
事情是这样的。
前不久谷歌不是出了个AI创作神器Imagen嘛。
只要你给一句话,它就能生成符合语意的图片。
然后脑洞大开的国外网友们,不按套路地给Imagen出了道题:
给宋代的东方老虎佩戴VR。
Imagen也没在怕的,“啪的一下”就给出了一幅力作——《虎戴VR》。

还别说,这幅《虎戴VR》还真是有点那味了。
不仅是画风上,VR头戴跟老虎以及整幅画作能够保持一致。
就连手柄、双虎嬉戏的感觉也都一步到位地画了出来。
然后还有两只老虎戴VR,手牵着手一起“恰恰恰”的:

甚至Imagen还别出心裁地设计了个“连线”版VR(可能在面对面看片吧):

但毕竟在AI作画这事上,除了谷歌Imagen之外还有很多神器。
于是,一场《虎戴VR》作画大战就此拉开序幕。
(猜猜谁家的画更有“心有猛虎,细嗅蔷薇”的味道

)
DALL-E也来请战
首先来应战的,定然是OpenAI家的DALL·E。
网友Jacob出于好奇,便用它做了几幅来做比较。

首先是满满“定妆照”风格的《虎戴VR》(很飒啊):

不难看出,DALL·E的画作和Imagen在风格上还是有很大的区别。
Imagen的画作更趋于简约线条风,而DALL·E则更多了些许油画的元素。
不过在意境方面,DALL·E也是能够产出“双虎嬉戏”,甚至是拟人的画作:

二者相比之下,网友们给出了他们的评价:
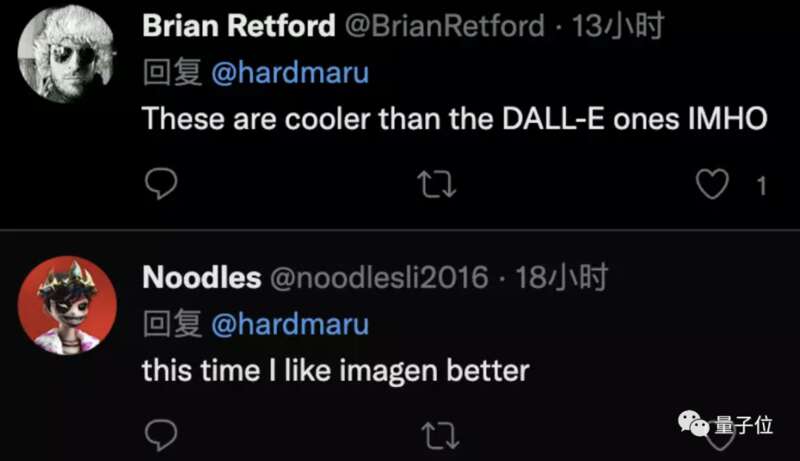
大多数网友们对谷歌家的Imagen更买单。
而除了它俩之外,像AI绘画神器MidJourney也参与到了此次“大战”。
不过它的作品,就显得略有些诡异了……

DALL·E VS Imagen
那么,同样作为AI创作神器,最近大火的Imagen和DALL·E为何画风会截然不同呢?
Open AI的DALL·E和谷歌的Imagen,都可以直接通过文本描述生成类似超现实主义的图像,让机器也能拥有设计师般的创造力。
不过,二者的“创作”原理大相径庭。
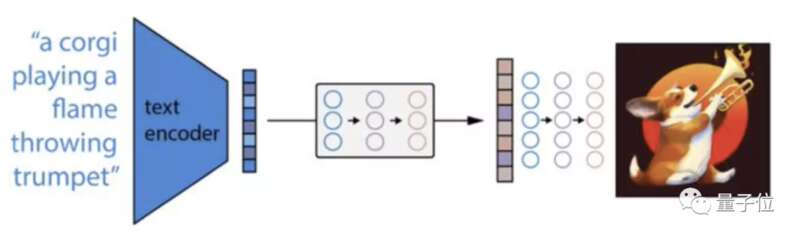
DALL·E 2采用CLIP将文本特征映射到图像特征,然后指导一个GAN或扩散模型生成图像。
所谓CLIP,是一个在各种图像和文本上训练的神经网络,对生成的多张图片进行排序,挑选出更好的生成结果进行展示。
而谷歌的Imagen则使用纯语言模型只负责编码文本特征,把文本到图像转换的工作丢给了图像生成模型。
语言模型部分使用的是谷歌自己的T5-XXL编码器,将训练好的文本冻结。
图像生成部分则是一系列扩散模型,先生成低分辨率图像,再逐级超采样。
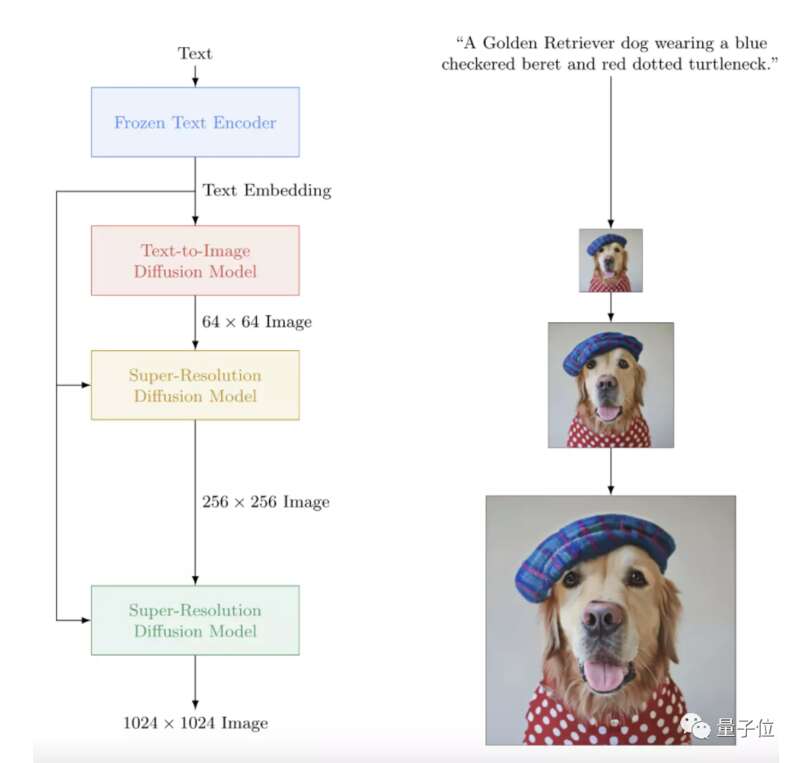
谷歌的T5-XXL有46亿个参数,而扩大文本编码器的规模,可以有效改善文本到图像的对应关系,和图像的保真度。
此外,Imagen还使用了另一种称为noise conditioning augmentation的扩散技术,帮助模型学习已添加的噪声量,从而提高图像的还原性。
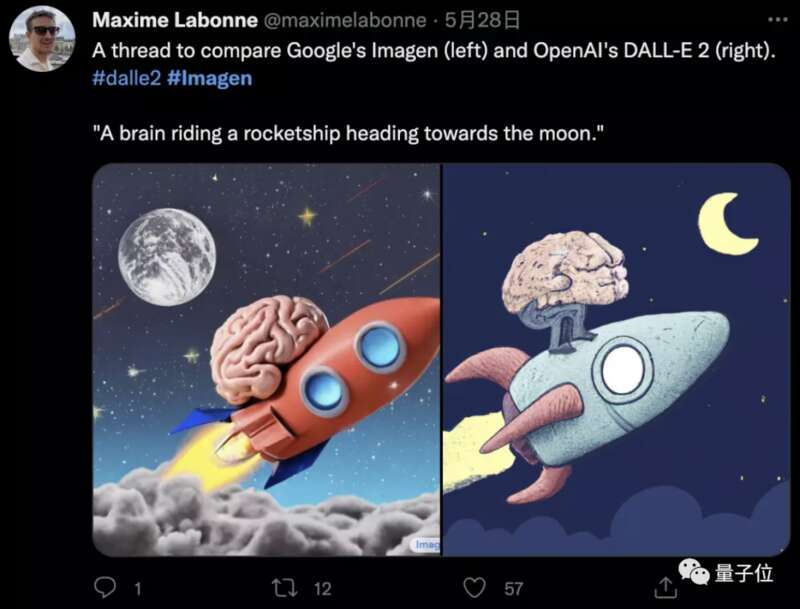
对比来看,Imagen似乎比DALL·E更具有“写实”的特点:
目前,在Imagen官网上已涌现出各种新奇的图像。
有人给浣熊戴上了宇航员头盔。

泰迪熊在这里开始游蝶泳。

还有老鹰型的巧克力冰淇淋(嗯,还挺应景)。

截至目前,Imagen和DALL·E都还在调试阶段,尚未向公众开放。
One More Thing
这次《虎戴VR》AI作画大战中,也不乏有失败的作品。
例如有网友就给出了用DALL·E mini来生成的示例。
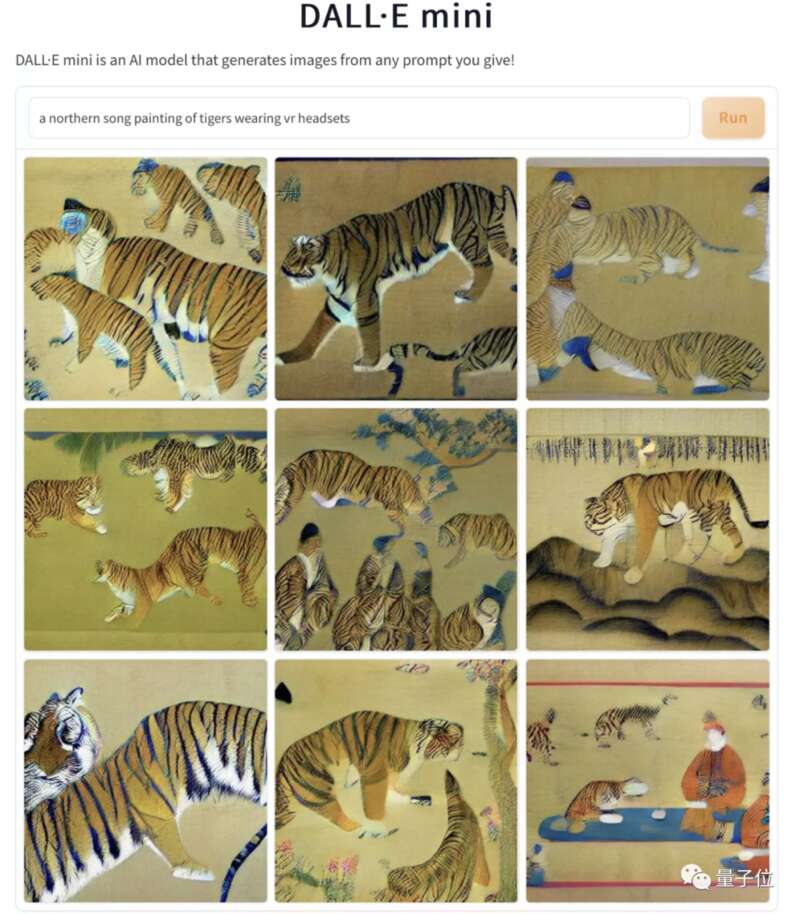
不难看出,在这版中的《虎戴VR》中,并没有任何VR的出现,而且老虎的面部基本上都是模糊不清。
据网友描述,他在生成的过程中,只是把“北宋”改成了“南宋”:
画作最难的“形象性”,在这次有所下降。

那么你觉得《虎戴VR》,哪家AI神器更强一些呢?
参考链接:
https://twitter.com/hardmaru/status/1532757753797586944?s=21&t=MhwVN5VXH22zFK7DWQJnCg