
本文来自微信公众号:元天空之城(ID:gh_a702b8d21cdf),作者:城主,原文标题:《虚拟人的手工前世和AI今生: (虚拟人, 虚幻引擎和独立影视创作系列之一 )》,题图来自:作者
写在前面
这一次,我们来个有点跨界的主题:分三篇探讨一下虚拟人、虚幻引擎,以及两者将如何影响独立影视创作。
三篇预计为:
一、虚拟人的手工前世和AI今生
二、虚幻Unreal如何成了最适合做影视的3D引擎
三、虚拟人和虚幻引擎对独立影视创作的影响:可能的和不可能的
这里的“独立”,指的是有驾驭能力的个人和独立工作室。
就像曾经辉煌一时的中小型计算机最终被微型个人计算机取代了主流市场地位,七两未必不能拨千斤。独立创作者,在新技术的加持下,是否有可能撬动目前的影视创作生态?
且就慢慢叙来。
作者比较喜欢先定义讨论范围,这次也不例外:本篇讨论的是什么虚拟人?
虚拟人是目前的热门词汇,因此也成为了标准的箩筐概念:什么都可以往里面装,比如二次元主播,企业人工智能客服,元宇宙的NPC……都可以自称虚拟人。
而本系列真正关注的目标,是那些“照片级”超写实虚拟人。我们期待这种以假乱真的虚拟人在某种程度代替真人演员,在未来参与到影视创作中去。
虚拟人的几个时代
目前网上对虚拟人的发展历史有一个比较通用的四阶段划分,不知道是哪位大佬给定义的。我们不妨遵循这个划分,先做一点简单的回顾。
第一阶段:八十年代 萌芽期 初代歌姬
让我们从林明美开始:公认的初代虚拟歌姬,第一个虚拟偶像。
对于动漫迷而言,林明美有更让人熟悉的身份,那就是80年代日本经典动画片《超时空要塞》的女主角,她那首著名的《可曾记得爱》,在浓缩动画剧集情节的84剧场版的结尾高潮时唱起。
《可曾记得爱》是在超时空要塞Macross向入侵的外星军团发起总攻的时候向整个战场唱起的。明美作为人类的头号歌姬,在人类文明面临着外星敌人毁灭性的打击之时,唱出了这首歌,激发了所有人的斗志,更让部分外星军队产生文化共鸣而起义,一举扭转了战局。男主角一条辉(也是前男友……)在明美的歌声中,驾驶变形战机最终突入敌军腹地,给予了外星大首领致命一击。
这首星际大战中6分钟的完整Live,战火与歌声的交织,极致的壮丽和浪漫留下了动画史上永远无法超越的经典一幕。可以说,明美一曲之后,动画片里再无虚拟歌姬,出道即是巅峰。
林明美是虚拟偶像的开端,动画公司以她的虚拟形象发行了唱片,虚拟人第一次进入了现实世界。而经过近40年的时间,明美的形象仍深入人心。
从动画水准来看,当年巅峰之作的纯手绘动画现在已彻底被3D动画潮流所取代,但明美至今让人津津乐道的原因和技术无关,纯粹基于人物设定以及大气磅礴的故事背景所衬托出的“宇宙歌姬”符号。
所以用明美作为本系列的起始还挺合适的:
林明美就是一个从影视中走出的虚拟偶像。可以这样说,明美给了我们一个启示:成功的虚拟偶像,除了技术支持,更重要的是,他/她必须拥有作品所赋予的灵魂。
第二阶段: 21世纪初 探索期 影视娱乐的试水
时间一下就跳到了2000年。
(从这个时间跳跃上,我们也能感觉到,初代歌姬林明美是多么牛的存在……)
在这个时期里,虚拟人终于摆脱了传统手绘的限制,第一代3D虚拟人偶像开始出现, 比较有代表性的是2007年在日本出现的初音未来。
在这个阶段,虚拟人偶像都是简单的二次元形象,也契合了当时3D的CG水平:复杂的做不好,做点简单的二次元形象正合适。
有趣的是,初音未来其实是一款歌曲合成软件,当时的 CRYPTON FUTURE MEDIA 以雅马哈的 Vocaloid 系列语音合成程序为基础开发音源库,并以此制作发售了虚拟歌姬角色主唱系列,初音未来也由此走进大众视野。
而中国对标初音未来的虚拟歌姬洛天依则在2012年出现。
值得一提的是,虚拟歌姬发展的关键,被实践证明是同人创作的UGC。
当时初音未来发售后,大量翻唱歌曲就被发表在日本的论坛上;公司随后开放了二次创作权,鼓励粉丝创作;加上其本身没有详细设定,日本UGC网站上出现大量粉丝制作的美术人设/音频/视频内容,甚至还诞生了一些“大神”级别的同人创作者,极大丰满了初音的内容内涵,更让初音未来放大了粉丝圈层,并随着粉丝创作的洗脑神曲屡次出圈。
而中国的洛天依也走出了类似的道路, 经历了几年PGC(专业内容创作)运营情况不佳后, 公司开始鼓励UGC创作,大量同人作品涌现,洛天依这个虚拟偶像才真正站稳了脚跟。
这个时间段里, 电影工业里一个著名的虚拟人也出现了, 这就是2001年电影《指环王》里的咕噜 (其实称之为虚拟怪物更恰当)。
咕噜完全由动作捕捉技术和CG技术产生, 前所未有的动作捕捉加3D CG形象的合成效果惊艳了世界。 现在基于动作捕捉的3D荧幕形象很平常, 但当年咕噜可以说在电影行业轰动一时。
而到了2008年,神作《阿凡达》又达到了另一个高度:全程运用动作捕捉技术完成表演,CG技术创造整个虚拟世界,此乃后话。
让我们深究一下,为什么虚拟人的第一次发展是从2000年左右开始的?那个时间点发生了什么事情呢?
在1999年,NVIDIA发布了它标志性的产品GeForce256,这个系列产品开始正式支持3D图形运算里特别重要的T&L功能(坐标转换和光源)。
要知道,3D图形的解算就是由各种复杂的坐标转换和光源计算组成的。在GeForce256之前,所有的坐标处理和光源运算都靠CPU处理;而当图形芯片具有T&L功能后,CPU就彻底从繁重的图形计算中解放出来。
从此,图形芯片可以真正被称为GPU,和CPU并驾齐驱了。
或许正由于个人计算机3D图形加速能力的突飞猛进,向大众普及了3D图形加速的使用场景和能力, 带来了3D虚拟人的第一次发展。这个时期,市场规模还比较小,动捕、CG等关键技术还不够成熟,也没有足够的资源支持,可以说是娱乐业关于虚拟人的试水阶段。
第三阶段:2016-2020 成长期 技术突破带来的应用普及
2016年到2020年这几年一般被划分为虚拟人的第三个阶段。
这几年里有哪些虚拟人出现呢?其实让人能记住的并不多。必须提及的是,这个时间里,诞生和发展了世界首位虚拟主播,即YouTube 上的“绊爱”。
2016年12月1日,YouTube频道“A.I.Channel”开设,“绊爱”成为世界上第一个自称虚拟主播的视频博主,从此确认了虚拟主播VTuber的概念,开启了二次元风格的虚拟人时代。
出道 3 个月,“绊爱” YouTube 粉丝数就超过了 20 万;到了 2018 年 7 月 15 日,绊爱的主频道订阅人数突破 200 万人。到2022年,其YouTube主频道和游戏分频粉丝总数超 400 万。
不过,恰好在不久前的今年2月26日,“绊爱”在举行了线上演唱会“Hello World 2022”后,宣布进入“无限期休眠”。初代虚拟主播走完了完整的演艺生涯周期。
和真实世界的明星相比,虚拟明星的兴衰背后也没有更多新鲜事。不外乎就是粉丝关注度的逝去,粉丝群体的割裂,公司的运营失误,如此这般。
虚拟偶像也走出了人格化的演艺圈道路。
而这几年间,技术上又发生了什么呢?
除了3D领域的建模,渲染和动作捕捉技术日益成熟;这几年还是基于深度学习的人工智能技术爆发式增长的时期。
2016年3月,英国DeepMind公司基于深度学习的围棋程序ALphaGo以4:1击败顶尖的职业棋手李世石,成为了第一个击败职业九段的计算机围棋程序。作为标志性的事件,人工智能走进了公众的视野,引发了AI的全面火热。
在这个阶段里, AI能力也开始运用在虚拟人身上,主要体现在AI语音的能力与虚拟人服务形象的结合,例如2018年搜狗和新华社推出的AI主持人,以及2019年浦发银行和百度合作开发的数字员工“小浦”等等。
第四阶段:2020至今 新时期 新的气象
近两年,“虚拟人”成了热门话题。在当前语境下,大家理解的“虚拟人”多数是指所谓“照片级”的超写实虚拟人。
或许有几方面原因让当前“虚拟人”的标准变得如此之高:
软硬件的发展终于足以支撑这一终极水平;
用户的口味更挑剔, 典型案例也提高了公众预期;
资本也需要虚拟人产业讲出新的故事。
归根结底,最重要的还是用户期待有这种以假乱真的虚拟人体验。超写实的虚拟人物有更好的代入感,也能更好的接入现实世界的商业信息。
虚拟人这股热潮到了2021年愈加明显,互联网不同领域的公司都在卖力发展虚拟人业务:
2021年5月,AYAYI超写实数字人推出,目前小红书粉丝12.6w,抖音粉丝8.3w。
2021年6月,B站宣布在过去一年里共有超过3.2万名虚拟主播在B站开播。虚拟主播成为B站直播领域增长最快的品类。新生代虚拟主播更加多样化且更接地气。
2021年11月18日,NVIDIA推出全方位的虚拟化身平台Omniverse Avatar,CEO黄仁勋现场演示了由这个平台生成的能与人自然问答交流的“迷你玩具版黄仁勋”Toy-Me。
2021年12月31日的跨年晚会,不约而同地,多个主流卫视平台都引入了虚拟人元素,其中最出彩的当属周深和虚拟人“邓丽君”同台演唱的《小城故事》。
且不论各家节目最终效果如何,多个虚拟偶像同一时间登陆各家主流跨年晚会,这本身说明了很多问题。
而要说目前国内最火的虚拟人偶像,当属柳夜熙。

而到了成熟的LightStage5,则被广泛用于好莱坞的各种大片,很多都是耳熟能详的,比如《本杰明巴顿奇事》《蜘蛛侠3》《阿凡达》……
严格上来说,LightStage这个大杀器的核心技术光度立体法并不测量几何结构,还是要靠类似摄影制图的方法来获取人像的准确3D模型,然后再用光度立体法对模型表面进行高精度细节的计算 - 这就是Light Stage能还原皮肤毛孔结构细节的原因。也正因此,LightStage扫描技术能够得到众多好莱坞大片的青睐。
不过,尽管LightStage是个有公开论文的成熟系统,其最核心的模型表面高精度细节计算并没有公开的解决方案,很多算法细节无从知晓,导致国内长期以来一直没有这种级别的扫描技术出现。
由于核心算法的缺失,国内市面上大部分球形扫描系统使用的依然是上面提到的摄影制图方式,采用球阵只是为了控制光照均匀以及相机标定等,这样的系统在最关键的皮肤细节精度上无法和LightStage匹敌。
(据说随着Reality Capture软件的升级,摄影制图法现在勉强能接近毛孔级别的细节,也算一种经济适用的重建方式。)
最近国内已有几家企业研究实现类似Light Stage的系统,希望国内早日用上Light Stage级别的三维人脸重建。
除了Light Stage之外,还有另一种动态光场重建概念,这种所谓“光场成像”的思路更简单粗暴:不管物体模型和表面材质,直接从各个角度采集三维物体在各种条件下的光线反射信息,然后在渲染时对采集的光线进行重组输出,就可以让人看见“真实”的三维世界。
大家是否注意到了,所谓打造“真实感世界”的顶级方法,最后都返璞归真:
把所有的信息都尽可能采集一遍,重组计算后输出。
无论是三维重建,还是后面各种基于大数据融合的虚拟人驱动方法,其核心思路无不如此:从现实中来,回到现实中去。
大数据加持的捏脸游戏
花了一些篇幅介绍了这个星球上最牛逼的三维重建技术,但结论却有点无奈:这样的人脸扫描重建成本和门槛都过高了,独立影视创作不用指望这种核弹级别的系统。
但没关系,我们还有大数据和人工智能。
这里的想法也很简单,虽然没有高大上的系统直接扫描真人,但如果可以利用现成的扫描数据,再结合类似游戏捏脸的交互系统,是否能面向普通用户提供照片级超写实虚拟人的生成服务?
真有人这么做了,这就是Unreal虚幻的MetaHuman Creator。
(是的,又是虚幻)
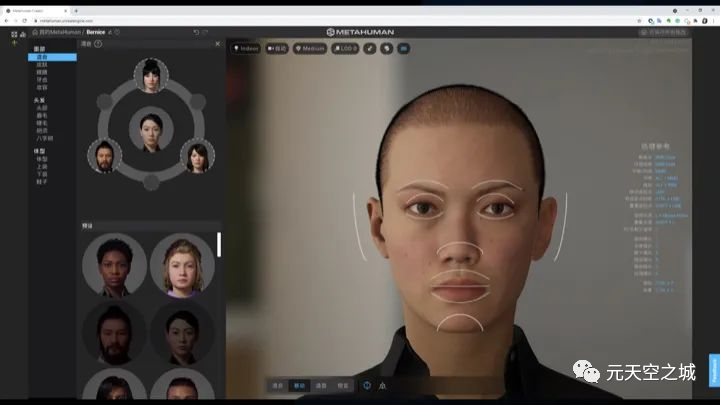
值得一提的,MetaHuman Creator是一个云端渲染服务,用户通过网页连接和进行交互操作,所有的数据运算和生成都是云服务渲染;而云端后台使用的,就是Unreal虚幻引擎本身。
MetaHuman初看上去似乎是一个很简单的系统,颇有点游戏创建角色捏人脸的感觉。
但简单的背后,其实是多门计算机学科最新技术的结晶:
超大规模的4D人类面部扫描,基于机器学习的数据处理和融合,实时3D引擎支持,云渲染服务……无数计算机科学家和工程师的智慧打造出了一个普通人可以上手创作的超写实虚拟人生成系统。
(注: 暂时没更多资料披露,但从数据结果来看,MetaHuman 4D扫描数据应该类似LightStage的光场扫描重建)
事实上,目前MetaHuman基于大数据的模型融合只完成了人脸部分——当然这也是最难的部分;而身体部分,仅提供了传统的基本样式选择. 原因很简单,尚没有全身模型的扫描大数据支持。
尽管如此,MetaHuman Creator实现了面向普通消费者的超写实虚拟人生成服务(居然还是免费的, 线上生成的虚拟人可以直接数据导出使用), 这已经是一个很了不起的事情。
毫不夸张的说,MetaHuman Creator在虚拟人制作上实现了技术突破,极大简化了超写实虚拟人的创作过程,某种程度上,让虚拟人制作真正飞入了寻常百姓家。
如果继续替用户考虑,一般人如何设计一个帅气/漂亮的虚拟人呢,或许对着明星照片捏脸是一种方式。
但明星脸这种事情,往往涉及肖像版权;而在影视制作中,版权是个重要问题。
有办法可以自行生成一个漂亮人脸吗?
在人脸创作这个小细节上,大数据加持的人工智能又一次展示了它的巨大威力。通过深度学习技术,我们已经可以生成各种风格倾向的人脸。以下是作者基于公开的深度学习模型随机生成的一些东方明星人脸和欧美普通人脸。


如果哪天,MetaHuman Creator增加一个上传人脸照片自动学习和匹配捏脸的功能,那就真的是“一键喜提虚拟人”了。
顺便提一下,前面提到过的虚拟人AYAYI,正是由MetaHuman Creator打造的。
到这里,打造虚拟人模型的故事就差不多了。
在打造了3D虚拟人模型后,其实紧接着还有一项很有挑战的工作——把人物模型各个部位正确地绑定到之后用以驱动动作和表情的控制器上。这就好比把皮肤和底下的肌肉和骨骼正确连接在一起,这样静态的模型才有可能被驱动起来。
在这点上,类似MetaHuman这样的捏脸系统稍微好一点,毕竟是通过同一个原始模型衍生而来,内部的驱动机制可以统一做好;而对于直接相机阵列扫描得来的超写实模型,绑定是一个很繁重的工作;这个领域目前也有了大数据和AI技术的加持,不再赘叙。
让虚拟人动起来: 关键帧动画、动作捕捉、AI驱动
关键帧动画
在很长一段时间里,我们驱动一个3D模型,无论虚拟人还是虚拟怪物,让模型动起来的方法就是关键帧动画。
关键帧动画是容易理解的概念,有点类似黏土定格动画,把黏土人偶摆出一个动作拍一帧,持续摆拍完成后再以24帧每秒的速度播放,就得到了连贯的黏土动画。很明显,打造这样的动画需要惊人的耐心。
关键帧动画和黏土动画的机制很像,读者可以理解为把现实的黏土人偶换成了软件里的3D模型,制作者在时间轴上摆出模型的一个个动作(关键帧),软件实现动作间的过渡,从而打造了一个3D人物的关键帧动画。
人们想了很多方法去提高关键帧动画的效率,但本质上,关键帧动画还是由3D动画师一帧帧手工抠出来的。
动作捕捉
和3D建模一样,从生产效率,输出质量和人力成本等各方面而言,纯手工的关键帧动画方式都无法被工业化大规模生产流程所接受。自《指环王》的咕噜开始,动作捕捉技术走进了大众的视野。
顾名思义,“动作捕捉”就是直接捕捉采集表演者的动作,然后去匹配驱动虚拟人模型。这是目前虚拟人动作生成的主要方式。
动作捕捉这个事情,有一个有趣的路线区分,有点类似自动驾驶汽车感知系统路线之争:
自动驾驶的核心是要通过传感器感知周围环境,有两种方式:纯视觉摄像头和激光雷达。哪种路线更好,视觉派和雷达派至今还PK得不亦乐乎。
动作捕捉,也分为两大派系,光学动作捕捉和惯性动作捕捉。
光学动作捕捉是在一个摄影棚四周架上一圈摄像头,360度无死角对着表演者拍摄;表演者身上标记着很多反射红外光的标记点(marker),通过多摄像头对反光点的同步追踪,计算机计算得出演员动作。
惯性动作捕捉呢,则是在人体特定骨骼节点上绑上惯性测量元件(加速度计+陀螺仪+磁力计等等),通过对传感器测量数值进行计算,从而完成动作捕捉。
光学动作捕捉是当前电影工业的主要生产方式,因为精确度足够高。
但问题是:尽管效果很好,但光学动捕对于大众化普及没什么意义。一般人很难拥有这种昂贵的光学动捕摄影棚,场地和设备的需求注定了这是一个相对阳春白雪的技术。
惯性动捕的成本则低得多。目前,小几万人民币的成本,可以拥有一个包括动捕手套在内的全身惯性动捕设备,这价格对网红大V不是问题,普通创作者咬咬牙也买得起。
和相对低廉的价格相比,更重要的是,惯性动捕设备对场地大小没有要求。
目前一些高端的虚拟主播使用惯性动捕设备做直播已不是什么稀罕事了。
不过惯性动捕有个小问题,随着连续使用时间的增加,测量元件会产生累计误差,因此使用一段时间后需要重新校准。此外,尽管已比较友好,惯性动捕仍不是特别方便,比如使用时需要全身绑上测量单元,还需要避免环境中有磁场的影响……
想偷懒的技术宅不会完全满意。
一定有读者在想,我们的个人电脑上都有摄像头,如果不用架一屋子摄像头,而只依靠一或两个摄像头,就像人的双眼一样,就能准确识别动作,实现动作捕捉该多好啊。
这个想法其实很多人都有,而真正的践行者,正是大名鼎鼎的微软,产品就是在XBOX上推出的光学和深度摄像头结合的Kinect。
在Kinect设备的规模化生产以及相应算法处理上,微软投入了巨大的人力和财力。但很遗憾,经过了两代XBOX的实践之后,Kinect最终被放弃。数据显示,Kinect的累计销量超过了 3500 万台。所以Kinect不能说是一款失败的产品,至少它在前中期对扩大XBOX品牌的影响力是有功劳的。但最终Kinect壮志未酬,对微软的很多同学来说, 都是有遗憾的。
Kinect黯然离场后,它的核心技术仍继续发光发热。作为Kinect最初的技术提供商(后期微软已自行做了改良)PrimeSense在Kinect上市三年之后,于2013年被苹果公司以3.6亿美元的价格收购。所以,现在的苹果手机内置深度摄像头,且FaceID在原理上和Kinect有相同点,就不足为奇了。
主机游戏娱乐系统行业里,当年也有着Sony PS VR手柄体感和XBOX的Kinect体感之争,即惯性和视觉路线之争。在这个领域里,最后视觉路线失败了。
除了用户交互体验的问题,Kinect在技术上也受限于当年的硬件性能,毕竟只是一个家用娱乐系统的附属设备,Kinect的摄像头分辨率,XBOX上的算力限制和内存限制都制约了其对人体动作识别的精度。
尽管Kinect出师未捷,但基于单摄像头的视觉动捕应用仍在继续发展。对于个人用户,使用单摄像头实现动作捕捉是一个非常实际的需求。
在今天,基于单摄像头的人脸和半身动作捕捉,已经是一些二次元虚拟直播软件和短视频APP的标配了。但平心而论,这些视觉动捕的应用,目前只是玩具,娱乐一下OK,尚无法满足工业生产的精度要求。
为什么说是玩具呢,举个简单的例子:市面上仍没有任何一款商业化的视觉动捕软件能很好的捕捉双手十指的动作(如果已经出现了,请读者不吝纠正)。做不到捕捉肢体动作的细节,视觉动捕工具就无法进入生产领域。
不过让人兴奋的是,大数据、深度学习和计算机视觉的进一步结合提供了很多可能性。据闻在一些大厂的研究机构里,已能看到基于手势动作大数据库+深度学习视觉识别的方式,来获得非常精准的单摄像头手势识别结果。
乐观估计,在未来一两年内,我们或许就能用上工业精度的单摄像头视觉识别产品了。
对于独立影视制作而言,需求就是简单易用精度OK的真人动捕,光学动捕过于奢侈。目前首选的方式是惯性动捕设备,价格可以接受, 效果也可以接受。
而作者所期待的理想方式,将是惯性动捕+单摄像头视觉识别的结合。
这种软硬结合的体系一方面在成本上可以承担;另一方面,两个独立捕捉系统可以互相参照和校正。以实现更精准的动作捕捉。
AI驱动
动作捕捉的技术越来越完善, 但懒人的境界是无止境的:
能不能连捕捉这一步都省了, 用人工智能来驱动虚拟人的动作?
这一步也有了一些实践,如百度的AI手语主播,就是一个典型的AI驱动动作的虚拟人。
AI驱动的虚拟人对于本系列关注的影视创作有着非常实际的意义:
有了AI驱动的虚拟人,未来的影视表演中,跑龙套的虚拟配角可以通过AI来驱动。
导演只需要重点关注虚拟主角的表演。表演者通过动捕技术把导演所希望表达的肢体动作(当然还有表情和语言)传递到虚拟人角色身上;而打酱油的AI虚拟人群演,只需通过预置指令安排妥当,更进一步甚至只需要借助自然语义理解技术直接解析剧本的用意,就能配合主角虚拟人的表演进行互动。
听起来有那么一点点科幻,不过这里所描述的每个环节并没有特别难啃的硬骨头。
在这里,挑战者提出的质疑,或许并不在于语义指令如何让虚拟人AI理解,进而转为表演的输出——辅以交互式的调教这是一定可以做到的。我们并没有期望AI虚拟人真正懂得表演,而只要求AI在接受了几个关键点的校正后,能和真人动捕的虚拟人进行互动就可以了。
真正的难度或许还是在于,虚拟人的表演是否足够自然,以骗过观众的眼睛?
目前我们看到的虚拟人AI动作驱动,还处于一个比较初级的状态。不过作者乐观地相信,和Metahuman的横空出世类似,只要辅以足够规模的人体动作数据库,实现以假乱真的AI驱动虚拟人动作,也就是早晚的事情。
最后
关于驱动虚拟人的话题,其实还有两个方面没有涉及,一是虚拟人的语音能力,二是虚拟人的表情驱动。
关于前者,在当前类似GPT-3这种有千亿参数规模的大型语言模型的支持下,虚拟人基于AI的文本沟通做到真假难辨是几乎没有难度的。而基于聊天文本到自然语音的生成,也已经有很好的解决方案了。
在其他一些应用场合里,比如打造互动元宇宙时,一个可以自主对话的AI系统是比较重要的;而回到我们的影视创作主题,一个虚拟人是否能自主聊天反而没那么关键。更重要的是虚拟人可以根据剧本做出符合预期的表演(朗读情绪、面部表情、肢体语言等等)。
考虑到最基本的实现,虚拟人的台词和动作可以通过背后表演者来表达,那么核心的问题就剩下一个:我们如何实现以假乱真的虚拟人表情呢?
这里暂且卖个关子,关于人物表情这个影视表演里重要的话题,留在后续第三篇里再回来讨论。

在结束这篇已经超标的长文之前,顺便和大家介绍一下,作者自己亲手打造的MetaHuman虚拟人Jasmine。作为元天空之城在元宇宙里的代表,Jasmine在未来的内容里会有更多的机会和大家见面:)
本文来自微信公众号:元天空之城(ID:gh_a702b8d21cdf),作者:城主