
本文来自微信公众号:半导体行业观察(ID:icbank),作者:畅秋,头图来自:unsplash
近些年,GPU(图形处理器)在业界的重要性愈加凸出,无论是在高性能计算,还是在消费级领域,其对用户的粘性越来越强,英伟达的火爆就是得益于其核心的GPU技术和产品。
在这种情况下,传统巨头英特尔坐不住了,原本只是在消费级市场生产集成GPU显卡,市场需求的变化使得英特尔开始组建独立GPU研发团队,并投入了越来越多的资源,以应对英伟达和AMD的竞争,特别是在高性能计算领域。
在高性能应用领域,对GPU的功耗和成本可控的要求越来越高,这就对相关技术提出了更高的要求,包括芯片设计方法、EDA工具、制程工艺,以及封装技术,要想实现高性能与功耗、成本的有效平衡,以上这些技术环节缺一不可。而随着摩尔定律的逐步“失效”,先进封装技术的重要性越来越凸出,英特尔、AMD和英伟达这三巨头都看到了这一环节的重要性,并不断加强研发力度。特别是在近期,这三家公司不约而同地在MCM(多芯片模块)方面披露了重要信息。
一、MCM打入GPU
MCM是为解决单一芯片集成度低和功能不够完善的问题而生的,它把多个高集成度、高性能、高可靠性的die,在高密度多层互联基板上用SMD技术组成多种多样的电子模块系统,形成多芯片模块。MCM具有以下特点:封装延迟时间缩小,易于实现模块高速化;缩小整机/模块的封装尺寸和重量;系统可靠性大大提高。
以前,MCM主要用于CPU和存储设备,特别是在CPU领域应用较为普遍,如早期IBM的Power4 双核处理器,就是4块双核Power4 以及附加的 L3 高速缓存形成的MCM,还有英特尔的Pentium D(研发代号:Presler)、Xeon,以及AMD的Zen 2架构Ryzen(核心代号:Matisse)、EPYC处理器等,都是应用MCM的典型代表。
近些年,在AMD的引领下,MCM封装技术开始走向GPU。之所以如此,主要是因为传统显卡是带有多个GPU的PCB板卡,需要连接两个独立显卡的Crossfire或SLI桥接器。传统的SLI 和 CrossFire需要 PCIe 总线来交换数据、纹理、同步等。由于GPU之间的渲染时间会产生同步问题,因此在许多情况下,传统的双GPU显卡,即单个PCB上的两个芯片由它互连,每个芯片都有自己的VRAM。SLI或CrossFire的能耗很大,冷却也是一个挑战,这些在很长一段时间内都困扰着工程师。
MCM GPU则是一个单独的封装,其板载桥接器取代了传统两个独立显卡之间的Crossfire或SLI桥接器。
在高性能计算应用领域,这种MCM GPU的优势很明显,也值得花费更多时间和精力在解决封装和互连方面的软件问题,以应对更高的MCM设计复杂度。目前来看,MCM GPU主要用于数据中心和云计算应用领域。随着技术的不断成熟,以及PC应用性能的提升,其在消费电子领域的应用也将会出现。
二、三巨头发力
最早将MCM封装技术引入GPU的是AMD。2020年,该公司把游戏卡与专业卡的GPU架构分家了,游戏卡的架构是RDNA,而专业卡的架构叫做CDNA,首款产品是Instinct MI100系列。2021年,AMD的Q2财报确认CDNA 2 GPU已经向客户发货了,其GPU核心代号是Aldebaran,它成为AMD第一款采用MCM封装的产品,是为数据中心准备的。在PC方面,2022年引入下一代RDNA 3架构后,基于MCM的消费级Radeon GPU也会出现。
制造多芯片计算 GPU 类似于制造多核 MCM CPU,例如Ryzen 5000或Threadripper处理器。首先,将芯片靠得更近可以提高计算效率。AMD 的 Infinity 架构确保了高性能互连,有望使两个芯片的效率接近一个的。其次,使用先进的工艺技术批量生产多个小芯片比大芯片更容易,因为小芯片通常缺陷较少,因此比大芯片的产量更好。
前些天,在2021年财报电话会议上,AMD确认,今年会有几项重要产品发布,包括基于RDNA 3架构的GPU,也就是Radeon RX 7000。目前来看,该系列最新显卡会有三款GPU,分别是Navi 31、Navi 32和Navi 33,其中,Navi 31和Navi 32将采用MCM封装。之前有传闻称,Navi 31和Navi 32的Infinity Cache将采用3D堆栈的设计,会单独添加到MCD小芯片中,与Zen 3架构上采用3D V-Cache的原理类似,性能会有较大提升。
由于Navi 31和Navi 32采用了MCM封装,AMD将会使用两种不同制程,GPU会使用台积电的5nm工艺,缓存I/O芯片则会采用台积电的6nm工艺。
英伟达也在跟进MCM封装GPU。
2017年,英伟达展示了通过四个小芯片构建的设计方案,不但提升了性能,还有助于提高产量(较小的芯片良品率会提高),而且还允许将更多的计算资源集合在一起。这种多芯片设计还有助于提高供电效率,具有更好的散热效果。
近日,英伟达研究人员发表了一篇技术文章,概述了该公司对MCM的探索,英伟达目前在MCM封装GPU上的做法称为“Composable On Package GPU”(COPA),该团队讲述了COPA GPU 的各项优势,尤其是能够适应各种类型的深度学习工作负载。
由于传统融合 GPU 解决方案正迅速变得不太实用,研究人员才想到到 COPA-GPU 的理念。融合GPU解决方案依赖于由传统芯片组成的架构,辅以高带宽内存(HBM)、张量核心/矩阵核心(Matrix Cores)、光线追踪(RT)等专用硬件的结合。
此类硬件或在某些任务下非常合适,但在面对其它情况时却效率低下。与当前将所有特定执行组件和缓存组合到一个包中的单片 GPU 设计不同,COPA-GPU 架构具有混合 / 匹配多个硬件块的能力。如此一来,它就能够更好地适应当今高性能计算只能呈现的动态工作负载、以及深度学习(DL)环境。
这种整合更适应多种类型工作负载的能力,可带来更高水平的 GPU 重用。更重要的是,对于数据科学家们来说,这使他们更有能力利用现有资源,来突破潜在的界限。
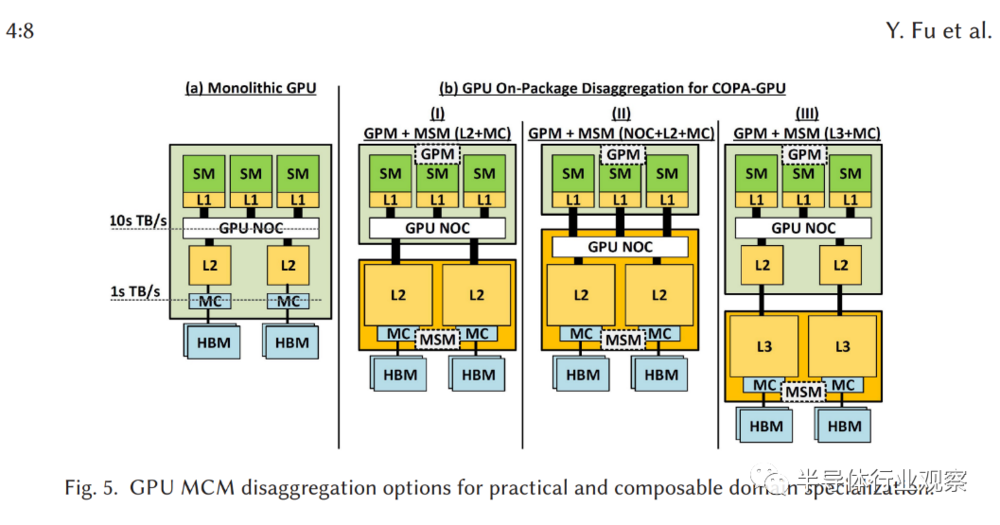
面向数据中心和消费市场,英伟达将分别推出基于Hopper架构和Ada Lovelace架构的GPU。据悉,该公司只会在Hopper架构GPU上采用MCM技术,Ada Lovelace架构GPU仍会保留传统的封装设计,并不会像AMD基于RDNA 3架构的Navi 31那样,将MCM多芯片封装引入到消费级GPU。
近日,有消息称,基于Hopper架构的GH100的晶体管数量将达到1400亿,这几乎是目前基于Ampere架构的GA100(542亿)或AMD基于CDNA 2架构的Instinct MI200系列(580亿)的2.5倍。据称GH100的芯片尺寸接近900mm²,比此前传言的1000mm²要小,不过比GA100(862mm²)和Instinct MI200系列(约790mm²)要大一些。传闻GH100总共配置了288个SM,可以提供三倍于A100计算卡的性能。
据悉,作为英伟达第一款基于MCM技术的GPU,Hopper架构产品将采用台积电5nm制程工艺,支持HBM2e和其他连接特性,预计会在2022年中旬亮相,竞争对手将是英特尔的Xe-HP架构GPU和AMD的CDNA 2架构产品。
不过,以上说法还未得到官方证实,英伟达将于今年3月21日召开GTC 2022大会,届时,可能会公布Hopper架构,以及相应的加速卡方案。
作为独立GPU的后来者,英特尔最近也是动作频频。
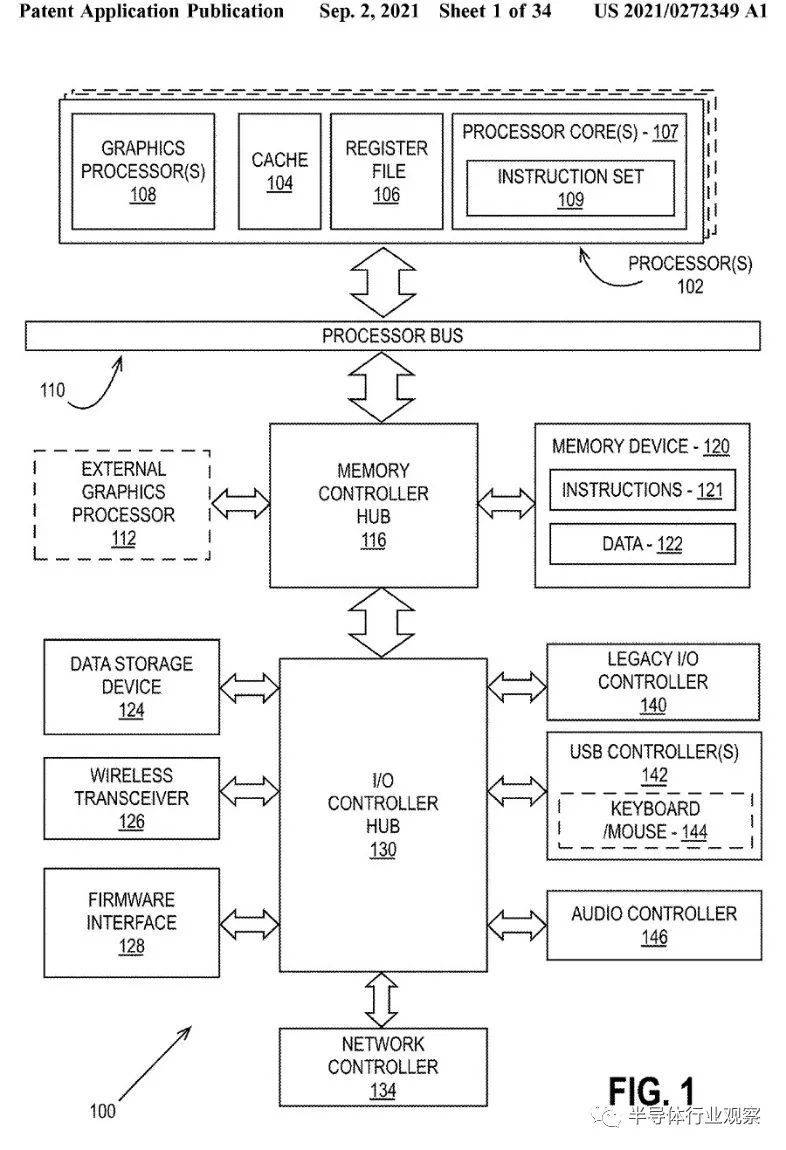
近期,英特尔公布新专利,描述多个计算模组如何协同工作执行图像渲染,代表英特尔GPU将采用MCM封装技术,大幅提高运作效能。
英特尔针对数据中心和超级计算机Ponte Vecchio的CPU已使用多芯片设计,并采用MCM封装技术。在新专利中,英特尔提出GPU图像渲染解决方案,将多芯片整合至同单元,解决制造和功耗等问题,同时优化可扩展性和互联性。
目前,这类图像渲染问题会通过交替渲染技术(Alternate Frame Rendering,AFR)或拆分帧渲染(Scissor Frame Rendering,SFR)等算法解决,但英特尔是整合运算模组的棋盘格式渲染,同时有分布式运算,使多芯片设计GPU有更高运算效率。虽然英特尔没有多描述架构层面细节,但可预期Intel Arc品牌显卡搭载MCM封装技术GPU应只是时间问题。
三、结语
在GPU研发方面,英特尔、AMD和英伟达显得越来越“同步”,特别是在制程工艺和封装技术方面,制程都依赖台积电,封装都看重MCM,在这两方面原本领先的AMD,其优势越来越小,特别是在MCM方面,英伟达和英特尔发展速度很快,不仅是在高性能计算领域,在消费级市场,虽说AMD首先将MCM技术应用于PC,但英伟达和英特尔也在加快进度,相信不久也会有相应的方案推出。
MCM封装GPU开始进入三国鼎立时代。
本文来自微信公众号:半导体行业观察(ID:icbank),作者:畅秋