
本文来自微信公众号:半导体行业观察(ID:icbank),作者:穆梓,原文标题:《英特尔最新路线图:4nm、3nm、20A和18A》,题图来自:视觉中国
自Pat Gelsinger回归并就任Intel CEO之后,这家芯片巨头便走上了快车道,并多线快下,力争领先。
在近日举办的Intel Accelerated大会上,Pat Gelsinge和他所领导的技术团队不但分享了公司在工艺上的路线图,同时还谈到了公司在封装、晶圆代工,甚至还有公司在EUV工艺上的规划。
现在,我们综合Intel领导层所讲的一些内容,以及外媒报道的一些精华,以飨读者。
一、工艺路线图:Intel 4、Intel 3、20A和18A
正如Pat Gelsinger在演讲中所说,最初,制程工艺“节点”的名称与晶体管的栅极长度相对应,并以微米为度量单位。随着晶体管越变越小,栅极的长度越来越微缩,我们开始以纳米为度量单位。
他接着说,在过去多年的发展中,英特尔在工艺制程上面有过很多的贡献。例如在1997年,英特尔推出了应变硅(strained silicon)技术,在加上其他技术方面的创新,进而持续缩小晶体管,让它们更快、更便宜和更高能效也变得同样重要。
“从这时开始,传统命名方法不再与实际的晶体管的栅极长度相匹配。”Pat Gelsinger强调。
来到2011年,在英特尔也率先推出FinFET技术。这是一种构建晶体管的全新方式,具有独特的形状和结构。正是得益于这种创新性的技术,摩尔定律继续生效,但Pat Gelsinger却表示,伴随着这种技术的出现,行业进一步分化。
在Pat Gelsinger看来,包括英特尔在内整个行业使用着各不相同的制程节点命名和编号方案,这些多样的方案既不再指代任何具体的度量方法,也无法全面展现该如何实现能效和性能的最佳平衡。
“为此,英特尔想要更新自己的命名体系,以创建一个清晰、一致和有意义的框架,来帮助我们的客户对整个行业的制程节点演进有更准确的认知,进而做出更明智的决策。”Pat Gelsinger强调。
基于这个思路,继去年推出英特尔有史以来最为强大的单节点内性能增强的10纳米SuperFin节点后,英特尔又推出了下一个节点——我们之前称它为Enhanced SuperFin——现在更名为Intel 7、紧随其后的是Intel 4和Intel 3。继Intel 3之后的那个节点,英特尔将其命名为20A,而不是大家以为的Intel 1。
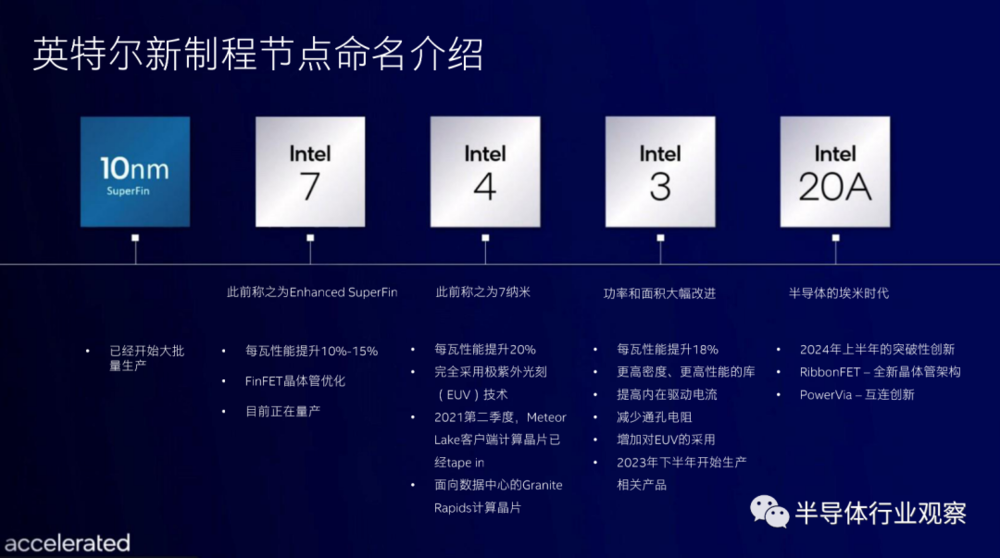
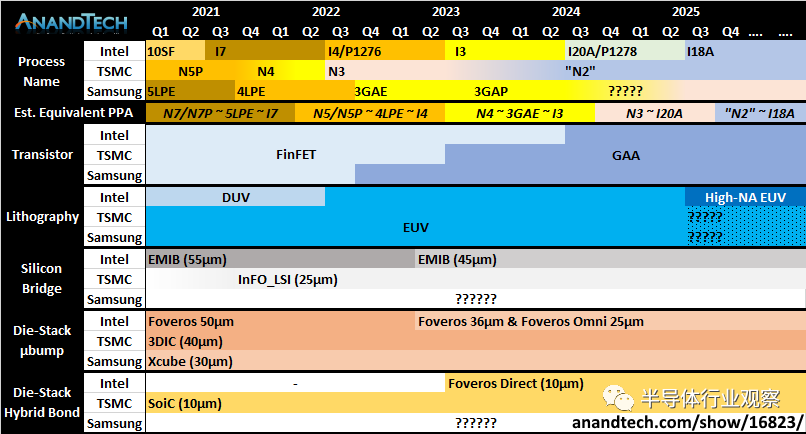
而据外媒anandtech的报道,英特尔在工艺方面也继承了过往的一些传统。如下图所示,英特尔对用于生产(production)和进入零售(retail)之间是有区别的;英特尔将某些技术称为“准备就绪”(being ready),而其他技术则称为“加速”(ramping),因此这个时间表只是提到的那些日期。正如你想象的那样,每个工艺节点都可能存在数年,此图只是展示了英特尔在任何给定时间的领先技术。
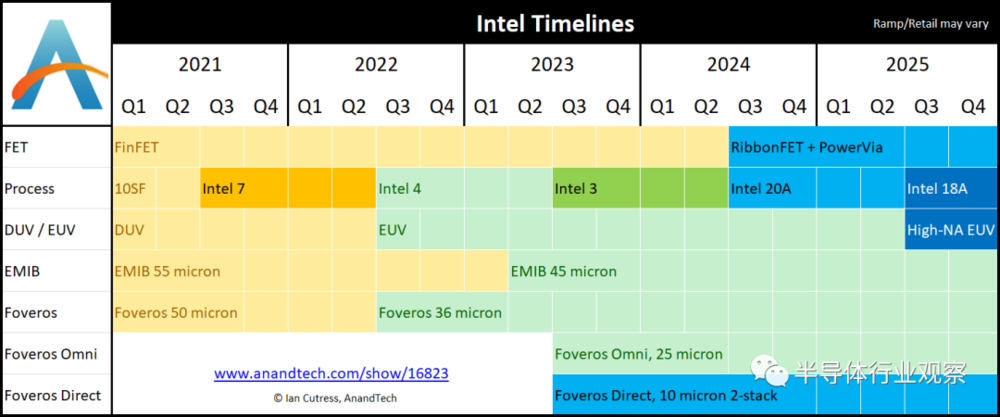
综合可见,英特尔的详细规划和时间如下所示:
2020年,10nm SuperFin(10SF):该工艺已经实现大批量生产,基于该工艺制造的Tiger Lake和英特尔 Xe-LP独立显卡解决方案(SG1、DG1)已经推出;
2021 H2,Intel 7:这个节点以前称为10nm Enhanced Super Fin或10ESF。Alder Lake(正在批量生产)和Sapphire Rapids都属于这一代工艺的产品,由于晶体管优化,这代工艺的每瓦性能比10SF 提高10%~15%。此外,英特尔的Xe-HP现在将被称为Intel 7。
2022 H2,Intel 4:这个节点在以前称为Intel 7nm。英特尔今年早些时候表示,其Meteor Lake处理器将使用基于该工艺节点技术的计算块,现在该芯片已返回实验室进行测试。英特尔预计,在这个节点下,芯片每瓦性能比上一代提高20%,并且该技术使用更多EUV,主要用于BEOL。英特尔的下一个至强可扩展产品Granite Rapids也将使用Intel 4进行生产。需要强调一下,Intel 4是英特尔首个完全采用极紫外光刻(EUV)技术的制程节点;
2023 H2,Intel 3:以前称为英特尔7+。增加EUV和新高密度库的使用。这就是英特尔的战略变得更加模块化的地方——Intel 3将共享Intel 4的一些特性,但有新的高性能库。英特尔预计2023年下半年该工艺节点的制造量将增加,其每瓦性能比Intel 4提高18%。
2024 年,Intel 20A:以前称为Intel 5nm。但新的路线图转向两位数命名,A代表Ångström,或10A 等于1nm。关于这个节点有很少细节,但在这个节点,英特尔将从FinFET转向其称为RibbonFET的 Gate-All-Around(GAA)晶体管。此外,英特尔还将推出一种新的PowerVia技术。
2025年,Intel 18A:这在上图中未列出,但Intel预计2025年会有18A工艺。18A将使用ASML最新的EUV机器,称为High-NA机器,能够进行更精确的光刻。英特尔表示,它是ASML在High-NA方面的主要合作伙伴,并准备接收第一款High-NA机器。ASML最近宣布High-NA机器被推迟——当被问及这是否是一个问题时,英特尔表示不会。
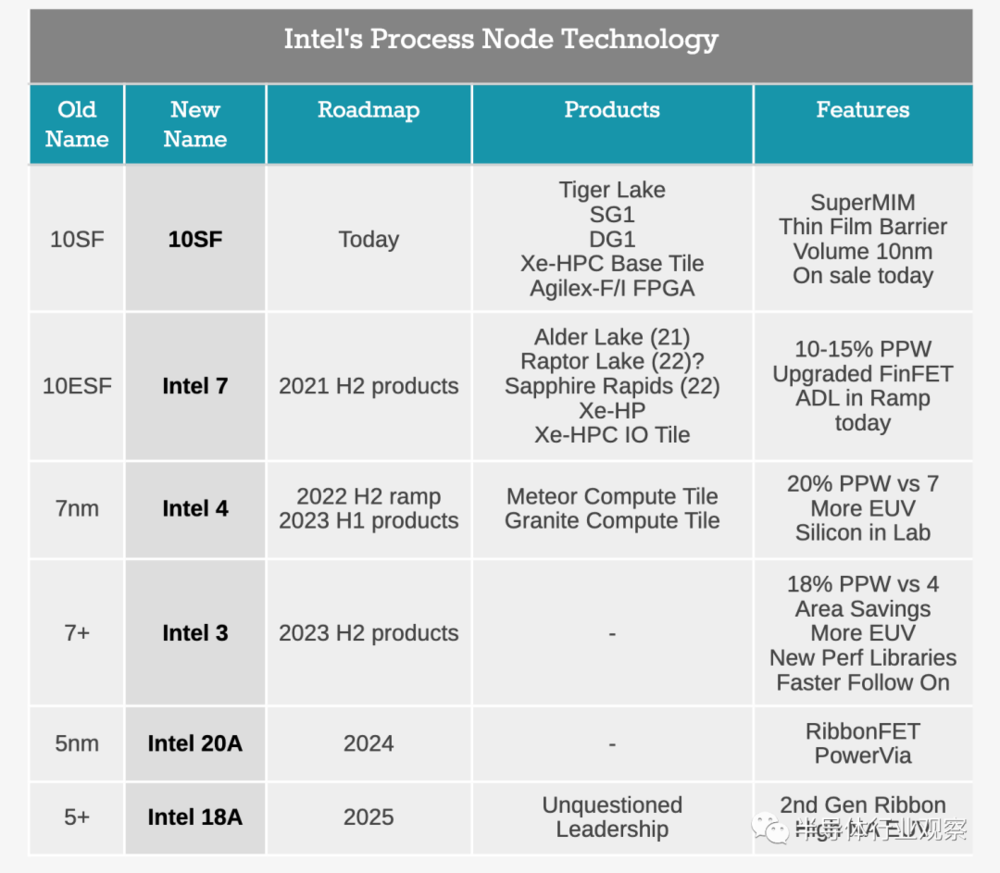
在谈到英特尔为何重新命名节点的时候,anandtech强调,当中的一个要素是他们要与其他代工厂产品匹配。英特尔的竞争对手台积电和三星都使用较小的数字来比较类似的密度工艺。随着英特尔现在更名,他们与行业更加一致。话虽如此,anandtech暗示,英特尔的4nm可能与台积电的5nm相提并论,但这将取决于英特尔与台积电的发布时间表是否相匹配。
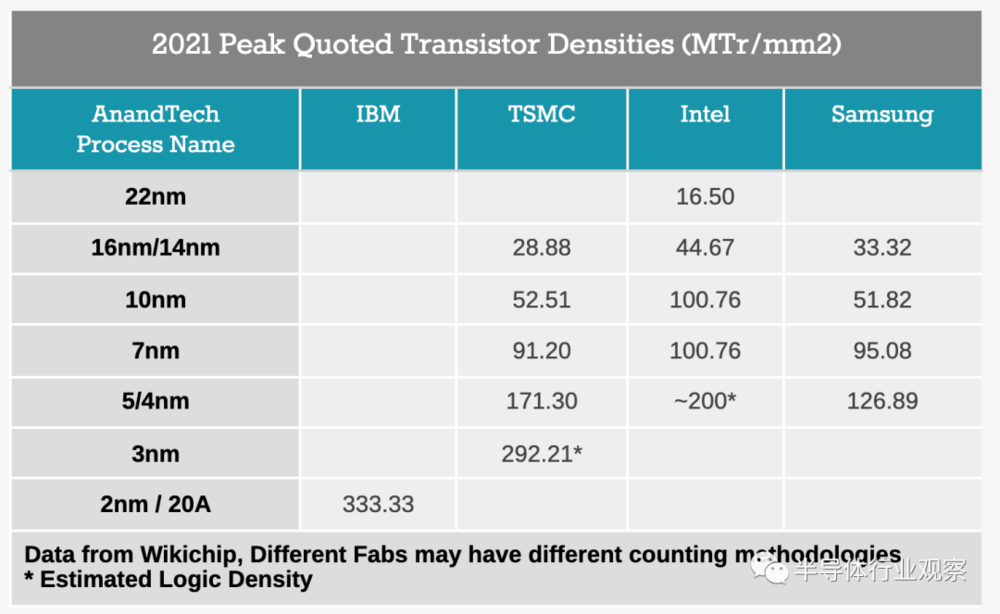
需要注意的一个关键点是,新的Intel 7节点(以前称为 10ESF 节点)不一定是我们通常理解的“完整”节点更新。该节点是作为10SF的更新派生而来的,如上图所示,将具有“晶体管优化”。从10nm到10SF,这意味着SuperMIM和新的thin film设计提供了额外的1 GHz+,但是从10SF到新的Intel 7的确切细节目前尚不清楚。然而,英特尔表示,从Intel 7迁移到Intel 4将是一个常规的全节点跳跃,Intel 3 使用Intel 4的模块化部分以及新的高性能库和芯片改进,以实现性能的另一次跳跃。
在询问英特尔这些工艺节点是否会有额外的优化点时,英特尔回应道,它们中的任何一个是否会被明确地产品化将取决于特性。个别优化可能会额外增加5%~10%的每瓦性能,我们被告知,即使10SF(保留其名称)也有几个额外的优化点,但不一定公开。因此,这些更新是否以7+或7SF或4HP的形式销售尚不清楚。
“最后这个命名(20A)反映了摩尔定律仍在持续生效。随着越来越接近‘1纳米’节点,我们将采用更能反映新时代的命名,即在原子水平上制造器件和材料的时代——半导体的埃米时代。”Pat Gelsinger说。他进一步指出,对于未来十年走向超越“1纳米”节点的创新,英特尔有着一条清晰的路径。
在Pat Gelsinger看来,在穷尽元素周期表之前,摩尔定律都不会失效,英特尔将持续利用硅的神奇力量不断推进创新。“英特尔的最新命名体系,是基于我们客户看重的关键技术参数而提出的,即性能、功率和面积。”
但anandtech指出,这里的问题之一是工艺节点准备就绪(ready)、产品发布的生产量增加(ramping production)和实际可用之间( available)的区别。例如,Alder Lake(现在采用英特尔 7nm)将于今年问世,但Sapphire Rapids可能到2022年才会问世。虽然英特尔很高兴讨论工艺节点开发时间框架,但并没有公布产品时间框架(如毫无疑问,如果错过了规定的时间,客户会感到沮丧)。
二、两大创新性技术:RibbonFET和PowerVia
在演讲中,英特尔的全球技术开发团队负责人Ann Kelleher博士表示,公司将于2024年上半年推出的Intel 20A会成为制程技术的又一个分水岭。它拥有两大开创性技术——RibbonFET的全新晶体管架构,名为PowerVia的史无前例的创新技术,可优化电能传输。
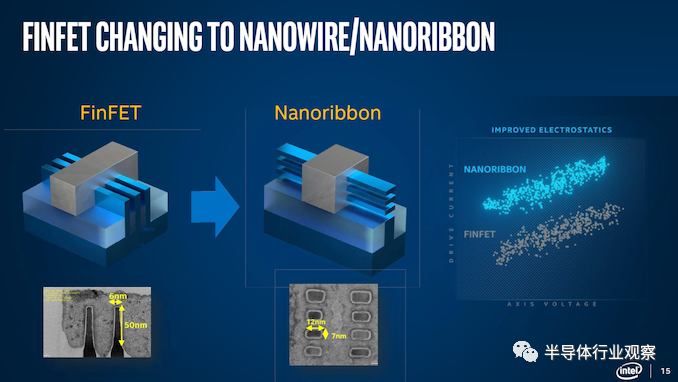
如上文所说,转向20A时,英特尔的工艺名称指的是埃米而不是纳米。也就是在这个时刻,英特尔将从其FinFET设计过渡到一种新型晶体管,称为Gate-All-Around晶体管或GAAFET。在英特尔的案例中,他们为其版本提供的营销名称是RibbonFET。
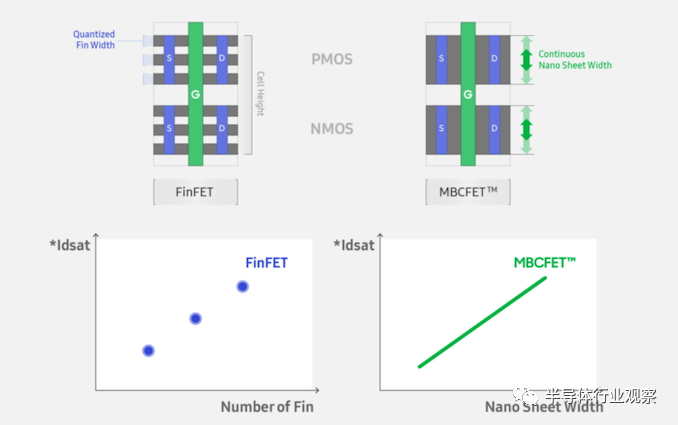
人们普遍预计,一旦标准FinFET失去动力,半导体制造行业将转向GAAFET设计。每个领先的供应商都称他们的实现方式不同(RibbonFET、MCBFET),但它们都使用相同的基本原理——具有多个层的灵活宽度晶体管帮助驱动晶体管电流。
多年来,英特尔一直在半导体技术会议上讨论GAAFET,在2020年6月的国际VLSI会议上,时任Intel CTO的Mike Mayberry博士展示了一张图表,其中包含转向GAA设计的增强静电。当时我们询问了英特尔批量实施GAA的时间表,并被告知预计“在5年内”。目前,英特尔的RibbonFET将采用20A工艺,根据上述路线图,很可能在2024年底实现产品化。

据英特尔制程技术相关负责人Sanjay Natarajan博士介绍,RibbonFET是一个Gate All Around晶体管。作为一项已经在业界被研发多年的技术,Gate All Around的名称来自于晶体管的架构。从设计上看,这个全新设计将栅极完全包裹在通道周围,可实现更好的控制,并在所有电压下都能获得更高的驱动电流。
新的晶体管架构加快了晶体管开关速度,最终可打造出更高性能的产品。通过堆叠多个通道,即纳米带,可以实现与多个鳍片相同的驱动电流,但占用的空间更小。通过对纳米带的部署,英特尔可以使得带的宽度可以被调整,以适应多种应用。
纵观其他竞争对手,台积电有望在其2nm工艺上过渡到GAAFET设计。在2020年8月的年度技术研讨会上,台积电确认将一直采用FinFET技术直至其3nm(或 N3)工艺节点,因为它已经能够找到该技术的重大更新,以实现超越最初预期的性能扩展——与台积电N5相比,N3具有高达50%的性能提升、30%的功耗降低或1.7倍的密度提升。需要强调的是,台积电N2的细节尚未披露。
相比之下,三星表示将在其3nm工艺节点中引入其GAA技术。早在2019年第二季度,三星代工厂就宣布向主要客户提供其使用GAAFET的新3GAE工艺节点的第一个v0.1开发套件。当时三星预测到2021年底量产,而最新公告表明,虽然3GAE将在2022年内部部署,但主要客户可能要等到2023年才能获得更先进的3GAP工艺。
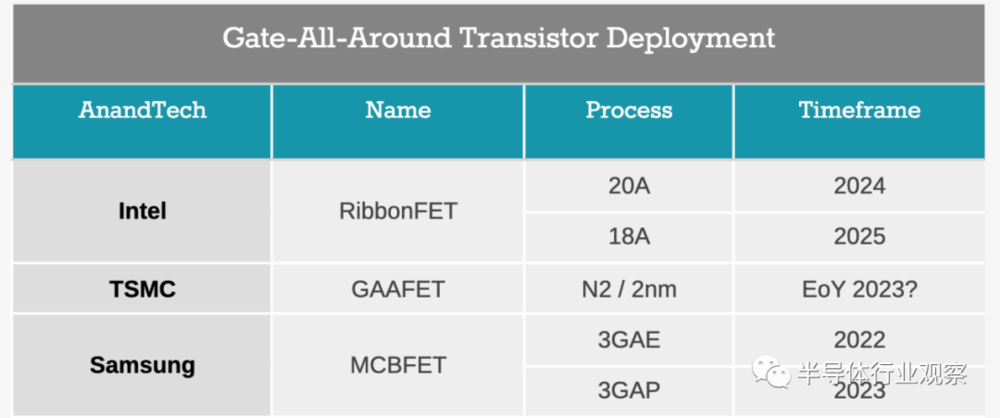
按照这个指标,三星可能是第一个迈入GAA大门的,尽管有内部节点,而台积电将首先从N5、N4和 N3节点中获得很多收益。大概到2023年底,台积电可能会考虑其N2设计,而英特尔则致力于2024年的时间框架。
PowerVia则是英特尔全新的背面电能传输网络。这是由英特尔工程师开发的一项独特技术,也将在Intel 20A中首次采用。
我们知道,现代电路的制造过程从晶体管层M0作为最小层开始。在此之上,以越来越大的尺寸添加额外的金属层,以解决晶体管与处理器不同部分(缓存、缓冲器、加速器)之间所需的所有布线。现代高性能处理器的设计中通常有10到20个金属层,顶层放置外部连接。然后将芯片翻转(称为倒装芯片),以便芯片可以通过底部的连接和顶部的晶体管与外部世界进行通信。
但正如Sanjay Natarajan博士所说,这种传统的互连技术是在晶体管层的顶部进行互联,由此产生的电源线和信号线的互混,导致了布线效率低下的问题,会影响性能和功耗。为此业界转向了“背面供电的技术”,也就是英特尔所说的PowerVias。

在新的工艺中,英特尔把电源线置于晶体管层的下面,换言之是在晶圆的背面。通过消除晶圆正面的电源布线需求,可腾出更多的资源用于优化信号布线并减少时延。通过减少下垂和降低干扰,也有助于实现更好的电能传输。这使我们能够根据产品需求,对性能、功耗或面积进行优化。
换另一种说法,在全新的设计中,我们现在将晶体管置于设计的中间。在晶体管的一侧,我们放置了通信线,允许芯片的各个部分相互通信。另一方面是所有与电源相关的连接(以及电源门控)。从本质上讲,我们转向了三明治,其中晶体管是填充物。
“PowerVia将是业界首个部署的背面电能传输网络。当我们将这一创新做到产品中时,其缺陷密度、性能和可靠性让我们相信,它将蓄势待发。”Sanjay Natarajan博士强调。
从整体来看,我们可以确定这种设计的好处始于简化电源线和连接线。通常,这些必须被设计为确保没有信号干扰,并且主要的干扰源之一是大功率传输线,因此通过将它们放在芯片的另一侧,可以将它们排除在外。它也以另一种方式起作用——互连数据线的干扰会增加功率传输电阻,从而导致能量和热量损失。通过这种方式,PowerVias 可以在驱动电流增加时帮助新一代晶体管,因为它可以直接在那里供电,而不是围绕连接进行布线。
但正如anandtech所说,这里有几个障碍需要注意。
通常我们首先开始制造晶体管,因为它们是最困难且最有可能出现缺陷的——如果在制造早期发现缺陷(制造中的缺陷检测),那么可以在周期中尽早报告。通过在中间放置晶体管,英特尔现在可以先制造几层电源,然后再进入艰难的阶段。现在从技术上讲,与晶体管相比,这些电源层将非常容易,并且不会出错,但这是需要考虑的。
要考虑的第二个障碍是电源管理和导热性。现代芯片首先将晶体管构建成十几个层,以电源和连接结束,然后芯片被翻转,因此耗电的晶体管现在位于芯片的顶部,并且可以管理热量。在三明治设计中,热能将通过芯片顶部的任何东西,这很可能是内部通信线路。假设这些电线的热量增加不会在生产或常规使用中引起任何问题,那么这可能不是什么大问题,但是当热量必须从晶体管传导出去时需要考虑。
值得注意的是,这种“背面供电”技术已经开发了很多年。在2021年的VLSI研讨会上发表的五篇研究论文中,imec发表了多篇关于该技术的论文,展示了使用FinFET时的最新进展,并且在2019年,Arm 和imec宣布了基于等效3nm工艺构建的Arm Cortex-A53上的类似技术设施。
总体而言,该技术降低了设计上的IR压降,这在更先进的工艺节点技术上越来越难以实现以提高性能。当该技术在高性能处理器上大量使用时,将会很有趣。
三、下一代封装:EMIB和Foveros
除了工艺节点的进步,英特尔还必须推进下一代封装技术。因为市场对高性能芯片的需求加上日益困难的工艺节点开发,就创造了这样的一种环境,在这种环境中,处理器不再是一个单一的硅片,而是依赖于以有利于性能的方式封装在一起的多个较小(并且可能优化)的小芯片或块、电源和最终产品。
换而言之,单个大型芯片不再是明智的商业决策——因为它们最终可能很难做到没有缺陷,或者制造它们的技术没有针对芯片上的任何特定功能进行优化。然而,将处理器分成单独的硅片会为在这些片之间移动数据造成额外的障碍——如果数据必须从硅片过渡到其他东西(例如封装或中介层),那么就有了力量要考虑的成本和延迟成本。
权衡是针对特定目的构建的优化硅,例如在逻辑工艺上制造的逻辑芯片,在存储器工艺上制造的存储器芯片,并且较小的芯片在合并时通常比较大的芯片具有更好的电压/频率特性。但支撑这一切的是芯片是如何组合在一起的,
英特尔的两种主要专业封装技术是EMIB和Foveros。英特尔解释了两者与未来节点开发相关的未来。
1. EMIB:嵌入式多芯片互连桥接器
英特尔的EMIB技术专为布局在2D平面上的芯片到芯片连接而设计。
同一基板上的两个芯片相互通信的最简单方法是采用穿过基板的数据通路。基板是由绝缘材料层组成的印刷电路板,其中散布着蚀刻成轨道和迹线(tracks and traces)的金属层。根据基板的质量、物理协议和所使用的标准,通过基板传输数据会消耗大量电力,并且带宽会降低。但是,这是最便宜的选择。
基板的替代方案是将两个芯片都放在中介层(interposer)上。中介层是一大块硅片,大到足以让两个芯片完全贴合,并且芯片直接与中介层结合。类似地,中介层也有数据路径,但由于数据是从硅片移动到硅片的,因此功率损失不如基板多,带宽可以更高。这样做的缺点是中介层也必须制造(通常在65nm上),所涉及的芯片必须足够小以适应,而且可能相当昂贵。为此,interposer和active interposers是一个很好的解决方案。
英特尔的EMIB解决方案是中介层和基板的结合。英特尔没有采用大型中介层,而是使用小型硅片并将其直接嵌入基板中,英特尔将其称为桥接器。桥实际上是两半,每边有数百或数千个连接,并且芯片被构建为连接到桥的一半。现在,两个芯片都连接到该桥接器,具有通过硅传输数据的好处,而不受大型中介层可能带来的限制。如果需要更多带宽,英特尔可以在两个芯片之间嵌入多个桥接器,或者为使用两个以上芯片的设计嵌入多个桥接器。此外,该桥的成本远低于大型中介层。

有了这些解释,听起来英特尔的EMIB是双赢的。然而该技术存在一些限制——实际上将桥嵌入基板有点困难。英特尔已花费数年时间和大量资金试图完善该技术以实现低功耗运行。最重要的是,每当您将多个元素添加在一起时,该过程都会产生相关的良率问题——即使将芯片连接到桥的良率是 99%,但在单个设计中使用十几个芯片会降低整体良率下降到87%,即使从已知的好芯片(有自己的收益)开始也是如此。当您听说英特尔一直致力于将这项技术推向市场时,他们正在努力改进这些数字。
英特尔目前在市场上的几种产品上都有EMIB,最引人注目的是其Stratix FPGA和Agilex FPGA系列,但它也是Kaby G移动处理器系列的一部分,将Radeon GPU连接到高带宽内存。英特尔已经表示将基于其推出多款未来产品,包括Ponte Vecchio(超级计算机级图形)、Sapphire Rapids(下一代至强企业处理器)、Meteor Lake(2023 消费级处理器)以及其他与图形相关的产品。
在EMIB的路线图方面,英特尔将在未来几年减少凸点间距。当芯片连接到嵌入在基板中的桥时,它们通过凸块连接,凸块之间的距离称为间距——凸块间距越小,在同一区域内可以建立的连接越多。这允许芯片增加带宽或减小桥接尺寸。
2017年的第一代EMIB技术使用55微米凸点间距,而且即将推出的Sapphire Rapids似乎仍然如此,但是英特尔正在将自己与超越Sapphire Rapids的45微米EMIB,导致第三代36微米EMIB。这些的时间表没有透露,但是在Sapphire Rapids之后将是Granite Rapids,因此到这时,可能会推出45微米的设计。
2. Foveros:Die to Die的堆栈
英特尔于2019年通过Lakefield推出了其芯片到芯片堆叠技术,Lakefield是一款专为低空闲功耗设计而设计的移动处理器。虽然该处理器此后走向了生命尽头,但该想法仍然是英特尔未来产品组合和代工产品的未来不可或缺的一部分。
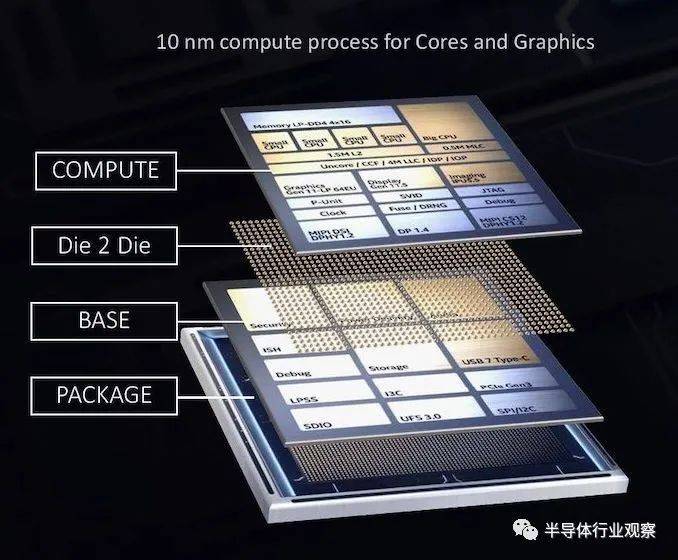
英特尔的die-to-die堆叠在很大程度上与EMIB部分中提到的中介层技术非常相似。
我们将一块(或更多)硅片放在另一块硅片上。然而,在这种情况下,interposer或基片具有与顶部硅片中的主计算处理器的完整运行相关的有源电路。虽然内核和图形在Lakefield的顶级芯片上,建立在英特尔的10纳米工艺节点上,但基础芯片拥有所有PCIe通道、USB端口、安全性以及与IO相关的所有低功耗,并建立在22FFL低功耗上进程节点。

因此,虽然EMIB技术将硅片彼此分开工作被称为2D缩放,但通过将硅片放在彼此的顶部,我们已经进入了完整的3D堆叠方式。这带来了一些好处,尤其是在规模上,可以获得数据路径更短的优势,由于更短的电线而导致更少的功率损耗,但也有更好的延迟。芯片到芯片的连接仍然是键合连接,第一代的间距为50微米。
但这里有两个关键限制:热量和功耗。为避免散热问题,英特尔使基本芯片几乎没有逻辑并使用低功耗工艺。在电源方面,问题在于让顶部计算芯片为其逻辑供电——这涉及从封装向上通过基础芯片到顶部芯片的大功率硅通孔(TSV),而那些承载功率的TSV成为由于高电流引起的干扰而导致的局部数据信令问题。还希望在未来的工艺中缩小到更小的凸点间距,从而实现更高的带宽连接,需要更多地关注功率传输。
今天与Foveros相关的第一个公告是关于第二代产品。英特尔的2023年消费级处理器Meteor Lake已在上文中描述为使用英特尔4nm计算块。英特尔今天还表示,它将在该平台上使用其第二代Foveros 技术,实现36微米的凸点间距,与第一代相比,连接密度有效地增加了一倍。Meteor Lake中的另一个tile尚未公开(它有什么或它在哪个节点上),但英特尔也表示Meteor Lake将从5W扩展到125W。
3. Foveros Omni:第三代Foveros
对于那些一直密切关注英特尔封装技术的人来说,“ODI”这个名字可能很熟悉。它代表Omni-Directional Interconnect,它是英特尔之前封装技术路线图中的名称。现在将作为Foveros Omni销售。
这意味着第一代Foveros需要top tie小于base die的限制现在被取消。top tie可以比base die大,或者如果每个层上有多个裸片,它们可以连接到任意数量的其他硅片。Foveros Omni的目标是真正解决 Foveros初始部分中讨论的功率问题——因为承载TSV的功率会在信号中造成大量局部干扰,因此放置它们的理想位置是在base die的外部。Foveros Omni是一种技术,允许顶部裸片从基础裸片悬垂,铜柱从基板一直延伸到顶部裸片以提供电源。

使用这种技术,如果可以从top die的边缘引入电源,则可以使用这种方法。然而,我确实想知道,如果使用大硅片,电源是否会更好地从中间馈电——英特尔曾表示Foveros Omni与分离式base dies一起工作,这样,如果base die设计用于可在该较低层上使用的基板。
通过将功率TSV移到base die之外,这还可以改善裸片到裸片的凸点间距。英特尔称Omni为25微米,与第二代Foveros相比,凸点密度又增加了50%。英特尔预计Foveros Omni将在2023年为批量生产做好准备。
4. Foveros Direct:第四代Foveros
任何芯片到芯片连接的问题之一是连接本身。在迄今为止提到的所有这些技术中,我们都在处理微凸点粘合连接——带有锡焊帽的小铜柱,它们被放在一起并“粘合”以创建连接。由于这些技术正在增加铜和沉积锡焊料,因此很难将它们按比例缩小,而且电子设备的功率损耗也会转移到不同的金属中。
Foveros Direct通过直接进行铜对铜键合来解决这个问题。
多年来,人们一直在研究硅与硅之间直接连接的概念,而不是依靠柱子和凸块的结合。如果一块硅直接与另一块对齐,那么几乎不需要额外的步骤来生长铜柱等。问题在于确保所有连接都已完成,确保top die和base die都非常平坦,没有任何障碍。此外,两片硅必须合二为一,并且永久粘合在一起而不会分开。

Foveros Direct是一项技术,可帮助英特尔将其芯片到芯片连接的凸点间距降低到10微米,密度是 Foveros Omni的6倍。通过实现扁平铜对铜连接,凸点密度增加,全铜连接的使用意味着低电阻连接和功耗降低。英特尔建议使用Direct,功能芯片分区也变得更容易,并且可以根据需要将功能块拆分到多个级别。
从技术上讲,Foveros Direct作为芯片到芯片的键合可以被认为是对Foveros Omni的补充,它具有base die外部的电源连接——两者都可以相互独立使用。直接绑定会使内部电源连接更容易,但可能仍然存在干扰问题,Omni会处理这些问题。
应该指出的是,台积电拥有类似的技术,称Chip-on-Wafer (或Wafer-on-Wafer),其客户产品将在未来几个月内使用2层堆栈推向市场。台积电在2020年年中展示了12层堆栈,但这是用于信号的测试工具,而不是产品。堆栈中的问题仍然是热量,以及进入每一层的内容。
英特尔预测,Foveros Direct与Omni一样,将在2023年准备好量产。
“随着我们继续推动先进封装的发展,我们将在未来几代技术中从电子封装过渡到集成硅光子学的光学封装。当然,我们将继续与包括Leti、IMEC和IBM在内的产业伙伴密切合作,在以上和其他诸多创新领域进一步发展制程和封装技术。”英特尔方面强调。
四、EUV光刻机和晶圆代工客户
在英特尔今天的演讲中,他们强调,公司将成为ASML下一代EUV 技术(即 High-NA EUV)的主要客户。其中NA与EUV机器的“数值孔径”有关,或者简单地说,在EUV光束击中晶圆之前,您可以在机器内部使该光束有多宽。在您击中晶片之前光束越宽,它击中晶片时的强度就越大,从而提高打印线条的准确度。
通常,在光刻中为了获得更好的印刷线,我们从单一图案化转向双图案化(或四方图案化)以获得这种效果,这会降低产量。转向High NA意味着生态系统可以更长时间地保持单一模式,一些人认为这可以让行业“更长时间地与摩尔定律保持一致”。
首先,英特尔方面表示,将EUV投入量产,需要构建一个以该设备为中心的完整供应链生态——光刻胶、掩模生成、蒙版加附、计量检测。而英特尔为构建这个生态系统付出了很大努力。
据了解,英特尔子公司IMS是EUV多波束掩模刻写仪的全球主要供应商。这是制作高分辨率掩模的必备工具,而掩模则是实现EUV光刻技术的关键部分。采用掩模刻写技术对英特尔来说极具竞争优势,也是同业的关键推动力。
与此同时,英特尔还在携手ASML定义、构建和部署下一代EUV工具,被称为高数值孔径EUV(High-NA EUV)。High-NA将集成更高精度的透镜和反射镜,以提高分辨率,从而在硅片上刻印出更微小的图样。英特尔有望率先获得业界第一台High-NA EUV光刻机,并计划在2025年成为首家在生产中实际采用High-NA EUV的芯片制造商。
英特尔强调,这些进展也取决于我们和业界其他关键参与者的密切合作。与包括应用材料(Applied Materials)、泛林集团(LAM Research)和东电电子(TEL)在内的设备供应商的合作,是我们实现领先技术路线图的关键。
从目前看来,当前的 EUV 系统的NA为 0.33,而新系统的NA为 0.55。ASML 的最新更新表明,它预计客户将在 2025/2026 年可以使用 High-NA 设备进行生产,这意味着英特尔可能会在 2024 年中期获得第一台机器(我们认为是 ASML NXE:5000)。确切地说,ASML 打算在那个时间段内生产多少台High NA 机器是未知的,那就意味着拥有第一台机器不会是一个大胜利。但是,如果 High-NA 上升缓慢,则由英特尔来利用其优势。
最后,英特尔还披露了他们在晶圆代工方面的进展。
Pat Gelsinger表示,英特尔代工服务(IFS)的优势之一,是公司既能提供领先的制程和封装技术创新,又能将我们的既有成熟技术以全新的方式服务于我们的客户。客户对英特尔代工服务(IFS)一直怀有强烈的兴趣,其中受到重点关注的是我们成熟的先进封装技术。
基于此,英特尔宣布,公司已经与AWS签约,它们将成为我们的第一个使用英特尔代工服务(IFS)封装解决方案的客户。此外,英特尔也与高通合作,他们将采用Intel 20A制程工艺技术。
两家公司都坚信,移动计算平台的领先发展将开启半导体的新时代。可以明确的是,英特尔代工服务已扬帆起航!
本文来自微信公众号:半导体行业观察(ID:icbank),作者:穆梓