

感觉哪里不太对……
现在,这些3D人体模型可以得到改进了~体态更逼真、褶皱更自然、肌肉更饱满:

连情绪都显得更投入了……
甚至肌肉颤动也清晰可见:

这么一对比,差距很明显了~
不仅动画质量更高,这种新方法还大量减少了人工参与,制作速度更快了。
要知道,以前的动画需要繁琐的步骤,比如:搭建骨骼、蒙皮、刷权重等等……动画师往往要为此修炼数年,效果还常常不尽人意。

现在,只需一个神经网络就能搞定。
不仅如此,它还可以从形象中预测骨骼,并绑定权重,更容易地用运动捕捉来制作动画。
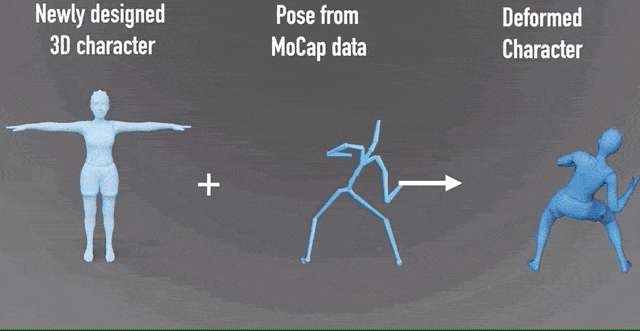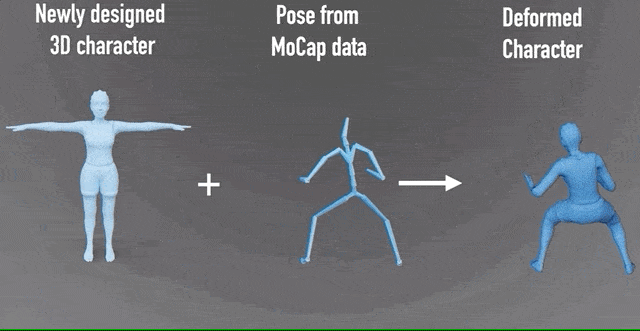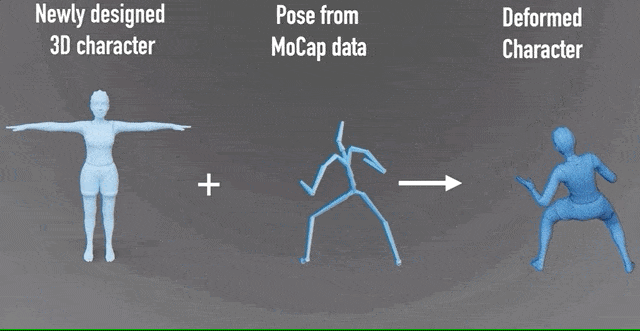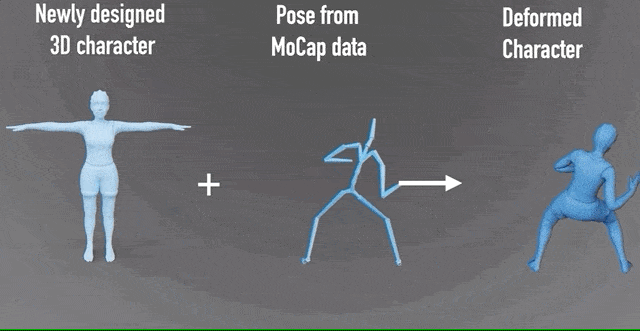
这一研究成果,由北京大学、北京电影学院等高校和机构合作完成。
相关论文《Learning Skeletal Articulations with Neural Blend Shapes》在SIGGRAPH 2021上发表,代码现已开源。

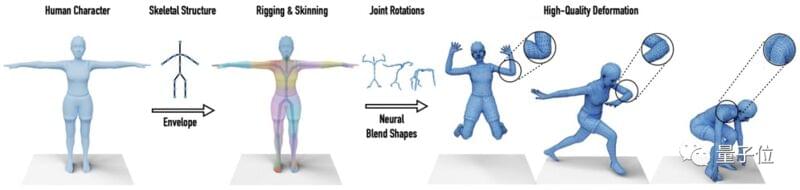
提出神经融合形状技术
团队开发了一套神经网络,用来生成具有指定结构的骨骼,并且精准绑定骨骼的蒙皮权重。
它由两个部分组成:包裹变形分支(envelope deformation branch)和补偿变形分支(residual deformation branch)。
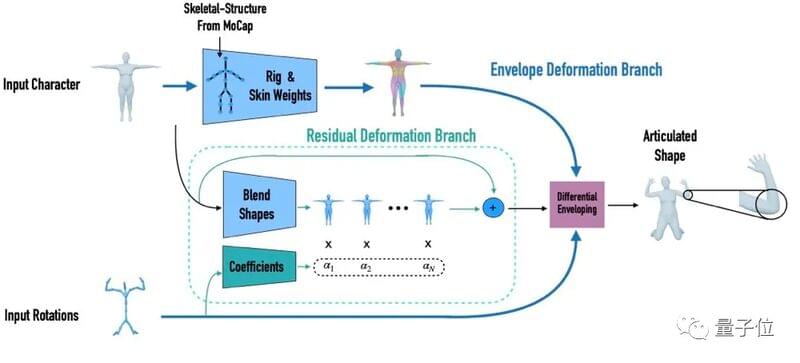
其中,包裹变形分支通过间接监督,学习由偏移量组成的特定骨架层次的装配参数,最后从输入角色中预测出骨架、蒙皮和权重绑定。
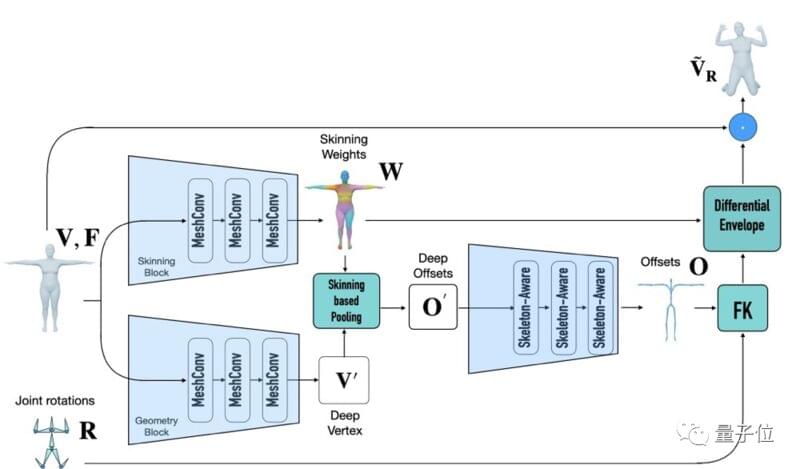
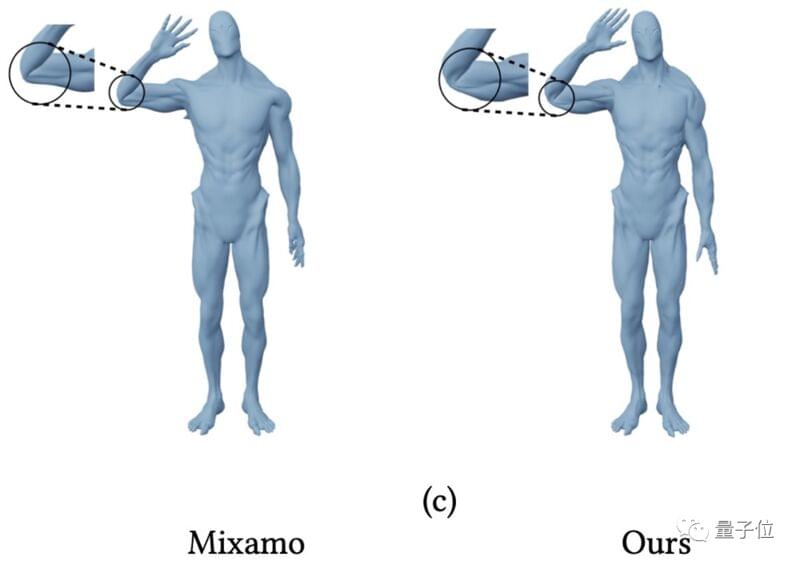
你可能会说,常用的动画制作工具Mixamo中,也有绑定和蒙皮。
但是新方法能做的不只这些,它还可以准确预测与模型高度匹配的骨骼,并绑定权重。
从而更容易进行动作捕捉,制作动画:

并且,利用一种神经融合形状(neural blend shapes)技术,补偿变形分支可以根据输入的网格连接,来预测对应的融合形状(blend shapes)。
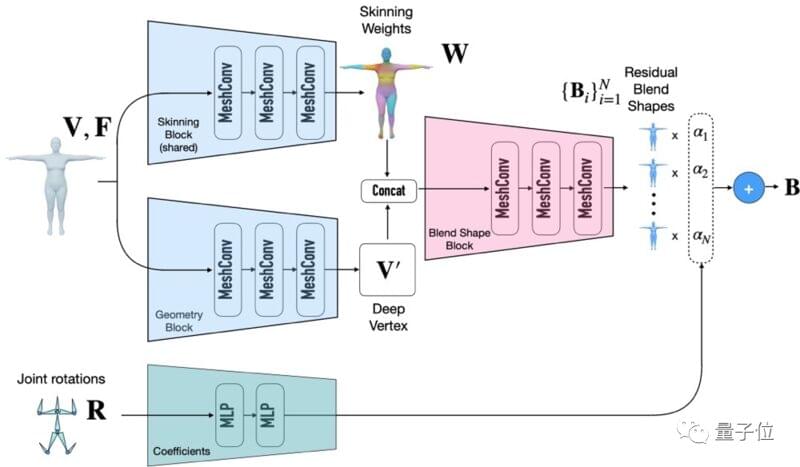
与此同时,根据关节旋转预测融合系数,然后基于此插值得到补偿变形。
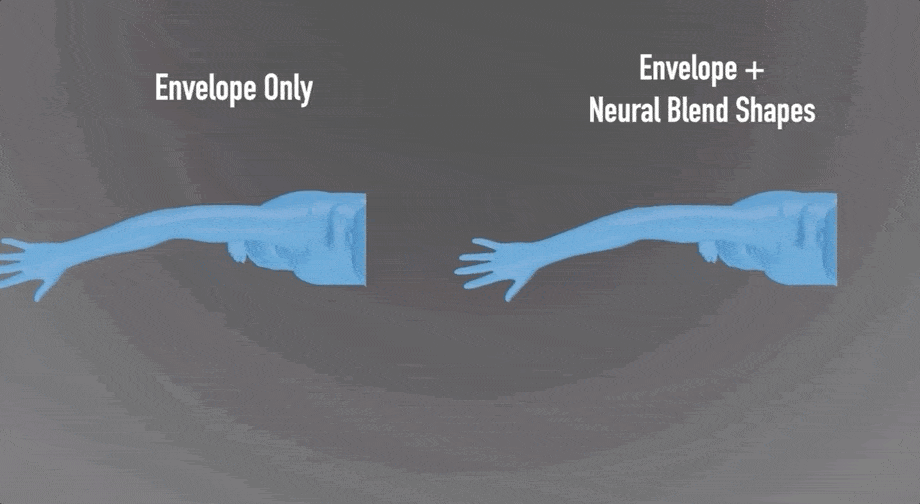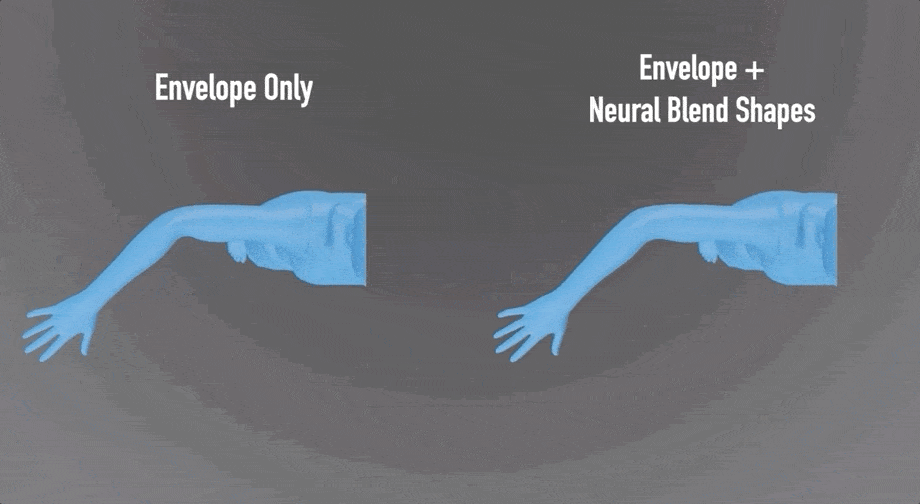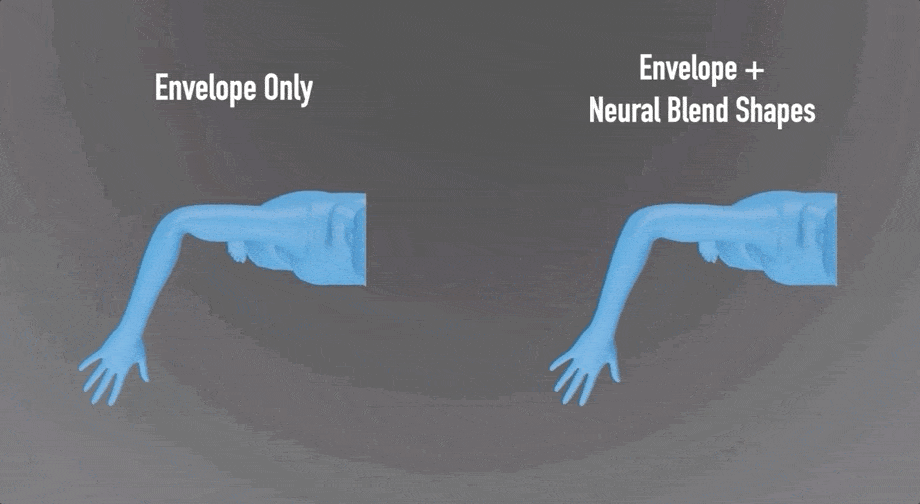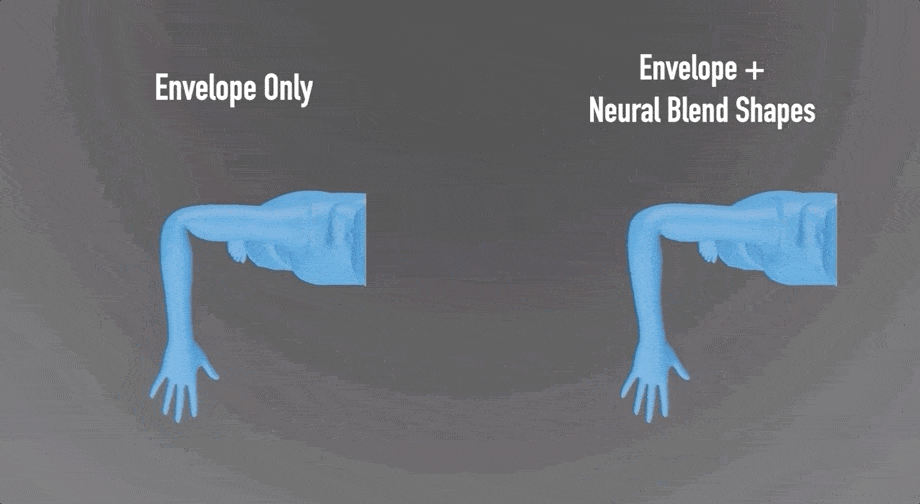
比如,神经混合形状会纠正肌肉的形状,准确保留鼓起的肌肉:
与LBS(线性混合蒙皮)算法的效果相比,细节处理得更好:
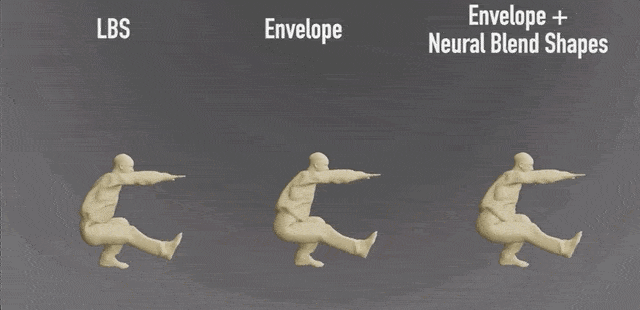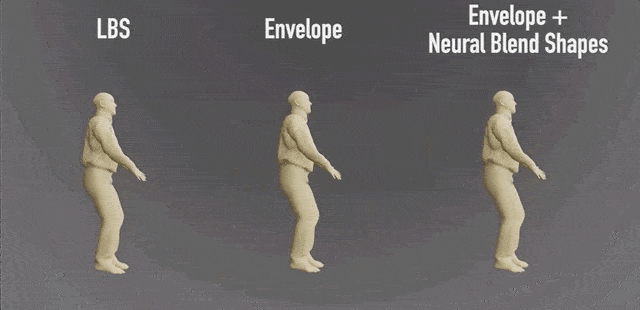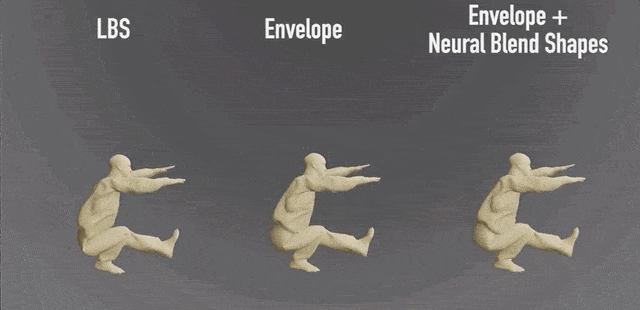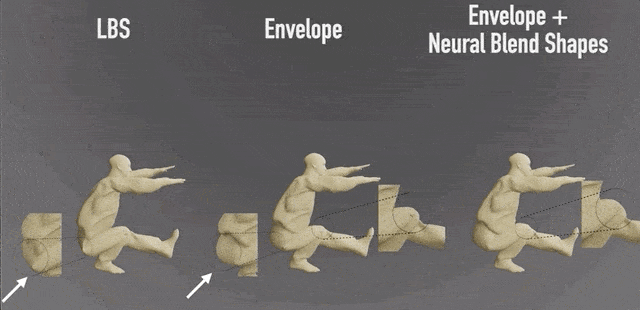
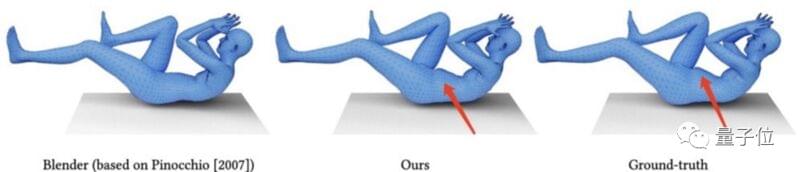
与三维动画制作软件Blender的效果对比:(小肚腩被完美保留了)
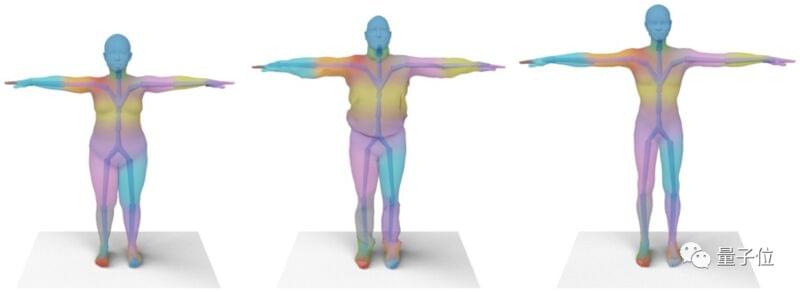
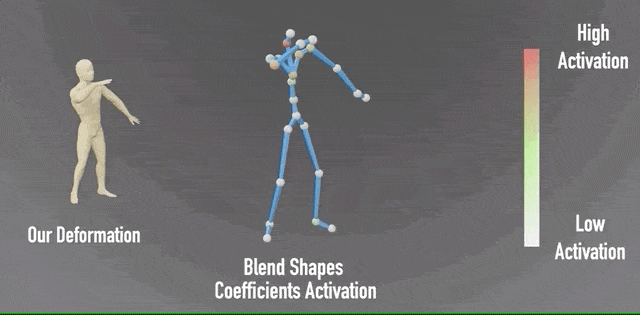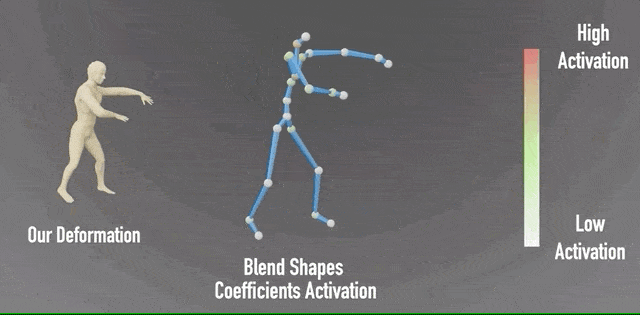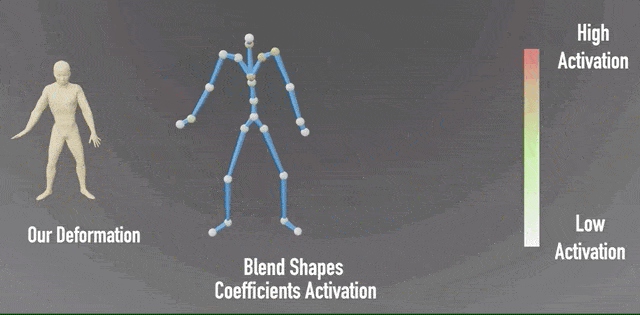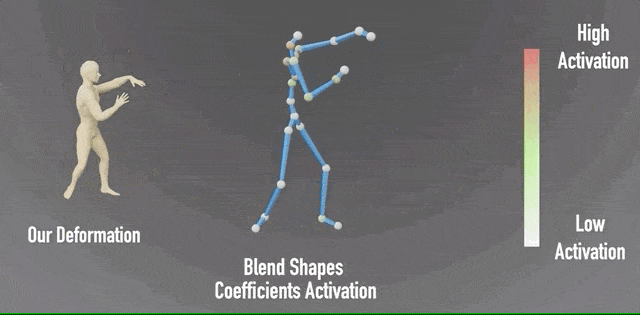
除此之外,研究团队还对神经混合形状系数进行了可视化,可以看到左侧输出的形象,与右侧相应的姿势绑定。
并且,通过颜色变化,表现各关节的混合形状系数激活程度。
利用这一方法,神经网络只需观察变形后的人物模型进行间接学习,而不需要对训练数据集的变形方法有任何限制,极大扩大了适用范围。
最终实现了,实时、高质量的三维人物模型动画端到端自动生成。
一作来自北大图灵班
团队由来自北京大学陈宝权教授研究团队、北京电影学院未来影像高精尖创新中心、Google Research、特拉维夫大学,以及苏黎世联邦理工学院的研究人员组成。
论文一作,是来自北大图灵班的一名本科生——李沛卓。

他毕业于重庆一中,曾入选信息学竞赛省队,2017年高考以687分考入北大。
目前,李沛卓师从陈宝权教授,研究方向是深度学习和计算机图形学,正在北京大学视觉计算与学习实验室和北京电影学院未来影像高精尖创新中心(AICFVE)实习。
此前,他已有论文登上SIGGRAPH。在与量子位交流时,他曾表示对图形学特别感兴趣。

论文的更多细节,感兴趣的小伙伴,可以戳链接了解详情。

项目主页:
http://peizhuoli.github.io/neural-blend-shapes/
论文地址:
http://peizhuoli.github.io/neural-blend-shapes/papers/neural-blend-shapes-camera-ready.pdf
参考链接:
[1]http://peizhuoli.github.io/
[2]http://twitter.com/RanaHanocka/status/1391867020732424197?s=05
[3]http://mp.weixin.qq.com/s/IuvyNRJ6amJn5ya7fr8L6A
[4]http://mp.weixin.qq.com/s/uU1-DwHnU4pPMLtQZNQyVQ
[5]http://