
本文来自微信公众号:半导体行业观察(ID:icbank),作者:李飞,头图来自:视觉中国
最近,人工智能领域权威跑分榜单MLPerf更新了1.1版,主要针对云端和边缘端的推理性能。
MLPerf是由ML Commons推出的性能测试榜单。在人工智能技术发展迅速的今天,不同的针对人工智能加速的芯片也是层出不穷,于是如何能有一个较好的标准跑分(benchmark)平台就很重要,有了这样的平台,用户才能以较为公平和合理的方式去比较不同芯片的人工智能性能。
具体来说,MLPerf对于不同的测试组别(训练、服务器推理、终端推理等)提供了一系列标准的测试网络,并且由各个硬件公司上传可验证的跑分结果,这些结果在经过验证后,就由ML Commons总结整理并上传到MLPerf的榜单上。
这次公布的MLPerf 1.1榜单中,基本可以分为几大势力:首先,是以Nvidia的GPU为核心加速卡的方案,由各种不同的厂商(包括Nvidia自己,以及超微、联想、戴尔、HP等整机厂商)实现的整机去跑分;其次是高通的云端加速卡方案,由高通自己提交跑分结果;第三类是Intel的CPU方案;第四类则是一些初创公司的方案。
因此,在MLPerf 1.1的结果中,我们认为最值得关注的,就是高通与Nvidia之间的竞争。事实上,在一些测评项目中,高通的方案已经实现了比Nvidia更高的结果,这也说明在服务器推理市场,Nvidia遇到了一个强力的竞争对手,未来无法再高枕无忧。
MLPerf:高通与Nvidia的竞争
目前,Nvidia这一代的主要人工智能加速方案包括A100和A30。其中,A100是Nvidia的旗舰级GPU,同时针对推理和训练市场,算力高达600 TOPS (INT8精度),其功耗则根据使用内存的区别从250W-400W不等。
另一方面,A30则是Nvidia主要针对推理市场的GPU产品,其INT8峰值算力可达330 TOPS,约为A100的一半,而Nvidia在其官方资料中称A30在运行机器学习算法时的实际性能约为A100的三分之二。功耗方面,A30的最大功耗约为165W。
在高通方面,Cloud AI 100芯片于今年上半年正式发货,其INT8最大算力可达400 TOPS,最大功耗(PCIe版本)则75W。根据高通公布的资料,其设计采用了多核架构,每个AI Core上拥有8MB的SRAM,最多在芯片上可以集成16个AI Core,并且这些AI Core会共享LPDDR4X DRAM,以及PCIe接口。
值得注意的是,高通的Cloud AI 100并没有像Nvidia一样使用HBM2内存接口,而是使用了功耗和带宽都更低的LPDDR4X接口,这意味着高通需要能更好地管理内存才能摆脱其在内存带宽方面的劣势。

在MLPerf 1.1中,高通的表现可圈可点。在推理分类下的各项目中,高通提交了ResNet 50(用于图像分类),SSD(用于物体检测)以及BERT(用于自然语言处理任务)的结果。在ResNet 50的结果中,高通装有16块75W Cloud AI 100 加速卡的主机可以实现每秒342011次推理,而Nvidia提交的DGX主机结果中(包含8块400W的A100 GPU),ResNet 50的推理吞吐量为每秒313516次推理,因此高通不仅推理吞吐量比Nvidia的旗舰GPU A100结果高了10%,而且总功耗仅为Nvidia方案的三分之一左右。在和Nvidia A30的对比中,高通的Cloud AI 100同样可以以A30一半左右的功耗实现比A30高10%左右的ResNet 50推理吞吐量。
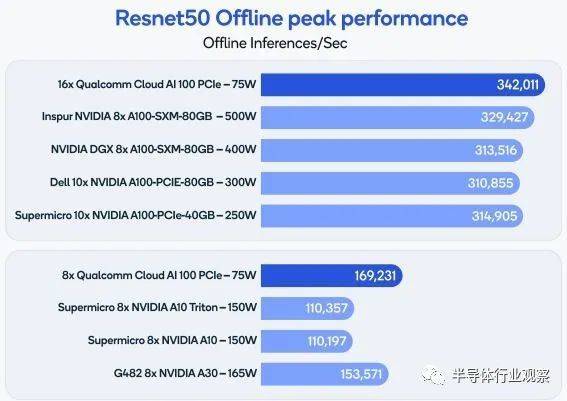
另一方面,在目标检测SSD方面,高通16X Cloud AI 100的性能则比Nvidia 8X A100低了10%左右。而在自然语言BERT项目中,高通16X Cloud AI 100的性能则大约是Nvidia 8X A100的一半。这些结果表明,在主流机器视觉任务中,高通的16X Cloud AI 100已经能实现和Nvidia 8X A100基本相同甚至更好的性能,而在BERT等自然语言处理任务中,Cloud AI 100则仍然距离A100有相当的差距。
这其实从高通Cloud AI 100的设计中也可以看出端倪,它使用8MB每核心的片上内存搭配LPDDR4X内存接口,在模型较小的机器视觉任务(例如ResNet-50和SSD)中已经够用,内存不会成为其瓶颈;然而对于模型较大的自然语言处理模型如BERT中,LPDDR4X接口仍然成为了高通AI Cloud 100的瓶颈,而使用HBM2系列接口的Nvidia A100则有优势。
推理市场中,高通对Nvidia会造成威胁吗
如前所述,高通的Cloud AI 100在机器视觉任务中都能以更低的功耗实现和Nvidia A100方案接近,或比A30更高的性能。虽然Cloud AI 100在自然语言处理方面离Nvidia A100方案的性能有一些差距(能效比上仍然是Cloud AI 100更好),但是目前在推理方面,事实上机器视觉已经是一块巨大的市场,因此高通在这个领域有可能会成为强而有力的竞争者。
如果我们细数机器视觉领域对于推理性能有较强需求的领域,首当其冲的可能就是自动和辅助驾驶领域。在自动和辅助驾驶领域,需要大量的目标检测,这就需要大量的机器视觉算力支持。高通的Cloud AI 100拥有更好的能效比和相当的性能,加上其成本预计会远远低于基于HBM2内存的A100 GPU,因此可能会与Nvidia在这个领域有激烈的竞争。自动驾驶领域拥有较高的质控和渠道壁垒,而高通作为在半导体供应链中已经有非常深厚积累的巨头,在这个领域显然要比其他做自动驾驶芯片的初创公司更有竞争力,因此可能会给这个领域带来新的市场格局。
当然,在自动驾驶领域高通即使能战胜Nvidia,也不代表高通能占领整个自动驾驶市场:随着目前各大智能驾驶公司都纷纷开始自研芯片,未来自动驾驶市场中究竟是第三方芯片方案还是第一方芯片方案更是主流,仍然有待观察。
除了智能驾驶之外,另一个重要的推理市场是智能终端,例如工业机器人和智能摄像头。这些领域对于功耗和能效比都有较强的需求。高通显然在设计芯片的时候将这些市场纳入了考虑,因此Cloud AI 100除了功耗75W,400TOPS算力的PCIe版本之外,还有功耗15W,算力70TOPS和功耗25W,算力200 TOPS的低功耗版本,这些版本非常适合工业机器人和智能摄像头应用。而Nvidia同样针对该市场的Xavier系列芯片的能效比则远逊于Cloud AI 100,因此高通在这个领域也有优势。
当然,高通即使能在竞争中胜过Nvidia,也未必能真正主导这个市场。人工智能推理的一大市场,即中国市场,在国际形势和国内对于半导体产业大力扶持的背景下,究竟会使用外国公司的方案,还是使用国内公司的方案,对于高通究竟能在这个市场中占有多大份额也有很大影响。
训练市场如何战胜Nvidia
在人工智能训练市场,从MLPerf早些公布的训练跑分结果我们可以看到,Nvidia的单卡性能仍然远远领先Graphcore,Habana等竞争对手。另外,高通似乎目前尚没有公布在这个领域的计划。然而,在分布式训练结果中,我们可以看到Nvidia的训练跑分结果和谷歌的TPU类似。分布式训练结果主要考虑如何通过大规模的分布式计算来实现训练速度的提升,它一个系统工程,需要软件、网络通讯和加速卡芯片的协同设计才能实现最佳性能。虽然Nvidia的单卡性能仍然很强,但是在训练领域,分布式训练性能事实上甚至比单卡性能更有意义,因此需要很强的系统工程能力才能实现超越。
当然,从另一个角度来说,由于这是一个系统工程,因此如果公司在系统中的其他组件有优势的话,可以弥补芯片方面的短板。例如,谷歌的芯片部门虽然成立时间远少于Nvidia,但是凭借其在系统工程领域的深厚积累,可以在分布式训练领域实现和Nvidia接近的结果。
此外,来自北大和鹏城实验室基于华为Kunpeng CPU+Ascend加速卡+mindspore软件框架的分布式训练结果也值得肯定,在自然语言处理领域,BERT训练结果的跑分华为Ascend 128卡的结果与介于64卡Nvidia A100和64卡TPU之间,而在机器视觉领域,Ascend 1024卡的结果与A100 1024卡的结果接近。因此,在可使用的芯片工艺受到限制的情况下,中国芯片公司考虑从系统工程的角度(例如,通过与该领域有深厚积累的各大IT公司合作)来实现对于Nvidia GPU在训练领域的赶超或许是一个可行的思路。
本文来自微信公众号:半导体行业观察(ID:icbank),作者:李飞