
本文来自微信公众号:量子位(ID:QbitAI),作者:梦晨、晓查,原文标题:《世界上最难的“沙雕”游戏被AI攻破了》
13年以前,有这样一款“变态”级难度的游戏曾风靡一时。
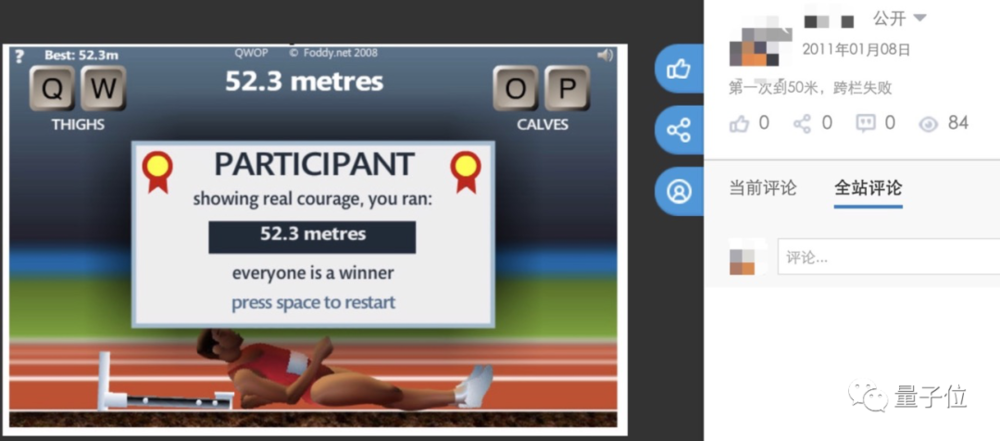
它的名字简单粗暴——QWOP。意思是让玩家用这四个键位控制游戏人物的左右大腿和小腿,以最快的速度跑完100米。

实际上,大部分玩家刚上手的时候,可能连起点线都迈不过去就Game Over了。

如果你能跑出几米远,绝对算是一个高手,甚至能在朋友面前炫耀一番。

QWOP的难点在于,一旦角色失去平衡就很难再挽回,需要在100米的距离内一直保持重心不过于向前后倾斜。
当你经过苦练第一次跑起来时,又会被50米处作者故意设置的栏杆摆一道:说好的100米短跑怎么变跨栏了?
看到这款“沙雕游戏”,你是不是会想到强化学习来训练双足机器人的画面?

一位来自波士顿咨询的数据分析师Wesley Liao也是这么想的。
不过别以为“变态”难度的游戏到了AI面前就变成了毛毛雨。
Liao综合了之前多种强化学习算法,最后甚至请来了“世界名师”教学,费了好大一番功夫,才终于让AI在上周打破人类玩家的记录。
可见这款游戏的难度一点都不比围棋低啊。
小试牛刀
一开始,Liao使用OpenAI Gym强化学习环境来训练AI,先设定好游戏的状态、操作和奖惩机制。
状态包括每个身体部位和关节的位置、速度和角度。操作方式限定为11种:4个QWOP按键、6种两两按键组合以及不按任何键。
用来训练AI的算法是ACER(具有经验回放能力的Actor-Critic)。这种算法的优点是,不仅可以从其最近获得的经验中学习,也可以学习存储数据中更早的经验。
由于ACER非常复杂,Liao使用了别人的实现代码“Stable Baselines”。
Liao首先尝试了让AI自己学习。经过多次实验后,他发现AI只学会了“蹭膝盖”这种方式跑过终点,速度很慢。

这和许多人类普通玩家以及其他强化学习算法是一样的,离高手的水平还差很远,更不用谈打破纪录了。
仔细分析可以发现,AI根本没有学习到跨步机制,只是学习到了最安全、最慢的方法来到达终点。
看来靠AI完全自学是不行了。
学会奔跑
类似于DeepMind用顶级棋手教AlphaGo下棋,Liao想到是不是也可以让人类玩家来教一下AI。
但是Liao本人的技术和顶级玩家差距太大,自己最多也只能跑到28米。
这都不重要,重要的是起码Liao跨出更大步伐的技巧,只能寄希望于AI能从“渣技术”里学到一点奔跑的技巧吧。
但是结果很不幸,AI很好地诠释了“邯郸学步”:不仅没掌握跑步技巧,反而在起点就跌倒了。

然后Liao让AI自己继续训练。所谓师父领进门,修行在个人,AI能否将人类技术和自学能力结合起来?
结果令人兴奋,经过90个小时的训练,AI终于学会了像人一样奔跑!

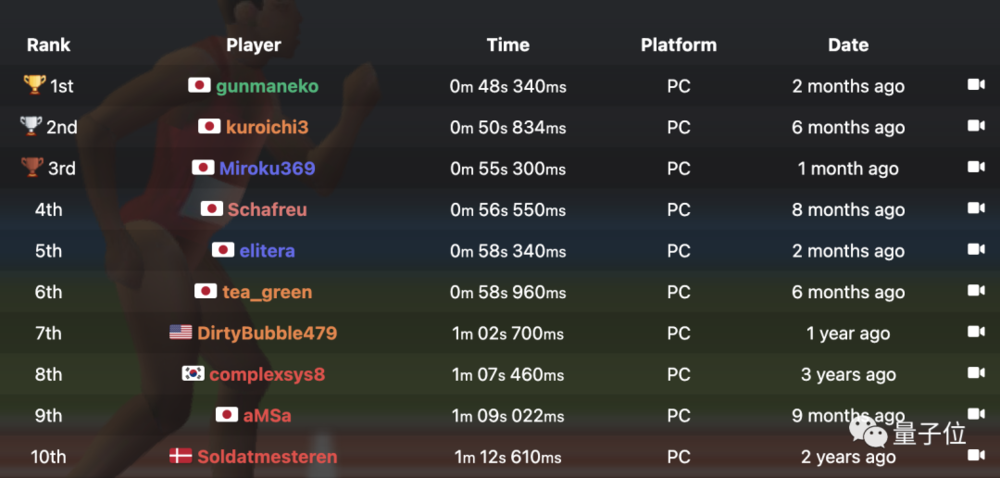
最终成绩是1分25秒,已经能跑进全球排行榜的前15名,离超过人类不远了。
接下来要做的就是再向AI教授更多技巧,奈何本人技术太渣。所以要想进一步提高AI的水平,必须找顶级高手来帮忙。
顶级高手助阵
Liao观察速通排行榜上的录像,发现顶级玩家的技巧是把左腿抬高可以跑的更快。

他开始全球排名前二的玩家gunmaneko和Kurodo请教踢腿技巧的操作。
两位玩家热情地回答了他的问题。其中Kurodo指出这个技巧的关键在于减少游戏角色在纵向的移动,并提出把保持身体高度加入AI的奖励函数。
Liao向Kurodo分享了他的代码,Kurodo慷慨地使用代码记录了50次自己游戏时的按键记录发给Liao。
Liao尝试使用这些数据对AI进行预训练,但效果并不好。AI还没来得及学会踢腿技巧,倒先把基本的跑步方法忘记了。

Liao不得不改变方法,他把Kurodo的数据注入到AI的回放缓存*(Replay Buffer)*中。这相当于修改AI的记忆,使AI有一半的记忆是自己的,另一半来自Kurodo。
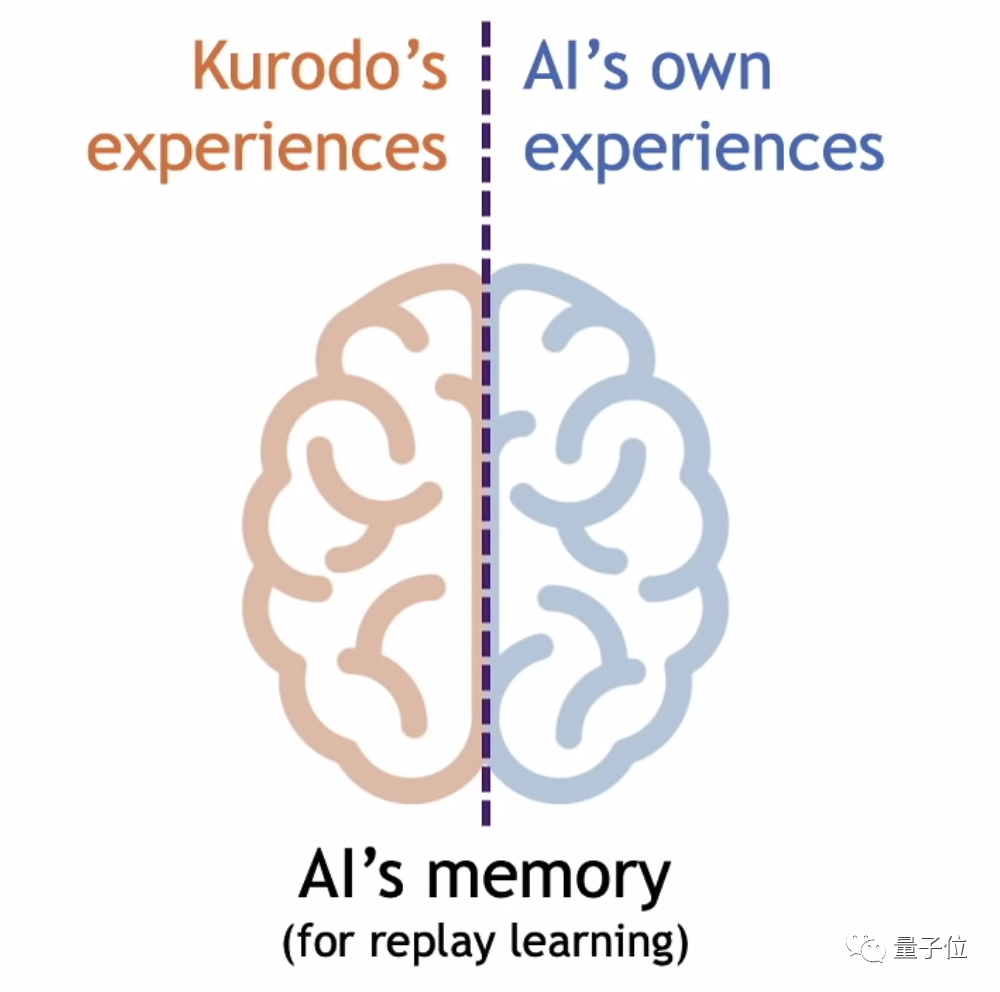
并且是AI每自己玩一次,就注入一次Kurodo的数据,保证AI随机从记忆中选取一段来学习时选到两种记忆的概率相同,避免在学习新技巧的过程中把基本操作忘掉。
AI使用Kurodo的数据训练了15个小时,终于学会了踢腿,但因为两种记忆无法协调在一起,跑时间长了动作会不稳定。
Liao此时把Kurodo的记忆移除,又让AI自己训练了25小时,总训练时间达到了65小时。
最终AI的成绩达到1分08秒,终于进入前十。
打破世界纪录
Liao把教AI玩这个游戏的过程做成视频发在网上。一个月前,外媒Gismodo问他:为什么AI还没有打破世界纪录?

于是Liao重新训练了一个只为优化速度而存在的新AI。
新AI改用Prioritized DDQN算法,因为这种算法会给学习效率更高的状态增加权重而不是均匀采样,能使新AI迅速学会旧AI已经掌握了的技巧。
并且,新AI的奖励函数去掉了身体高度,膝盖弯曲角度等参数,改成只和前进速度相关。
新AI先用已有数据进行只有几分钟的预训练,随后是40小时的自训练。最终,新AI每秒所做的动作数在训练环境中由9提高到18,并在测试环境中达到25。
新AI对踢腿技巧的掌握非常稳定,即使被障碍物影响也能迅速恢复。

快速高效的动作使AI的成绩提高到47.34秒,比人类最高纪录48.34秒刚好快1秒。

这才终于算是,在人工智能超越人类的游戏列表中又增加了一项。
One More Thing
你以为这就完了?
跑完100米不算完,这款游戏还有一种世界级难度——“是男人就跑完马拉松”。
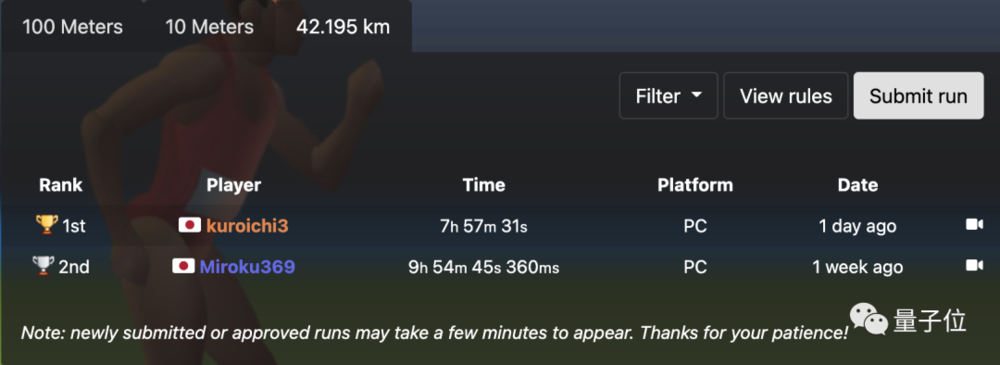
为Liao提供帮助的玩家Kurodo最近刚刚提交了世界纪录,全球也只有两人完成了这项壮举。
很难想象他们在电脑前连续按几个小时QWOP的画面。
另外,QWOP的开发者Bennett Foddy一直在坚持开发这类“变态”难度的独立小游戏。

有一款Getting Over It with Bennett Foddy名气颇高,中文名“掘地求升”。玩法就是一个装在坛子里的人不停用锤子让自己升高。

Foddy曾经在普林斯顿大学和牛津大学担任博士后研究员,现在是一名独立游戏设计师。QWOP就是他在普林斯顿大学时期开发的。
我只能说,学霸开发的游戏,学渣真的玩不起。
QWOP在线游戏地址:http://www.foddy.net/Athletics.html
参考链接:
[1] https://github.com/Wesleyliao/QWOPRL
[2] https://www.speedrun.com/qwop
[3] https://gizmodo.com/an-ai-was-taught-to-play-the-worlds-hardest-video-game-1846388137
[4] https://towardsdatascience.com/achieving-human-level-performance-in-qwop-using-reinforcement-learning-and-imitation-learning-81b0a9bbac96
[5] https://www.youtube.com/watch?v=82sTpO_EpEc
[6] https://wesleyliao.com/