
本文来自微信公众号:智源社区(ID:BAAIHub),作者:黄铁军(智源研究院院长、北京大学教授),本文为黄铁军教授为2018年图灵奖获得者、“卷积神经网络之父”Yann LeCun的自传——《科学之路》所作序言,头图来自:视觉中国
杨立昆是当今世界顶尖的人工智能专家,为他的新书作序,颇具挑战性。好在众多专家已在人工智能领域探索了近70年,本序希望通过反思已走过路径的合理性及局限性,探索人工智能的未来发展方向,从而对本书略做补充。
先谈一下对智能的看法。智能是系统通过获取和加工信息而获得的能力。智能系统的重要特征是能够从无序到有序(熵减)、从简单到复杂演化(进化)的。生命系统是智能系统,也是物理系统;既具有熵减的智能特征,也遵守熵增在内的物理规律。人工智能是智能系统,也是通过获取和加工信息而获得智能,只是智能载体从有机体扩展到一般性的机器。
就像人可以分为精神和肉体两个层次(当然这两个层次从根本上密不可分),机器智能也可以分为载体(具有特定结构的机器)和智能(作为一种现象的功能)两个层次,两个层次同样重要。因此,我偏好用机器智能这个概念替代人工智能。
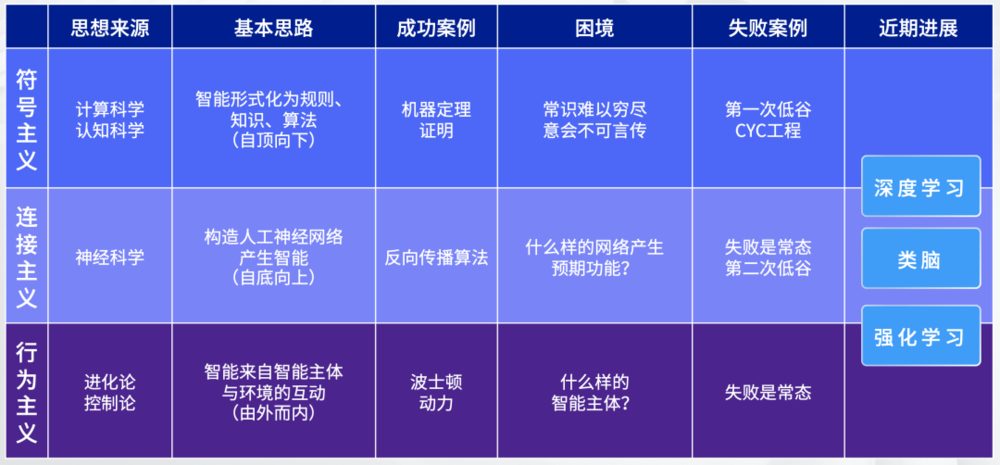 AI 技术途径概述
AI 技术途径概述
一、经典技术途径
1. 符号主义
与机器智能相比,人工智能这个概念的重心在智能。“人工”二字高高在上的特权感主导了人工智能研究的前半叶,集中体现为符号主义。
符号主义主张(由人)将智能形式化为符号、知识、规则和算法,认为符号是智能的基本元素,智能是符号的表征和运算过程。符号主义的思想起源是数理逻辑、心理学和认知科学,并随着计算机的发明而步入实践。
符号主义有过辉煌,但不能从根本上解决智能问题,一个重要原因是“纸上得来终觉浅”:人类抽象出的符号,源头是身体对物理世界的感知,人类能够通过符号进行交流,是因为人类拥有类似的身体。
计算机只处理符号,就不可能有类人感知和类人智能,人类可意会而不能言传的“潜智能”,不必或不能形式化为符号,更是计算机不能触及的。要实现类人乃至超人智能,就不能仅仅依靠计算机。
2. 连接主义
与符号主义自顶向下的路线针锋相对的是连接主义。
连接主义采取自底向上的路线,强调智能活动是由大量简单单元通过复杂连接后并行运行的结果,基本思想是:既然生物智能是由神经网络产生的,那就通过人工方式构造神经网络,再训练人工神经网络产生智能。
人工神经网络研究在现代计算机发明之前就开始了,1943年,沃伦·麦卡洛克(Warren McCulloch)和沃尔特·皮茨(Walter Pitts)提出的M-P神经元模型沿用至今。
连接主义的困难在于,他们并不知道什么样的网络能够产生预期智能,因此大量探索归于失败。20世纪80年代神经网络曾经兴盛一时,掀起本轮人工智能浪潮的深度神经网络只是少见的成功个案,不过这也是技术探索的常态。
3. 行为主义
人工智能的第三条路线是行为主义,又称进化主义,思想来源是进化论和控制论。
生物智能是自然进化的产物,生物通过与环境以及其他生物之间的相互作用发展出越来越强的智能,人工智能也可以沿这个途径发展。
这个学派在20世纪80年代末90年代初兴起,近年来颇受瞩目的波士顿动力公司的机器狗和机器人就是这个学派的代表作。行为主义的一个分支方向是具身智能,强调身体对智能形成和发展的重要性。
行为主义遇到的困难和连接主义类似,那就是什么样的智能主体才是“可塑之才”。
二、路径演进
机器学习从20世纪80年代中期开始引领人工智能发展潮流,本书给出了很通俗的定义:学习就是逐步减少系统误差的过程,机器学习就是机器进行尝试、犯错以及自我调整等操作。
机器学习对人工智能最重要的贡献是把研究重心从人工赋予机器智能转移到机器自行习得智能。近年来,最成功的机器学习方法是深度学习和强化学习。
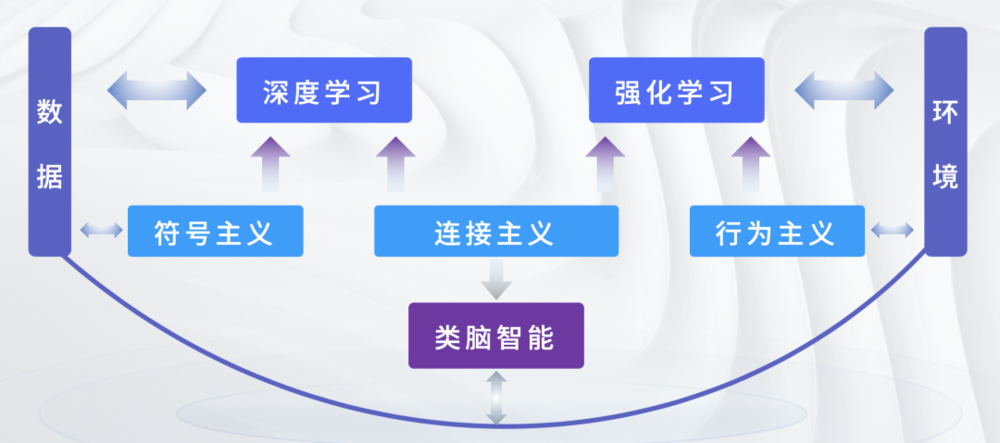
深度学习是连接主义和机器学习相结合的产物,最大的贡献是找到了一种在多层神经网络上进行机器学习的方法,本书作者杨立昆和约书亚·本吉奥、杰弗里·辛顿因此获得2018年度图灵奖。
深度学习首先回答了什么样的神经网络可以训练出智能,包括多层神经网络和卷积神经网络,也回答了训练(学习)方法问题,包括受限玻尔兹曼机模型、反向传播算法、自编码模型等。
深度学习对连接主义的重大意义是给出了一条训练智能的可行途径,对机器学习的重大意义则是给出了一个凝聚学习成效的可塑载体。
强化学习的思想和行为主义一脉相承,可追溯到1911年行为心理学的效用法则:给定情境下,得到奖励的行为会被强化,而受到惩罚的行为会被弱化,这就是强化学习的核心机制——试错。
1989年,沃特金斯提出Q学习(Q-learning),证明了强化学习的收敛性。2013年,谷歌子公司DeepMind将Q学习和深度神经网络相结合,取得AlphaGo、AlphaZero(阿尔法元)和AlphaStar等重大突破。最近,DeepMind更是强调,只需要强化学习,就能实现通用人工智能。
与DeepMind极力推崇强化学习不同,杨立昆认为强化学习不过是锦上添花,传统监督学习标注成本高,泛化能力有限,也只是点缀,自监督学习才是机器学习的未来。自监督学习是通过观察发现世界内在结构的过程,是人类(以及动物)最主要的学习形式,是“智力的本质”,这就是本书第九章的核心观点。最近,杨立昆和另外两位图灵奖获得者发表的论文“Deep Learning for AI”(《面向人工智能的深度学习》)中,也重点谈了这个观点。
有了三位图灵奖获得者的大力倡导,相信自监督学习将会掀起一波新的研究浪潮,但我不认为这就是“智力的本质”。根本原因在于,这只是从机器学习层次看问题,或者更一般地说,是从功能层次看问题。我认为,学习方法(功能)固然重要,从事学习的机器(结构)同样重要,甚至更重要,因为结构决定功能。正如我开始时强调过的,永远不要忘记作为智能载体的机器。
杨立昆在第九章开篇提到了法国航空先驱克莱芒·阿代尔(Clément Ader),他比莱特兄弟早13年造出了能飞起来的载人机器。杨立昆从这位先驱身上看到的主要是教训:
“我们尝试复制生物学机制的前提是理解自然机制的本质,因为在不了解生物学原理的情况下进行复制必然导致惨败。”
他的立场也很清楚:
“我认为,我们必须探究智能和学习的基础原理,不管这些原理是以生物学的形式还是以电子的形式存在。正如空气动力学解释了飞机、鸟类、蝙蝠和昆虫的飞行原理,热力学解释了热机和生化过程中的能量转换一样,智能理论也必须考虑到各种形式的智能。”
我的看法和他不同,我认为克莱芒·阿代尔(和莱特兄弟)不仅没有“惨败”,而且取得了伟大的成功。
原因很简单:克莱芒·阿代尔1890年和莱特兄弟1903年分别发明飞机,而空气动力学是1939—1946年才建立起来的。两次世界大战中发挥重大作用的飞机,主要贡献来自克莱芒·阿代尔和莱特兄弟的工程实践,而不是空气动力学理论的贡献,因为空气动力学还没出现。
另一个基本事实是,至今空气动力学也没能全面解释飞机飞行的所有秘密,更没有全面解释各种动物的飞行原理。
空气动力学很伟大,但它是“事后诸葛亮”,对于优化后来的飞机设计意义重大,但它不是指导飞机发明的理论导师。
智能比飞行要复杂得多,深度学习成功实现了智能,但是能够解释这种成功的理论还没出现,我们并不能因此否定深度学习的伟大意义。杨立昆和另外两位图灵奖获得者的伟大,和克莱芒·阿代尔及莱特兄弟之伟大的性质相同。
我们当然要追求智能理论,但是不能迷恋智能理论,更不能把智能理论当作人工智能发展的前提。如果这里的智能理论还试图涵盖包括人类智能在内的“各种形式的智能”,则这种理论很可能超出了人类智能可理解的范围。
所以,尽管自监督学习是值得探索的一个重要方向,它也只是探索“智力的本质”漫漫长途中的一个阶段。人类和很多动物具有自监督学习能力,并不是自监督学习多神奇,而是因为他(它)们拥有一颗可以自监督学习的大脑,这才是智力的本质所在。
机器要进行自监督学习,也要有自己的大脑,至少要有深度神经网络那样的可塑载体,否则自监督学习无从发生。相比之下,强化学习的要求简单得多,一个对温度敏感的有机大分子就能进行强化学习,这正是生命和智能出现的原因。所以,强化学习才是更基本的学习方法。
当然,从零开始强化学习,确实简单粗暴、浪费巨大,这也是强化学习思想提出百年并没取得太大进展的重要原因。
强化学习近十年来突然加速,是因为有了深度神经网络作为训练的结构基础,因而在围棋、《星际争霸》等游戏中超越人类。不过,人类输得并不心甘情愿,抱怨的主要理由是机器消耗的能源远高于人类大脑。
我认为这种抱怨是片面的,人类棋手大脑的功耗确实只有数十瓦,但训练一个人类棋手要花费十多年时间。更重要的是,人类棋手学围棋时是带着大脑这个先天基础的,这颗大脑是亿万年进化来的,消耗了巨大的太阳能,这都应该记到能耗的总账中。这样比较,到底是机器棋手还是人类棋手能耗更大呢?
从节省能源角度看,机器智能确实不应该从头再进化一次,而是应该以进化训练好的生物神经网络为基础,这就是纯粹的连接主义:构造一个逼近生物神经网络的人工神经网络。
1950年,图灵的开辟性论文《计算机与智能》中就表达了这个观点:
“真正的智能机器必须具有学习能力,制造这种机器的方法是:先制造一个模拟童年大脑的机器,再教育训练它。”
这也是类脑智能或神经形态计算的基本出发点。相关科研实践开始于20世纪80年代,基本理念就是构造逼近生物神经网络的神经形态光电系统,再通过训练与交互,实现更强的人工智能乃至强人工智能。
除了改进训练对象的先天结构,训练不可或缺的另一个要素是环境。环境才是智能的真正来源,不同环境孕育不同智能。
人们往往把今天人工智能系统的成功归结为三个要素:大数据+大算力+强算法,其中数据是根本,另外两个要素主要影响效率。
训练更强智能,需要更大数据,这是智能发展的基本规律。有人提出“小数据”方法和小样本学习,标榜要颠覆大数据方法,给出的典型理由是人类和动物能够举一反三,不需要大数据。
这种观点貌似有道理,其实言过其实,因为他们忘记或者故意隐瞒了实现举一反三的主体是大脑,而大脑本身是“进化大数据”训练的结果。
所谓小数据方法,是以大数据“预训练”为前提的。仅靠小数据不可能训练出复杂智能,道理很简单——小数据没有蕴含足够的可能性和复杂性,所谓的强大智能又从何而来呢?
但即便是大数据,也不能完整有效地表达环境,数字孪生能更全面地刻画物理环境,更好地保留环境自有的时空关系,因此也能够哺育出更强的人工智能。物理世界的模型化本来就是科学最核心的任务,以前从中发现规律的是人类,未来这个发现主体将扩展到机器。
三、未来路径
行文至此,我们已经从人工智能发展史中小心翼翼地挑出三根靠得住的基本支柱:一是神经网络,二是强化学习,三是环境模型。
在这三根支柱中,杨立昆最突出的贡献是对神经网络的贡献,特别是卷积神经网络。至于想到用卷积神经网络,是因为借鉴了生物神经感知系统,这就是卷积神经网络在图像识别和语音识别等领域大获成功的主要原因——深度神经网络已经借鉴了生物神经网络的部分结构。
总而言之,人工智能经典学派有三个:符号主义、连接主义和行为主义。符号描述和逻辑推理不是智能的基础,而是一种表现,读写都不会的文盲就拥有的“低级”智能才更基础。因此,连接主义和行为主义虽然困难重重,但有着更强的生命力,从中发展出的深度学习和强化学习两套方法,成为当今支撑人工智能的两大主要方法。
展望未来,人工智能的发展途径有三条。
一是继续推进“大数据+大算力+强算法”的信息技术方法,收集尽可能多的数据,采用深度学习、注意力模型等算法,将大数据中蕴藏的规律转换为人工神经网络的参数,这实际上是凝练了大数据精华的“隐式知识库”,可以为各类文本、图像等信息处理应用提供共性智能模型。

二是推进“结构仿脑、功能类脑、性能超脑”的类脑途径,把大自然亿万年进化训练出的生物神经网络作为新一代人工神经网络的蓝本,构造逼近生物神经网络的神经形态芯片和系统,站在人类智能肩膀上发展机器智能。

第三条技术路线的核心是建立自然环境的物理模型,通过强化学习训练自主智能模型。比如,构造地球物理模型,训练出的人工智能系统能够适应地球环境,与人类共处共融;构造高精度物理模型(例如基于量子力学模型构造出粒子、原子、分子和材料模型),可以训练出能够从事物理学和材料学研究的人工智能;构造出宇宙及其他星球的物理模型,可以训练出的人工智能则有望走出地球,适应宇宙中更复杂的环境。

人类智能是地球环境培育出的最美丽的花朵,我们在为自己骄傲的同时,也要警惕人类中心主义。地球不是宇宙的中心,人类智能也没有类似的独特地位,把人类智能视为人工智能的造物主,曾经禁锢了人工智能的发展。沉迷于寻求通用智能理论,将是阻碍人工智能发展的最大障碍。
破除人类中心主义的傲慢和对通用智能理论的迷思,构建更好的人工神经网络(包括逼近生物神经网络),坚持和发展强化学习基本思想,不断提高环境模型的精度和广度,人工智能将稳步前行,前景无限。
本文来自微信公众号:智源社区(ID:BAAIHub),作者:黄铁军