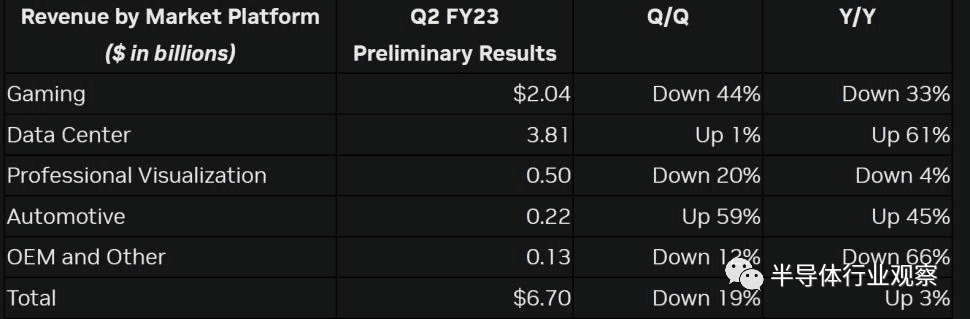
八月初,GPU龙头企业Nvidia发布二季度财报预警,其中提到公司的二季度收入比之前的预计大幅下降,其主要原因是由于游戏市场和加密货币市场在2022年的规模大大下降——相关的收入同比下降33%,环比下降44%。我们认为,这标志着GPU市场正在加速进入转折期,这也会加速GPU相应公司寻找新的增长点。
传统上,GPU最关键的市场是游戏市场,这包括了PC主机上的GPU,以及游戏主机中的GPU,然而从长期大趋势上来看,PC主机和游戏主机的市场增长正在趋缓,甚至有下降的势头。
从短期来看,2021年新冠疫情导致居家办公等新的工作状态导致了PC和游戏主机相关需求短暂上升,而目前这样的非常态带来的福利已经结束,对于GPU需求也在大幅下降。此外,加密货币的繁荣也曾让GPU一卡难求,但是随着加密货币市场的崩溃,对于GPU市场也造成了一定的影响。
根据Digitimes的报道,GPU在2022年的出货量预计将比2021年下降40%~50%(这个数字和Nvidia的第二季度预报也相符)。总之,无论是从短期还是从长期来看,传统的游戏行业已经很难成为GPU市场的增长点。
一、未来GPU的市场在哪里?
其实从Nvidia的财报中我们也可以看出,数据中心将会是GPU的新增长点。数据中心中的GPU主要用于高性能计算,包括人工智能相关的计算和视频处理等。在Nvidia公布的第二季度预报中,数据中心相关的收入同比增长高达61%,且收入已经高于游戏市场,可见数据中心增长势头之猛。
数据中心中使用GPU预计未来还会在未来呈快速上升态势。人工智能将会进入越来越多的应用中,而在数据中心侧人工智能模型的训练和推理,目前最佳的解决方案就是GPU。我们目前看到人工智能模型的复杂度正在快速上升,训练所需要的数据量也在越来越大,这也意味着单个模型需要的计算量正在上升,同时结合模型部署和训练数量的上升,两者的乘数效应使得数据中心对于GPU的需求仍然会持续上升。
除了高性能计算之外,另一个未来可能的新增长点是元宇宙相关的图像渲染任务。随着MR/VR硬件和相关应用的成熟,如何为用户提供高性能的图像渲染将会是相关用户体验的核心要素。如果元宇宙的VR/MR真的如预期的一样会成为一个巨大的市场,那么相关的渲染任务也将会成为GPU的一个新增长点。当然其中也存在着很大的不确定性,首先元宇宙和VR/MR是否会如愿增长还不清楚,此外相关的渲染会在云端完成并且通过网络串流的方式来到用户的本地显示,还是使用本地的GPU直接做渲染,相关的技术方案还没有定论。
综上所述,我们认为GPU市场的转折将会是传统游戏相关收入逐渐饱和(甚至在短期内大幅下降),而在人工智能和高性能计算(即GPGPU)相关的数据中心市场会成为目前和中期内的首要增长点,远期来看元宇宙相关的渲染任务有可能会取代传统游戏相关收入,但是还存在很大的不确定性。
二、GPU技术演进路线
如前所述,数据中心中的人工智能和高性能计算正在成为GPU目前最关键的增长点,因此GPU厂商技术研发目前也主要围绕这个目标。这里我们将会分析GPU领域两大龙头Nvidia和AMD的相关技术路线图,来分析一下GPU在未来几年内演进的一些重要技术路线。
首先是专用加速器与通用GPU的融合。在人工智能硬件刚兴起的时候,使用专用加速器还是使用通用GPU做加速几乎是两大阵营——专用加速器效率高但是只能支持几种特定的算法和模型;通用GPU兼容性好,但是效率较差,功耗也较大。
但是,随着人工智能硬件的演进,目前我们看到通用GPU和专用加速器正在慢慢融合,或者说在GPU上我们在看到越来越多的针对一些特定人工智能模型的专用IP来实现加速。举例来说,混合精度计算和低精度整数运算加速已经成为数据中心GPU的标配。
在这个领域,Nvidia更为激进,凭借其对于人工智能模型生态的大量布局和龙头地位,Nvidia能够把握人工智能模型发展的态势(如新模型的流行程度)并且据此在GPU产品上加入相关支持。在Nvidia下一代的H100 GPU中就加入了对于Transformer系列模型的专用加速模块,而这样的专用加速模块集成在通用GPU中恰恰说明了通用GPU和专用加速器之间的融合将会是未来的重要技术演进方向。
除此之外,决定GPU计算性能的关键指标是存储访问带宽和延迟。在这个方面,增加DRAM带宽,使用HBM等最新的内存接口已经是GPU的标准配置,相信未来随着DRAM接口标准的演进,GPU也会优先使用最新的DRAM接口。而除了DRAM之外,高速缓存(cache)也是关键的存储,缓存容量会大大影响计算的延迟和功耗。
Nvidia和AMD都在积极地扩大高速缓存的容量,在这方面AMD使用新技术的步伐则领先Nvidia——目前Nvidia在H100增加缓存主要还是考虑2D的方式即在同芯片上加大缓存面积,而根据AMD今年六月份公布的最新CDNA3 GPU架构,CDNA3会使用高级封装技术,使用单独的缓存芯片粒(chiplet),并且将缓存芯片粒和GPU使用堆叠的方式集成在一起(即Infinity Cache)。这样一来,高速缓存芯片粒的存储容量就有可能大大增加,从而提升性能。
在存储之外,另一个数据中心端GPU技术演进的重要方向是如何减少CPU和GPU通信带来的性能损失。在传统设计中,CPU和GPU处于两个完全不同的系统,其内存空间并不共享,因此CPU和GPU之间的通信开销很大。
为了解决这个问题,Nvidia和AMD都在这方面做了不少投入。Nvidia的解决方案是使用自研的基于ARM架构的Grace CPU,并且在架构设计上给每个GPU单独配一个CPU并且使用NVLINK高速接口连接在一起,从而减小CPU和GPU之间的协同工作开销。
而AMD因为一直同时有GPU和CPU业务,因此相关的设计在技术上更为激进,在CDNA3架构中CPU和GPU将会使用高级封装的方式集成在一起,共享HBM3高速内存接口和内存空间,从而大大增加CPU和GPU之间的集成度和协作的能力。

综上,我们认为未来服务器端GPU将会是GPU市场最重要的市场增长点,而围绕这个增长点有几个重要的技术路径将会成为主流,包括专用加速IP和通用GPU融合,高速DRAM和缓存的进一步演进,以及CPU和GPU的进一步集成。
比较Nvidia和AMD的技术路径,我们可以发现Nvidia的强项在于坐拥人工智能生态护城河,通过极强的软硬件协同设计能力和对于人工智能领域的洞察力,它在专用加速IP和通用GPU融合方面做得极为成功,因此可以通过最小的成本和功耗代价来实现最大化的相关任务性能提升。而AMD的强项在于其高级封装领域的积累以及在CPU领域的经验,未来可望使用晶圆级技术的突破来提升性能。
三、市场竞争格局
未来市场竞争格局而言,Nvidia和AMD都是从传统的游戏市场切入,在保持传统游戏市场的同时,也正在把精力越来越多地投入云端市场。Nvidia目前拥有服务器市场GPU的领先地位,但是从技术发展角度来看AMD的势头也很不错,其关键在于能否打通软件生态,如果能突破Nvidia CUDA的生态包围圈的话AMD可望在服务器市场也拥有重要的一席之地。
在服务器市场另一个值得关注的新势力是中国的GPU初创公司。以燧原,壁仞等为代表的GPU中国新兴势力也把服务器市场作为其主打方向。从市场动态上来说,其实目前是一个很好的时间点,因为在GPU市场来看,中国GPU较为薄弱的游戏渲染等领域正在被服务器市场增长所取代,而在服务器市场相对来说中国公司的技术包袱并不大,可以轻装上阵。随着未来国际形势的变化(例如逆全球化),可望中国的GPU新势力也能获得GPU市场的重要份额。
本文来自微信公众号:半导体行业观察 (ID:icbank),作者:李飞