
本文来自微信公众号:学术头条(ID:SciTouTiao),作者:库珀,编审:寇建超,排版:王洛尘,原文标题:《你的论文 “后劲儿” 有多大?MIT科学家开发AI预知模型,能更早、更准锁定 “隐藏宝石”》,头图来自:视觉中国
怎样评估一篇学术论文发表后是否有 “影响力”?
目前,业内普遍采用基于引文的指标,比如所著论文的引用量、H-index(H 指数,一个混合量化指标,用于评估研究人员的学术产出数量与水平),以及期刊影响因子在时间和领域内的归一化测度等。
科学事业的有效发展取决于一系列有前途的科研人员、以及研究项目能否分配到优势资源。因此,传统的评判论文是否有影响力的指标,不仅是对学术质量的评定;但在某种程度上,也存在滞后的影响。因为,这些传统评估指标可能导致一些研究在后续的学术招聘、晋升和资助方面被轻视,进而产生偏见,影响助力项目的资金。

考虑到当前科学发展的现状问题和有限资源,如果能提前预判一篇论文的 “影响力” 大小,就可以帮助行业超越简单的基于引用的度量标准,从而更好地将科研注意力、投资等引导到更正确的地方。
为了实现对论文 “影响力” 的准确分析评估,来自麻省理工学院的科学家 James Weis 和 Joseph Jacobson 建立了一个名为 DELPHI(通过学习预测高影响实现动态预警)的机器学习模型,并用知识图谱加以训练,从而可以更早、更准地锁定那些未来有影响力的科研成果,相关论文于 5 月 17 日发表在《自然 - 生物技术》(Nature Biotechnology)期刊上。

在一次回顾性盲法研究中,DELPHI 准确识别出了 1980~2014 年期间 20 项具有重大影响的生物技术中的 19 项,还以数据驱动的方式发现并促进经费流向那些 “深藏不露” 的好研究项目。DELPHI 未来或将用于更准确地评估科研人员的产出质量和水平,有望成为一种全新的学术影响力评估手段。
AI 模型:发现 “隐藏的宝石”
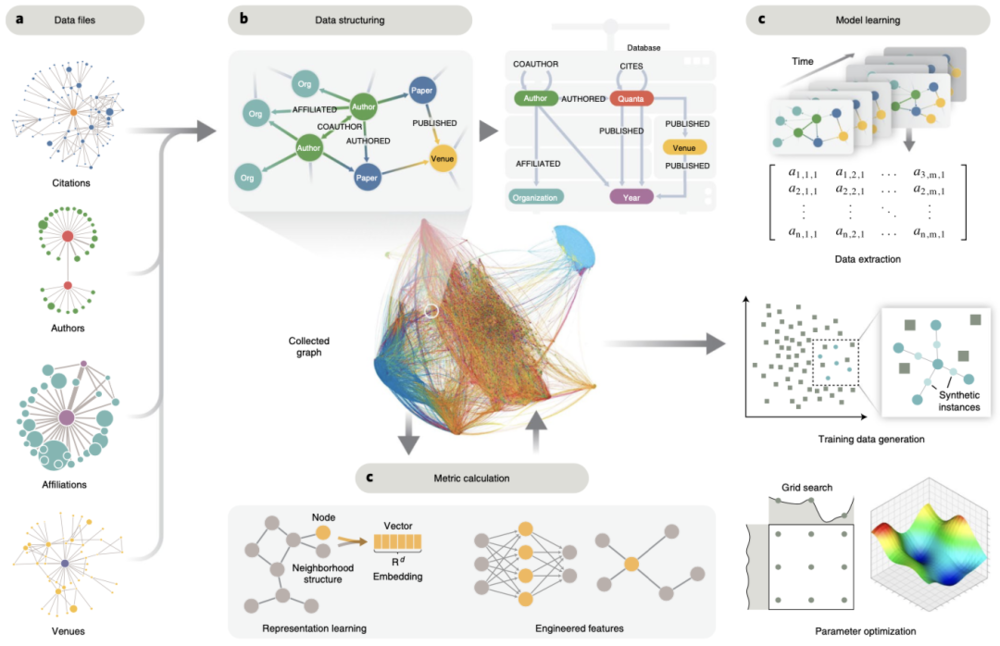
具体而言,DELPHI 的开发者们使用的数据集包含 1980~2019 年期间发表的 1687850 篇具有唯一性的论文,包括 780 多万个单独节点、2.01 亿个关系和 38 亿个计算指标,从中得到了论文发表后 1~5 年与每例论文、作者、期刊、网络相关的 29 个特征,作者再用每篇论文的特征训练一个机器学习模型,让这个模型给出影响力 “预警” 信号。
研究人员通过使用盲法模型进行回顾性分析,并通过对 2017 年和更早时期的论文进行新模型培训,证明了 DELPHI 已具备识别有影响力的生物技术的能力。
基于 29 个特征的学习影响研究,研究人员在以生物技术为中心的数据库中,使用所有应用程序的度量和学习表示对模型进行训练,训练时间窗从发布年份到发布后 5 年,将发表后 5 年时间排名前 5% 的论文称为 “高影响”,这 5% 的论文约能占到数据集中总影响的 35% 以上。
经测试,DELPHI 在出版之年就能精确识别出一篇论文未来大概有多高的影响力,大大优于仅使用引用数据或最近文献中使用的指标训练的类似模型。
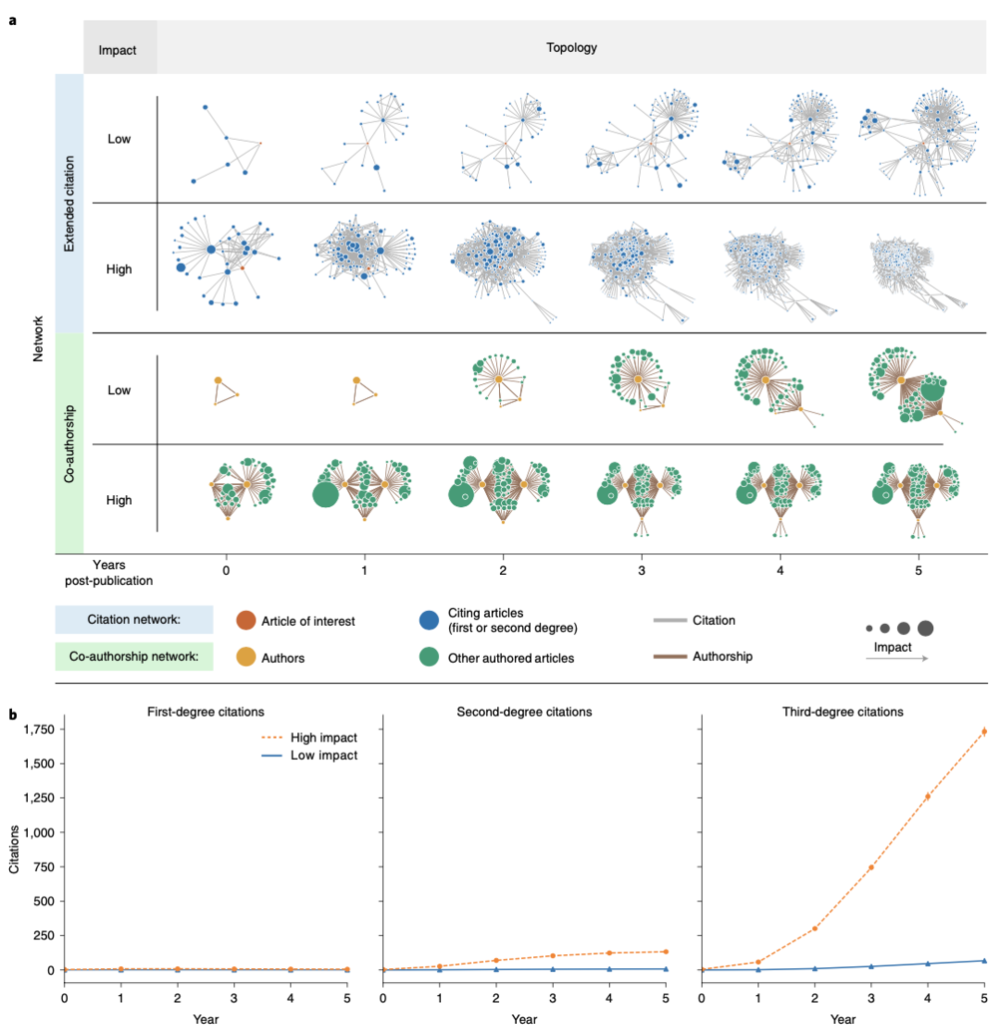
有趣的是,大量正确识别的 “高影响力” 科研文献在初期的引用率并不高,因此,它们就像 “隐藏的宝石”,使用简单的基于引用的指标很难发现它们。
例如,一篇刊登在《基因与发育》(Genes & Development)期刊上的关于早期胚胎的重要论文:“G9a histone methyltransferase plays a dominant role in euchromatic histone H3 lysine 9 methylation and is essential for early embryogenesis”,DELPHI 正确预测了其具有高影响力潜质,但这篇论文在发表后 2 年内仍只有少量的累计引用次数,因此,如果仅根据索引数量来评估,它的影响力根本不会被选入前 5% 之列。
一般来说,使用发表后 2 年的数据,设定 80% 的预测精确度目标对应的引用阈值为 18。但研究人员发现,大约 60% 的高影响力论文(“隐藏宝石”)会低于这一阈值,以同样的精度目标(80%),DELPHI 可正确识别出两倍以上的高影响力论文,包括那 60% 被引用阈值遗漏的部分。
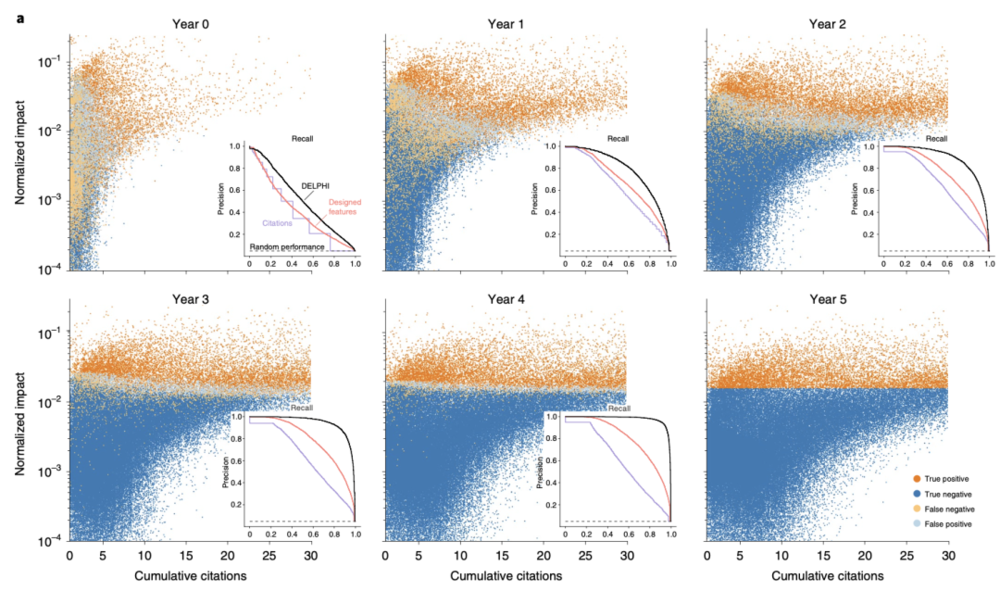
值得关注的是,DELPHI 的 “预警” 信号强度会随时间序列数据量的增加而增强。例如,DELPHI 正确预测了哪项研究将具有很高的影响力,在不到 1 年的数据中,均衡精度为 77%,而在不到 2 年的数据中,均衡精度则增长到 87%。
研究人员还使用 DELPHI 来预测了最近发表的未来可能具有重要意义的论文。利用一个对 2018 年以后的论文不知情的再培训模型,在 2019 年发布的数据库中计算了这些论文的评估分数,实验结果突出了 DELPHI 可在多个领域自主评估 “高影响” 论文的潜力。
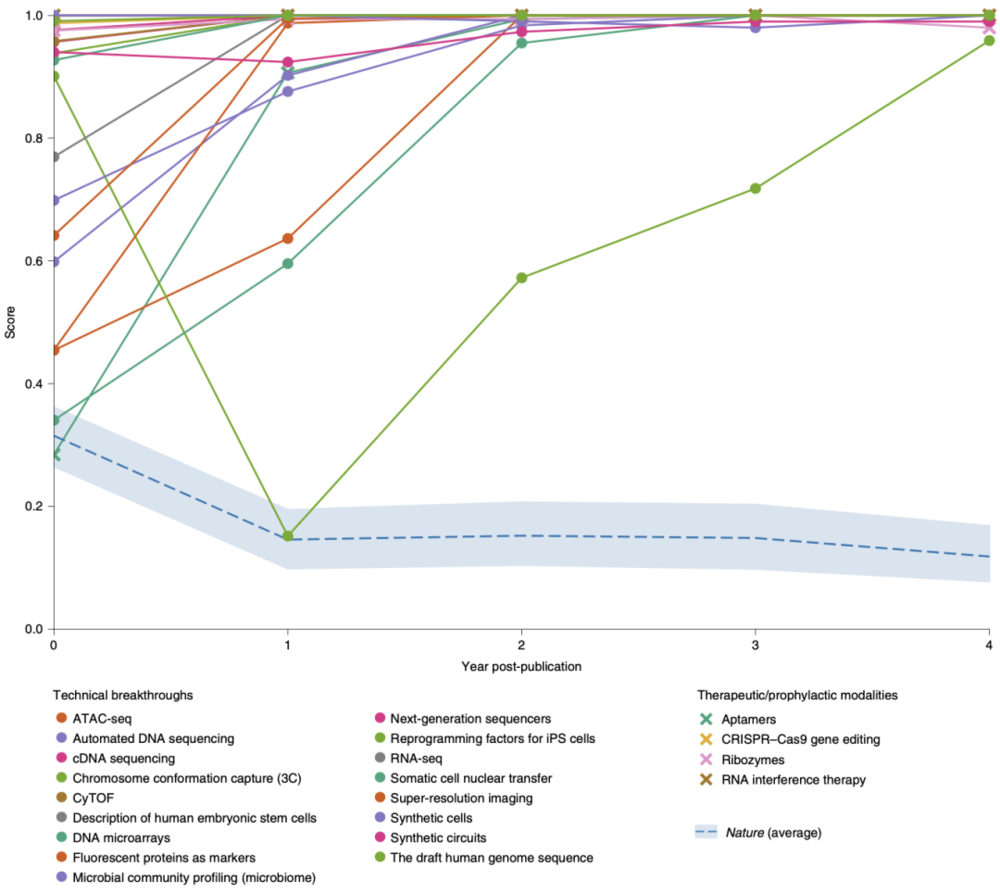
科研经费如何分配效果最好?
据论文描述,DELPHI 是一种在大型、异构、时间结构的网络数据上使用机器学习的方法,可以用来预测高影响科学研究的定量预警分数。由于这种图形本机结构,DELPHI 也很容易扩展到新的数据类型。
研究人员还注意到,从数据集中导出的 29 个特征不一定都与科学影响正相关,也不对基于声誉的信号完全依赖,因为 DELPHI 模型只学习使用那些真正包含未来影响信息的指标。
“我们能在影响预测方面大大优于以前的引用和手工系统。尽管这篇论文代表了一个初步的解释,但这样一个系统提供了很多有趣的可能性。” 研究人员在论文中写道。
对于高度连接的网络,如互联网的物理网络结构或社交网络(例如 Facebook),边数(节点之间的连接)与节点数(设备或用户)的平方成比例。由于构建这样的网络的成本随着节点数的增加而增加,而价值随着边缘数的增加也会增加,因此这样的网络可以非常快速地扩展,而且非常有价值。
研究人员表示,假设科学事业也是如此,随着节点(研究项目)之间的连接数量增加,科学研究集合所创造的价值在资助项目数量上会从线性过渡到几何。
因此,他们建议可以通过高效分配研究资源,从而使科研图谱中的 “边数量” 最大化,尽管这种有益的分配迄今为止很难实施,但现在可以开始考虑使用 DELPHI 模型来帮助项目设计筹资策略。
另一个有趣的可能性是推动研究项目的数量多样化。比如可以考虑通过使用 DELPHI 模型来构建一个多元化的投资组合,最大限度地提高风险调整后的科学影响,也就是说,一组总体上具有最佳风险回报特征的研究计划。
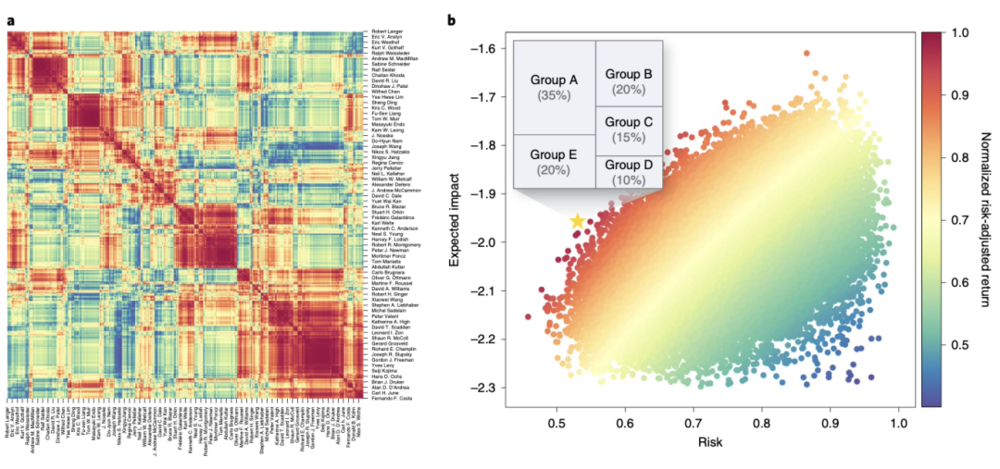
举个例子,如果我们要选择资助数据集中前 5% 的论文,基于发表后 2 年的引用数量,我们将资助约 59% 的高影响力研究,但误报率超过 41%,而使用 DELPHI,我们可以鉴定并资助超过 81% 的高影响力研究,误报率仅为 20%。
研究人员认为,DELPHI 方法对于提高总体生产率有很大的希望,不仅包括确定最有影响的项目,而且还包括更全面地探索科学研究的尾端,在这些尾端,革命创新可能会不成比例地发生。
科学文献机器辅助分析走向应用
对于 DELPHI,研究人员强调,尽管论文所描述的结果令人兴奋,但这仅仅是走出了科学文献机器辅助分析的实践第一步。DELPHI 应该被理解为更广泛的科学分析工具包的一部分,与人类经验和直觉结合使用,以增强而不是取代人类水平的理解。此外,与所有基于机器学习的系统一样,必须注意确保这种方法潜在的系统偏差,保证其不会被恶意行为者操纵,以获取与自身相关的利益。
DELPHI 目前研究的领域聚焦在生物技术期刊上发表的论文,预测论文在发表后 5 年内产生的科学影响,但还有一些长期的科学趋势可能不会被这个时间窗口捕捉到,例如,单克隆抗体是在 20 世纪 70 年代中期发现的,但直到 20 世纪 90 年代初,它才加速成为一个重要领域。DELPHI 的时间序列分析和网络级别度量的组合可能包含捕获和帮助理解这些趋势所必需的表达能力。

在未来的研究中,还可以探索改进 DELPHI 框架的技术途径。由于目前这项研究是确定最有希望的 5% 的生物技术研究,采用了基于分类的方法,但 DELPHI 框架也可以与基于回归的方法一起使用,这些方法可以通过提取额外的信号或更好地识别异常值来提高性能。
随着科学语料库的不断增长,以及非传统文献(如学术预印本)的日益重要,DELPHI 基于其固有的异构设计,还能够以直接的方式合并额外的数据源,例如集成预印本和商业化数据(专利和初创企业等),提供全方位的影响力洞察。
研究人员在论文结尾总结,人工智能辅助方法(比如此次研究提到的 DELPHI)的谨慎开发和部署可以释放大量现有的和尚未开发的资源。通过 AI 计算,有规模地消化科学事业中包含的大量隐藏信息,有助于整个科研生态以更公平和富有成效的方式分配有限的资源,从而提高部署到科学技术中的资源回报。
参考资料:https://www.nature.com/articles/s41587-021-00907-6
本文来自微信公众号:学术头条(ID:SciTouTiao),作者:学术头条